Come funziona il GPT Transformer: Spiegazione della Causal Self-Attention
Negli ultimi anni, i Generative Pre-trained Transformers (GPT) hanno rivoluzionato l’intelligenza artificiale. Dagli assistenti di programmazione agli agenti conversazionali, i modelli basati su GPT alimentano oggi le applicazioni generative più avanzate. Ma come funziona effettivamente questa tecnologia?
Mentre modelli come BERT utilizzano la parte Encoder del Transformer per comprendere il testo in modo bidirezionale, GPT è un’architettura Decoder-only progettata per la previsione autoregressiva del token successivo. In questo blog demistificheremo il funzionamento del GPT Transformer, approfondiremo il meccanismo di causal self-attention e lo implementeremo nel codice.
1. Il ciclo di generazione autoregressiva
Nel profondo, GPT is un modello autoregressivo. Ciò significa che per generare una sequenza di testo, prevede il token successivo uno alla volta, utilizzando i token già generati come contesto per la previsione successiva.
Il flusso di lavoro segue questi passaggi:
- Input: Il modello riceve un prompt:
"Deep learning is". - Previsione: Il modello elabora questo prompt e restituisce una distribuzione di probabilità su tutto il suo vocabolario. Seleziona il token successivo:
"awesome". - Ciclo: Il nuovo token viene aggiunto all’input, che diventa:
"Deep learning is awesome". Questa sequenza diventa l’input per il passaggio successivo. - Terminazione: Il processo si ripete finché il modello non emette uno speciale token End-of-Sequence (
[EOS]) o raggiunge un limite di lunghezza predefinito.
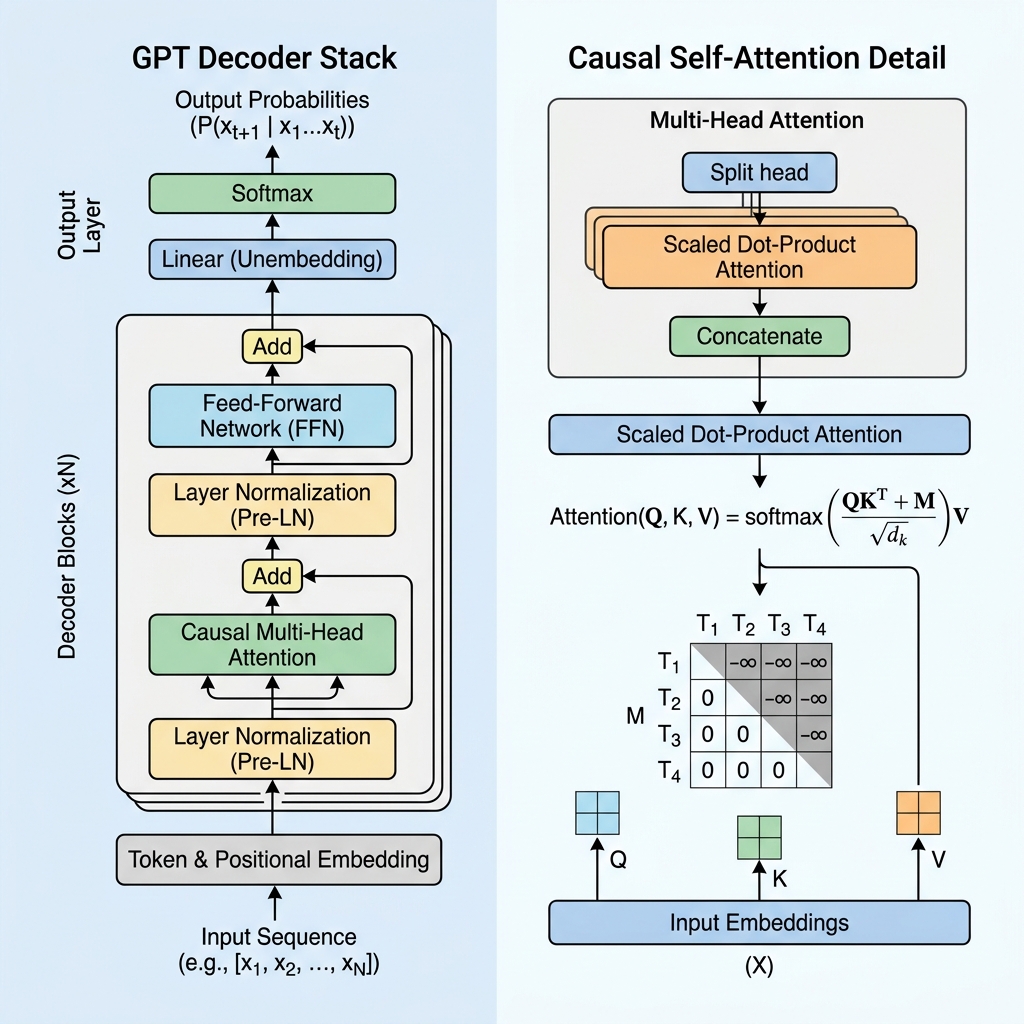
2. Mascheratura causale: il cuore del Decoder
In un modello basato solo sull’encoder come BERT, ogni token può prestare attenzione a ogni altro token, guardando sia al passato che al futuro. Tuttavia, per un modello generativo che deve prevedere il token successivo, guardare al futuro durante l’addestramento sarebbe come “barare”.
Per impedire al modello di guardare i token futuri, GPT utilizza la Causal Self-Attention (o mascherata).
La matrice della maschera causale
Durante il calcolo del self-attention, calcoliamo i punteggi di somiglianza tra i token prendendo il prodotto scalare tra Queries ($Q$) e Keys ($K$):
$$\text{Scores} = QK^T$$
Per imporre la causalità, applichiamo una matrice di maschera $M$ in cui tutti i valori al di sopra della diagonale sono impostati su $-\infty$ (infinito negativo) e i valori sulla diagonale e al di sotto sono 0. Aggiungiamo questa maschera ai punteggi prima di applicare la funzione softmax:
$$\text{Masked Scores} = \frac{QK^T}{\sqrt{d_k}} + M$$
$$M = \begin{pmatrix} 0 & -\infty & -\infty & \dots & -\infty \\ 0 & 0 & -\infty & \dots & -\infty \\ 0 & 0 & 0 & \dots & -\infty \\ \vdots & \vdots & \vdots & \ddots & \vdots \\ 0 & 0 & 0 & \dots & 0 \end{pmatrix}$$
Quando applichiamo la funzione softmax, $e^{-\infty}$ diventa $0$. Di conseguenza, i pesi di attenzione per qualsiasi token futuro diventano esattamente 0, rendendoli invisibili al token corrente.
3. Blocchi architetturali principali di un livello GPT
Un modello GPT è composto da livelli di decoder Transformer impilati. Ciascun livello contiene diversi componenti cruciali:
A. Embeddings di input e codifica posizionale
- Tokenizzazione: Il testo grezzo viene suddiviso in token sub-parola utilizzando la Byte-Pair Encoding (BPE).
- Token Embeddings: Ogni token è mappato su un vettore ad alta dimensione.
- Learned Positional Embeddings: Poiché il self-attention non ha un senso intrinseco dell’ordine, GPT aggiunge vettori di embedding posizionale appresi agli embedding dei token, consentendo al modello di conoscere la posizione di ciascun token nella sequenza.
B. Pre-Layer Normalization (Pre-LN)
A differenza dell’architettura Transformer originale, che applicava la Layer Normalization dopo l’aggiunta residua (Post-LN), le moderne architetture GPT applicano la Layer Normalization prima dei livelli di attenzione e feed-forward:
$$x_{l+1} = x_l + \text{Attention}(\text{LayerNorm}(x_l))$$
Pre-LN stabilizza i gradienti durante l’addestramento, consentendo l’addestramento stabile di reti molto profonde con centinaia di miliardi di parametri.
C. Feed-Forward Network (FFN)
Dopo il blocco di attenzione, la rappresentazione di ciascun token passa attraverso un perceptron multistrato (MLP) composto da due trasformazioni lineari e una funzione di attivazione (tipicamente GeLU):
$$\text{FFN}(x) = \max(0, x W_1 + b_1) W_2 + b_2$$
4. Meccanismi di campionamento (da Logit a Token)
L’ultimo blocco di decodifica emette un vettore di punteggi grezzi chiamati Logit per ciascuna posizione. Convertiamo questi logit in probabilità utilizzando la funzione softmax. Per controllare la casualità del testo generato, applichiamo dei parametri durante il campionamento:
- Temperatura ($T$): Scala i logit prima della softmax. Una temperatura più bassa (es. $T = 0.2$) rende il modello deterministico e concentrato, mentre una temperatura più alta (es. $T = 0.8$) aumenta la creatività e la diversità.
- Top-K: Limita le scelte del token successivo ai $K$ token più probabili.
- Top-P (Nucleus Sampling): Accumula la distribuzione di probabilità e sceglie dal blocco più piccolo di token la cui probabilità cumulativa supera $P$ (es. $P = 0.9$).
5. Implementazione PyTorch della Causal Self-Attention
Di seguito è riportata un’implementazione PyTorch autonoma che dimostra la causal self-attention con mascheratura causale:
import torch
import torch.nn as nn
import torch.nn.functional as F
class CausalSelfAttention(nn.Module):
def __init__(self, d_model, n_heads):
super().__init__()
assert d_model % n_heads == 0
self.d_model = d_model
self.n_heads = n_heads
self.d_k = d_model // n_heads
# Proiezioni per Query, Key e Value
self.q_proj = nn.Linear(d_model, d_model)
self.k_proj = nn.Linear(d_model, d_model)
self.v_proj = nn.Linear(d_model, d_model)
self.out_proj = nn.Linear(d_model, d_model)
def forward(self, x):
batch_size, seq_len, d_model = x.size()
# 1. Proietta gli input in Q, K, V
Q = self.q_proj(x).view(batch_size, seq_len, self.n_heads, self.d_k).transpose(1, 2)
K = self.k_proj(x).view(batch_size, seq_len, self.n_heads, self.d_k).transpose(1, 2)
V = self.v_proj(x).view(batch_size, seq_len, self.n_heads, self.d_k).transpose(1, 2)
# 2. Calcola i punteggi di attenzione grezzi
scores = torch.matmul(Q, K.transpose(-2, -1)) / (self.d_k ** 0.5)
# 3. Crea e applica la maschera causale
# Maschera triangolare superiore riempita con infinito negativo
mask = torch.triu(torch.ones(seq_len, seq_len, device=x.device), diagonal=1).bool()
scores = scores.masked_fill(mask, float('-inf'))
# 4. Softmax trasforma -inf in probabilità 0
attn_weights = F.softmax(scores, dim=-1)
# 5. Calcola la somma pesata dei valori e restituisce l'output
context = torch.matmul(attn_weights, V)
context = context.transpose(1, 2).contiguous().view(batch_size, seq_len, d_model)
return self.out_proj(context)
# Verifica rapida
if __name__ == "__main__":
# Batch size = 1, Lunghezza sequenza = 4, Dimensione modello = 8, 2 teste
x = torch.randn(1, 4, 8)
attention_layer = CausalSelfAttention(d_model=8, n_heads=2)
output = attention_layer(x)
print("Forma Input:", x.shape)
print("Forma Output:", output.shape)
6. Confronto Architetturale
| Caratteristica | BERT (solo Encoder) | GPT (solo Decoder) | Transformer Originale |
|---|---|---|---|
| Compito Principale | Comprensione / Estrazione | Generazione / Sintesi | Traduzione / Sequence-to-Sequence |
| Tipo di Attenzione | Self-Attention Bidirezionale | Self-Attention Causale Mascherata | Cross-Attention Bidirezionale e Causale |
| Mascheratura | Mascherati token ([MASK]) |
Mascheratura triangolare causale | Mascheratura causale nel decoder |
| Elaborazione | Elabora l’intera sequenza in una volta | Generazione autoregressiva dei token | L’encoder elabora una volta, il decoder genera |
Conclusione
Eliminando l’encoder e concentrandosi interamente sul self-attention causale mascherato, GPT ha aperto la strada al ridimensionamento generativo. La semplice regola di prevedere il token successivo, unita a un massiccio addestramento parallelo, consente ai modelli GPT di catturare ricche rappresentazioni di logica, programmazione e linguaggio, formando la base della moderna IA cognitiva.
Esplora altre prospettive tecnologiche sul Blog di Ghaznix →