Como funciona o GPT Transformer: Explicação da Autoatenção Causal
Como funciona o GPT Transformer: Explicação da Autoatenção Causal
Nos últimos anos, os Transformers Generativos Pré-treinados (GPT) revolucionaram a inteligência artificial. De assistentes de programação a agentes conversacionais, os modelos baseados em GPT alimentam as aplicações generativas mais avançadas da atualidade. Mas como essa tecnologia realmente funciona?
Enquanto modelos como o BERT usam a parte do Encoder (Codificador) do Transformer para compreender o texto de forma bidirecional, o GPT é uma arquitetura Decoder-only (apenas decodificador) projetada para a previsão autorregressiva do próximo token. Neste blog, vamos desmistificar como o GPT Transformer funciona, mergulhar no mecanismo de autoatenção causal e implementá-lo em código.
1. O Loop de Geração Autorregresiva
Em sua essência, o GPT is um modelo autorregresivo. Isso significa que, para gerar uma sequência de texto, ele prevê o próximo token um por um, usando os tokens que já gerou como contexto para a próxima previsão.
O fluxo de trabalho segue estes passos:
- Entrada (Input): O modelo recebe uma instrução (prompt):
"Deep learning is". - Previsão: O modelo processa esse prompt e gera uma distribuição de probabilidade sobre todo o seu vocabulário. Ele seleciona o próximo token:
"awesome". - Loop: O novo token é anexado à entrada, tornando-a:
"Deep learning is awesome". Essa sequência se torna a entrada para a próxima etapa. - Terminação: O processo se repete até que o modelo gere um token especial de fim de sequência (
[EOS]) ou atinja um limite de comprimento predefinido.
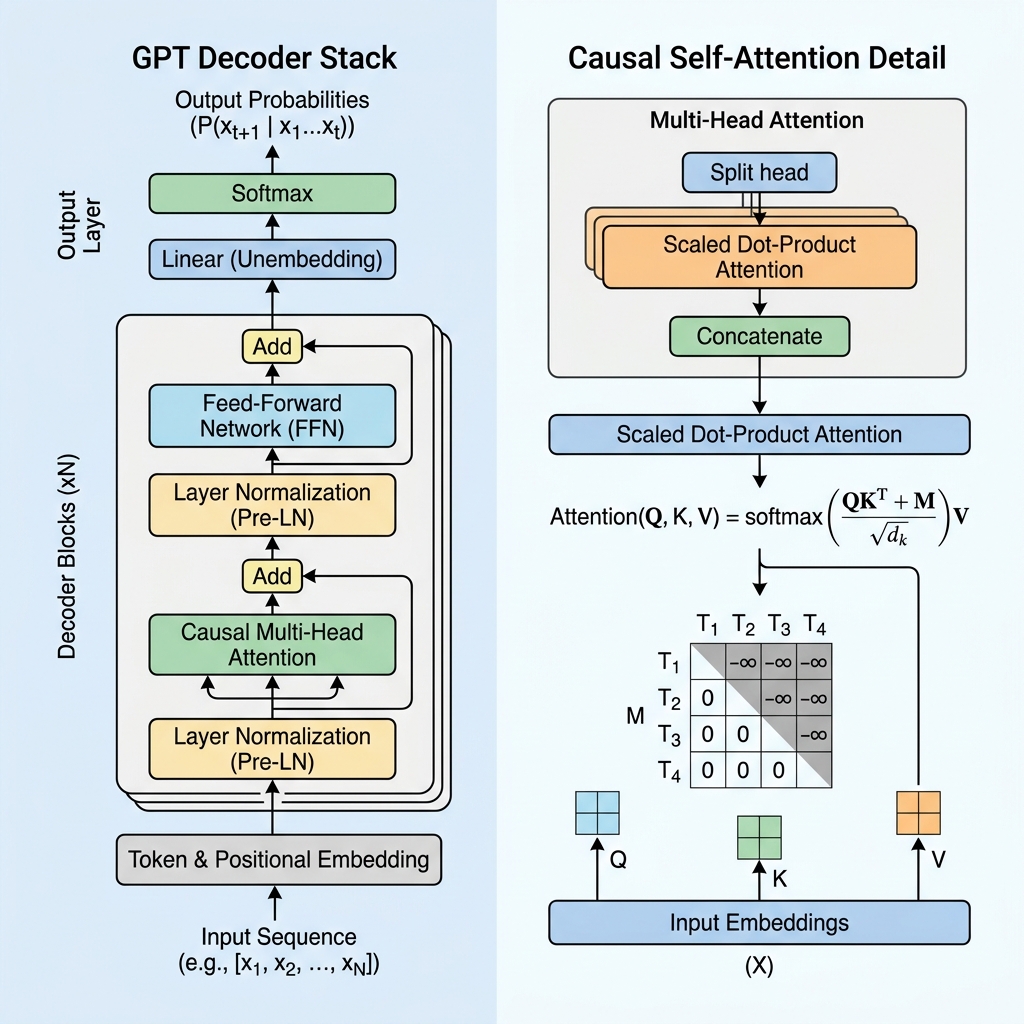
2. Mascaramento Causal: O Coração do Decodificador
Em um modelo baseado apenas no codificador, como o BERT, cada token pode prestar atenção a qualquer outro token, olhando tanto para o passado quanto para o futuro. No entanto, para um modelo generativo que prevê o próximo token, olhar para o futuro durante o treinamento seria “trapaça”.
Para evitar que o modelo olhe para tokens futuros, o GPT usa a Autoatenção Causal (ou autoatenção mascarada).
A Matriz de Máscara Causal
Durante o cálculo da autoatenção, calculamos as pontuações de similaridade entre tokens fazendo o produto escalar das consultas (Queries, $Q$) e das chaves (Keys, $K$):
$$\text{Scores} = QK^T$$
Para impor a causalidade, aplicamos uma matriz de máscara $M$ onde todos os valores acima da diagonal são definidos como $-\infty$ (infinito negativo), e os valores sobre e abaixo da diagonal são 0. Adicionamos essa máscara às pontuações antes de aplicar a função softmax:
$$\text{Masked Scores} = \frac{QK^T}{\sqrt{d_k}} + M$$
$$M = \begin{pmatrix} 0 & -\infty & -\infty & \dots & -\infty \\ 0 & 0 & -\infty & \dots & -\infty \\ 0 & 0 & 0 & \dots & -\infty \\ \vdots & \vdots & \vdots & \ddots & \vdots \\ 0 & 0 & 0 & \dots & 0 \end{pmatrix}$$
Quando aplicamos a função softmax, $e^{-\infty}$ torna-se $0$. Consequentemente, os pesos de atenção para quaisquer tokens futuros tornam-se exatamente 0, tornando os tokens futuros invisíveis para o token atual.
3. Blocos Arquitetônicos Principais de uma Camada GPT
Um modelo GPT consiste em camadas de decodificador Transformer empilhadas. Cada camada contém vários componentes cruciais:
A. Embeddings de Entrada e Codificação Posicional
- Tokenização: O texto bruto é dividido em tokens de subpalavras usando a codificação de pares de bytes (BPE).
- Token Embeddings: Cada token é mapeado para um vetor de alta dimensão.
- Learned Positional Embeddings: Como a autoatenção não possui um sentido de ordem inerente, o GPT adiciona vetores de embeddings posicionais aprendidos aos embeddings de tokens, permitindo que o modelo saiba a posição de cada token na sequência.
B. Normalização Pré-Camada (Pre-LN)
Ao contrário da arquitetura original do Transformer, que aplicava a normalização de camada após a adição residual (Post-LN), as arquiteturas GPT modernas aplicam a normalização de camada antes das camadas de atenção e de alimentação para frente (feed-forward):
$$x_{l+1} = x_l + \text{Attention}(\text{LayerNorm}(x_l))$$
A Pre-LN estabiliza os gradientes durante o treinamento, permitindo o treinamento estável de redes muito profundas com centenas de bilhões de parâmetros.
C. Rede de Alimentação para Frente (Feed-Forward Network / FFN)
Seguindo o bloco de atenção, a representação de cada token passa por um perceptron multicamadas (MLP) que consiste em duas transformações lineares e uma função de ativação (normalmente GeLU):
$$\text{FFN}(x) = \max(0, x W_1 + b_1) W_2 + b_2$$
4. A Mecânica de Amostragem (de Logits a Tokens)
O bloco decodificador final gera um vetor de pontuações brutas chamadas Logits para cada posição. Convertemos esses logits em probabilidades usando a função softmax. Para controlar a aleatoriedade do texto gerado, aplicamos parâmetros durante a amostragem:
- Temperatura ($T$): Escala os logits antes da softmax. Uma temperatura mais baixa (por exemplo, $T = 0.2$) torna o modelo determinista e focado, enquanto uma temperatura mais alta (por exemplo, $T = 0.8$) aumenta a criatividade e a diversidade.
- Top-K: Limita as escolhas do próximo token aos $K$ tokens mais prováveis.
- Top-P (Amostragem de Núcleo / Nucleus Sampling): Acumula a distribuição de probabilidade e escolhe a partir do menor conjunto de tokens cuja probabilidade cumulativa excede $P$ (por exemplo, $P = 0.9$).
5. Implementação em PyTorch de Autoatenção Causal
Abaixo está uma implementação PyTorch independente que demonstra a autoatenção causal com mascaramento causal:
import torch
import torch.nn as nn
import torch.nn.functional as F
class CausalSelfAttention(nn.Module):
def __init__(self, d_model, n_heads):
super().__init__()
assert d_model % n_heads == 0
self.d_model = d_model
self.n_heads = n_heads
self.d_k = d_model // n_heads
# Projeções para Query, Key e Value
self.q_proj = nn.Linear(d_model, d_model)
self.k_proj = nn.Linear(d_model, d_model)
self.v_proj = nn.Linear(d_model, d_model)
self.out_proj = nn.Linear(d_model, d_model)
def forward(self, x):
batch_size, seq_len, d_model = x.size()
# 1. Projetar entradas para Q, K, V
Q = self.q_proj(x).view(batch_size, seq_len, self.n_heads, self.d_k).transpose(1, 2)
K = self.k_proj(x).view(batch_size, seq_len, self.n_heads, self.d_k).transpose(1, 2)
V = self.v_proj(x).view(batch_size, seq_len, self.n_heads, self.d_k).transpose(1, 2)
# 2. Calcular pontuações de atenção brutas
scores = torch.matmul(Q, K.transpose(-2, -1)) / (self.d_k ** 0.5)
# 3. Criar e aplicar máscara causal
# Máscara triangular superior preenchida com infinito negativo
mask = torch.triu(torch.ones(seq_len, seq_len, device=x.device), diagonal=1).bool()
scores = scores.masked_fill(mask, float('-inf'))
# 4. Softmax converte -inf em probabilidade 0
attn_weights = F.softmax(scores, dim=-1)
# 5. Calcular soma ponderada de valores e saída
context = torch.matmul(attn_weights, V)
context = context.transpose(1, 2).contiguous().view(batch_size, seq_len, d_model)
return self.out_proj(context)
# Execução de verificação rápida
if __name__ == "__main__":
# Tamanho do lote = 1, Comprimento da sequência = 4, Dimensão do modelo = 8, 2 cabeças
x = torch.randn(1, 4, 8)
attention_layer = CausalSelfAttention(d_model=8, n_heads=2)
output = attention_layer(x)
print("Formato de Entrada:", x.shape)
print("Formato de Saída:", output.shape)
6. Comparação Arquitetônica
| Característica | BERT (apenas Codificador) | GPT (apenas Decodificador) | Transformer Original |
|---|---|---|---|
| Tarefa Principal | Compreensão / Extração | Geração / Síntese | Tradução / Sequência para Sequência |
| Tipo de Atenção | Autoatenção Bidirecional | Autoatenção Causal Mascarada | Atenções Cruzadas Bidirecionais e Causais |
| Mascaramento | Tokens mascarados ([MASK]) |
Mascaramento triangular causal | Mascaramento causal no decodificador |
| Processamento | Processa toda a sequência de uma vez | Geração autorregresiva de tokens | O codificador processa uma vez, o decodificador gera |
Conclusão
Ao descartar o codificador e focar inteiramente na autoatenção mascarada causal, o GPT abriu o caminho para a escala generativa. A regra simples de prever o próximo token, combinada com o treinamento em paralelo massivo, permite que os modelos GPT capturem ricas representações lógicas, de programação e de linguagem, formando a base da inteligência artificial cognitiva moderna.