Как работает GPT Transformer: Объяснение каузального самовнимания
За последние годы модели GPT (Generative Pre-trained Transformer) произвели революцию в области искусственного интеллекта. От помощников по написанию кода до диалоговых систем — модели на базе GPT лежат в основе самых передовых генеративных приложений сегодняшнего дня. Но как устроена эта технология на самом деле?
В то время как модели вроде BERT используют часть Encoder (кодировщик) архитектуры Transformer для двунаправленного понимания текста, GPT представляет собой архитектуру Decoder-only (только декодировщик), спроектированную для авторегрессионного прогнозирования следующего токена. В этой статье мы разберем принцип работы GPT Transformer, детально изучим механизм каузального самовнимания (causal self-attention) и реализуем его в коде.
1. Авторегрессионный цикл генерации
По своей сути GPT является авторегрессионной моделью. Это означает, что для генерации текстовой последовательности он предсказывает следующий токен по очереди, один за другим, используя уже сгенерированные токены в качестве контекста для следующего прогноза.
Процесс генерации состоит из следующих этапов:
- Входные данные: Модель получает начальный запрос (промпт):
"Deep learning is". - Прогнозирование: Модель обрабатывает этот промпт и выдает распределение вероятностей по всему своему словарю. Затем выбирается следующий токен:
"awesome". - Цикл: Новый токен добавляется в конец входной строки, преобразуя ее в:
"Deep learning is awesome". Полученная последовательность становится входными данными для следующего шага. - Завершение: Процесс повторяется до тех пор, пока модель не выдаст специальный токен завершения последовательности (
[EOS]) или не достигнет заданного ограничения по длине.
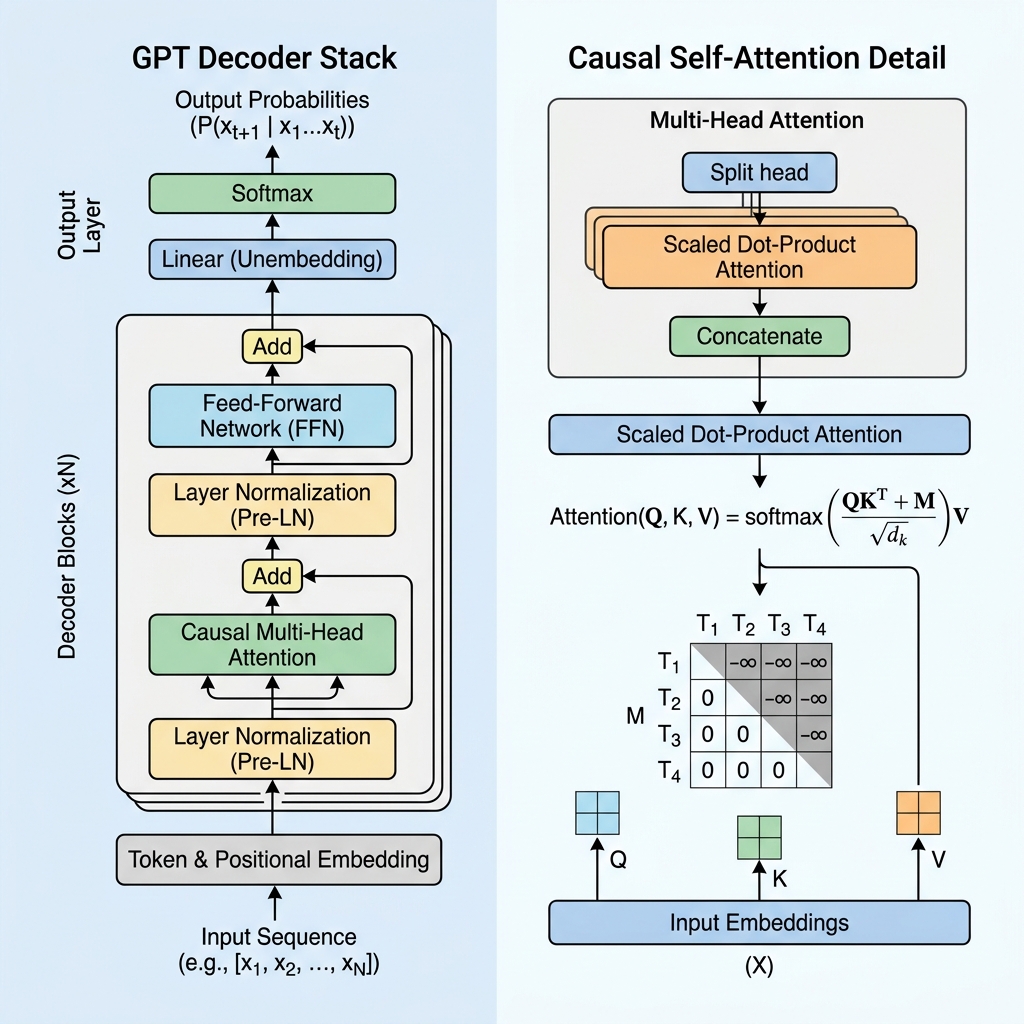
2. Каузальная маскировка: Сердце декодировщика
В моделях, состоящих только из кодировщика (таких как BERT), каждый токен может связываться со всеми остальными токенами, заглядывая как в прошлое, так и в будущее. Однако для генеративной модели, предсказывающей следующий токен, заглядывать в будущее во время обучения было бы «жульничеством».
Чтобы запретить модели видеть будущие токены, GPT использует каузальное самовнимание (Causal Self-Attention), или маскированное самовнимание.
Матрица каузальной маски
В ходе расчета самовнимания мы вычисляем оценки сходства между токенами, получая скалярное произведение запросов (Queries, $Q$) и ключей (Keys, $K$):
$$\text{Scores} = QK^T$$
Чтобы обеспечить каузальность, мы применяем матрицу маски $M$, в которой все значения выше диагонали устанавливаются в $-\infty$ (минус бесконечность), а значения на диагонали и ниже равны 0. Мы прибавляем эту маску к полученным оценкам перед применением функции softmax:
$$\text{Masked Scores} = \frac{QK^T}{\sqrt{d_k}} + M$$
$$M = \begin{pmatrix} 0 & -\infty & -\infty & \dots & -\infty \\ 0 & 0 & -\infty & \dots & -\infty \\ 0 & 0 & 0 & \dots & -\infty \\ \vdots & \vdots & \vdots & \ddots & \vdots \\ 0 & 0 & 0 & \dots & 0 \end{pmatrix}$$
Когда мы применяем функцию softmax, значение $e^{-\infty}$ превращается в $0$. Следовательно, веса внимания для любых будущих токенов становятся равными ровно 0, делая их невидимыми для текущего токена.
3. Основные блоки архитектуры слоя GPT
Модель GPT состоит из последовательно соединенных слоев декодировщика Transformer. Каждый слой включает в себя несколько важнейших компонентов:
А. Входные эмбеддинги и позиционное кодирование
- Токенизация: Исходный текст разбивается на токены (части слов) с помощью алгоритма Byte-Pair Encoding (BPE).
- Векторное представление токенов: Каждый токен сопоставляется с многомерным вектором (эмбеддингом).
- Обучаемые позиционные эмбеддинги: Поскольку самовнимание изначально не учитывает порядок слов, GPT добавляет к эмбеддингам токенов обучаемые позиционные векторы, позволяющие модели понимать положение каждого токена в последовательности.
Б. Предварительная нормализация слоев (Pre-LN)
В отличие от оригинальной архитектуры Transformer, где нормализация слоя применялась после добавления остаточной связи (Post-LN), современные архитектуры GPT применяют нормализацию перед слоями внимания и прямого распространения:
$$x_{l+1} = x_l + \text{Attention}(\text{LayerNorm}(x_l))$$
Pre-LN стабилизирует градиенты во время обучения, делая возможным стабильное обучение очень глубоких сетей с сотнями миллиардов параметров.
В. Сеть прямого распространения (Feed-Forward Network / FFN)
После блока внимания векторное представление каждого токена проходит через многослойный перцептрон (MLP), состоящий из двух линейных преобразований и функции активации (обычно GeLU):
$$\text{FFN}(x) = \max(0, x W_1 + b_1) W_2 + b_2$$
4. Механика сэмплирования (от логитов к токенам)
Финальный блок декодировщика выводит вектор необработанных оценок (называемых логитами) для каждой позиции. Мы преобразуем эти логиты в вероятности с помощью функции softmax. Для управления случайностью генерируемого текста при сэмплировании используются следующие параметры:
- Температура ($T$): Масштабирует логиты перед применением softmax. Низкая температура (например, $T = 0.2$) делает ответы модели более детерминированными и сфокусированными, в то время как высокая температура (например, $T = 0.8$) повышает креативность и разнообразие ответов.
- Top-K: Ограничивает выбор следующего токена подмножеством из $K$ наиболее вероятных токенов.
- Top-P (Nucleus Sampling): Накапливает распределение вероятностей и выбирает токены из наименьшего набора, чья кумулятивная вероятность превышает значение $P$ (например, $P = 0.9$).
5. Реализация каузального самовнимания на PyTorch
Ниже представлен автономный код на PyTorch, демонстрирующий каузальное самовнимание с маскировкой:
import torch
import torch.nn as nn
import torch.nn.functional as F
class CausalSelfAttention(nn.Module):
def __init__(self, d_model, n_heads):
super().__init__()
assert d_model % n_heads == 0
self.d_model = d_model
self.n_heads = n_heads
self.d_k = d_model // n_heads
# Проекции для Query, Key и Value
self.q_proj = nn.Linear(d_model, d_model)
self.k_proj = nn.Linear(d_model, d_model)
self.v_proj = nn.Linear(d_model, d_model)
self.out_proj = nn.Linear(d_model, d_model)
def forward(self, x):
batch_size, seq_len, d_model = x.size()
# 1. Проецируем входные данные в матрицы Q, K, V
Q = self.q_proj(x).view(batch_size, seq_len, self.n_heads, self.d_k).transpose(1, 2)
K = self.k_proj(x).view(batch_size, seq_len, self.n_heads, self.d_k).transpose(1, 2)
V = self.v_proj(x).view(batch_size, seq_len, self.n_heads, self.d_k).transpose(1, 2)
# 2. Вычисляем необработанные оценки внимания
scores = torch.matmul(Q, K.transpose(-2, -1)) / (self.d_k ** 0.5)
# 3. Создаем и применяем каузальную маску
# Верхнетреугольная маска, заполненная минус бесконечностью
mask = torch.triu(torch.ones(seq_len, seq_len, device=x.device), diagonal=1).bool()
scores = scores.masked_fill(mask, float('-inf'))
# 4. Softmax превращает -inf в нулевую вероятность
attn_weights = F.softmax(scores, dim=-1)
# 5. Вычисляем взвешенную сумму значений и возвращаем результат
context = torch.matmul(attn_weights, V)
context = context.transpose(1, 2).contiguous().view(batch_size, seq_len, d_model)
return self.out_proj(context)
# Быстрая проверка работоспособности
if __name__ == "__main__":
# Размер пакета = 1, Длина последовательности = 4, Размерность модели = 8, Число головок = 2
x = torch.randn(1, 4, 8)
attention_layer = CausalSelfAttention(d_model=8, n_heads=2)
output = attention_layer(x)
print("Входная размерность:", x.shape)
print("Выходная размерность:", output.shape)
6. Сравнение архитектур
| Характеристика | BERT (только кодировщик) | GPT (только декодировщик) | Оригинальный Transformer |
|---|---|---|---|
| Основная задача | Понимание / Извлечение данных | Генерация / Синтез | Перевод / Последовательность в последовательность |
| Тип внимания | Двунаправленное самовнимание | Каузальное маскированное самовнимание | Двунаправленное и каузальное перекрестное внимание |
| Маскирование | Маскируемые токены ([MASK]) |
Каузальная треугольная маска | Каузальная маска в декодировщике |
| Процесс обработки | Обрабатывает всю последовательность сразу | Авторегрессионная генерация токенов | Кодировщик обрабатывает один раз, декодировщик генерирует |
Заключение
Отказавшись от кодировщика и полностью сфокусировавшись на каузальном маскированном самовнимании, архитектура GPT проложила путь к масштабированию генеративных моделей. Простое правило предсказания следующего токена в сочетании с массовым параллельным обучением позволяет моделям GPT улавливать сложнейшие логические, языковые и программные структуры, формируя фундамент современного когнитивного ИИ.