GPT Transformer Nasıl Çalışır: Nedensel Self-Attention Açıklaması
GPT Transformer Nasıl Çalışır: Nedensel Self-Attention Açıklaması
Son yıllarda, Üretken Önceden Eğitilmiş Transformerlar (GPT), yapay zekayı kökten değiştirdi. Kodlama yardımcılarından sohbet robotlarına kadar, GPT tabanlı modeller günümüzün en gelişmiş üretken uygulamalarına güç veriyor. Peki bu teknoloji gerçekte nasıl çalışıyor?
BERT gibi modeller, metni çift yönlü olarak anlamak için Transformer’ın Encoder (Kodlayıcı) bölümünü kullanırken; GPT, otoregresif, bir sonraki token tahmini için tasarlanmış bir Decoder-only (Sadece Kod Çözücü) mimaridir. Bu blogda, GPT Transformer’ın nasıl çalıştığını aydınlatacak, nedensel self-attention (causal self-attention) mekanizmasını derinlemesine inceleyecek ve bunu kodda uygulayacağız.
1. Otoregresif Üretim Döngüsü
Temelinde GPT, otoregresif bir modeldir. Bu, bir metin dizisi oluşturmak için, daha önce ürettiği tokenları bir sonraki tahmin için bağlam (context) olarak kullanarak sonraki tokenı tek tek tahmin ettiği anlamına gelir.
İş akışı şu adımları izler:
- Girdi (Input): Model bir yönlendirme (prompt) alır:
"Deep learning is". - Tahmin (Prediction): Model bu yönlendirmeyi işler ve tüm kelime dağarcığı üzerinden bir olasılık dağılımı çıktısı verir. Bir sonraki tokenı seçer (örnekler):
"awesome". - Döngü (Loop): Yeni token girdinin sonuna eklenir ve girdi şu hale gelir:
"Deep learning is awesome". Bu yeni dizi, bir sonraki adımın girdisi olur. - Sonlandırma (Termination): Süreç, model özel bir Dizi Sonu (
[EOS]) tokenı üretene kadar veya önceden tanımlanmış bir uzunluk sınırına ulaşana kadar tekrarlanır.
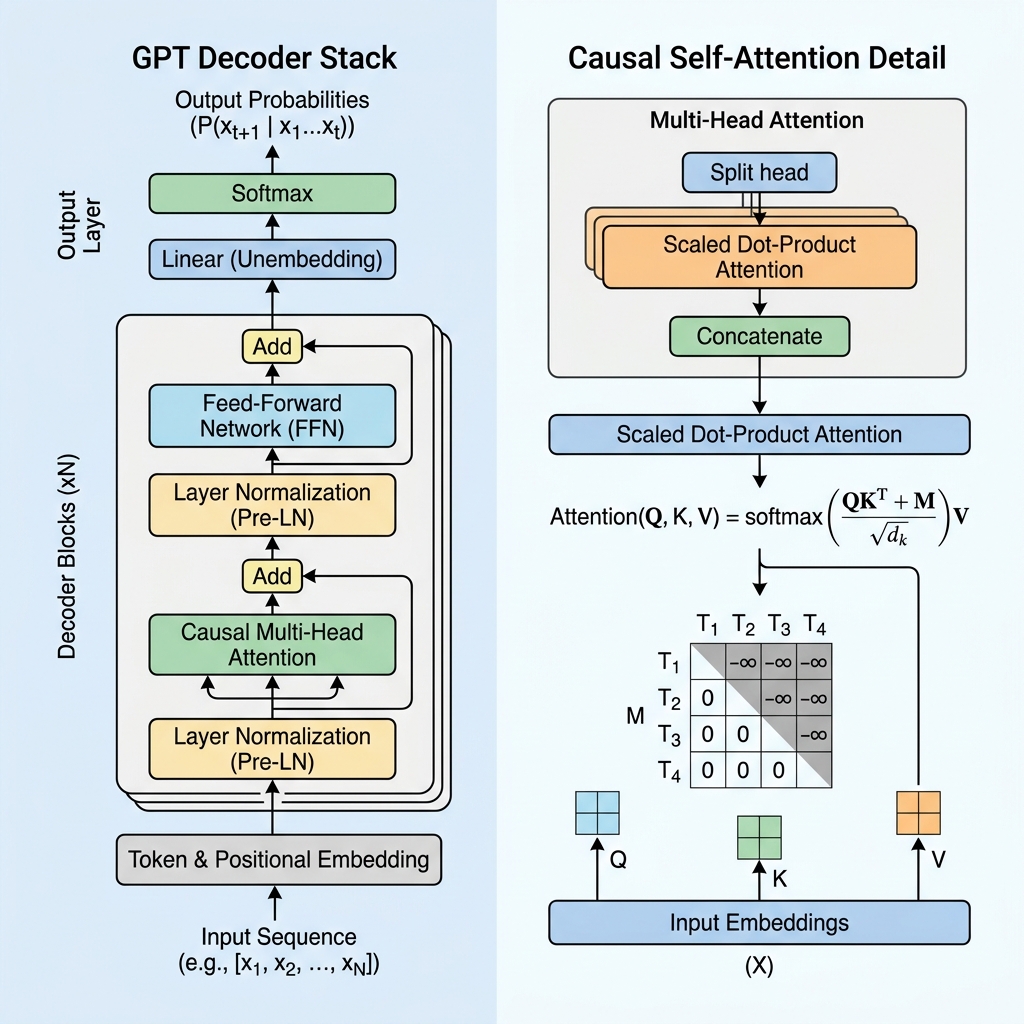
2. Nedensel Maskeleme: Kod Çözücünün Kalbi
BERT gibi sadece kodlayıcı içeren bir modelde, her token geçmişe ve geleceğe bakarak diğer tüm tokenlara dikkat edebilir. Ancak, bir sonraki tokenı tahmin eden üretken bir model için eğitim sırasında geleceğe bakmak “kopya çekmek” olurdu.
Modelin gelecekteki tokenlara bakmasını önlemek için GPT, Nedensel Self-Attention (veya Maskelenmiş Self-Attention) kullanır.
Nedensel Maske Matrisi
Self-attention hesaplaması sırasında, Sorguların (Queries, $Q$) ve Anahtarların (Keys, $K$) nokta çarpımını alarak tokenlar arasındaki benzerlik skorlarını hesaplarız:
$$\text{Scores} = QK^T$$
Nedenselliği zorunlu kılmak için, köşegenin üzerindeki tüm değerlerin $-\infty$ (eksi sonsuz) olarak ayarlandığı ve köşegen üzerindeki ve altındaki değerlerin 0 olduğu bir maske matrisi $M$ uygularız. Softmax işlevini uygulamadan önce bu maskeyi skorlara ekleriz:
$$\text{Masked Scores} = \frac{QK^T}{\sqrt{d_k}} + M$$
$$M = \begin{pmatrix} 0 & -\infty & -\infty & \dots & -\infty \\ 0 & 0 & -\infty & \dots & -\infty \\ 0 & 0 & 0 & \dots & -\infty \\ \vdots & \vdots & \vdots & \ddots & \vdots \\ 0 & 0 & 0 & \dots & 0 \end{pmatrix}$$
Softmax işlevini uyguladığımızda $e^{-\infty}$ değeri $0$ olur. Sonuç olarak, gelecekteki tüm tokenlar için dikkat ağırlıkları tam olarak 0 olur ve gelecekteki tokenlar mevcut token için görünmez hale gelir.
3. Bir GPT Katmanının Temel Mimari Blokları
Bir GPT modeli, üst üste yığılmış Transformer kod çözücü katmanlarından oluşur. Her katman birkaç kritik bileşen içerir:
A. Girdi Gömme ve Konumsal Kodlama (Embeddings & Positional Encoding)
- Tokenizasyon: Ham metin, Byte-Pair Encoding (BPE) kullanılarak alt kelime tokenlarına bölünür.
- Token Gömmeleri (Token Embeddings): Her token yüksek boyutlu bir vektörle eşleştirilir.
- Öğrenilmiş Konumsal Gömmeler: Self-attention mekanizmasının doğasında bir sıra algısı olmadığından GPT, token gömmelerine öğrenilmiş konumsal gömme vektörleri ekler; bu da modelin dizideki her tokenın konumunu bilmesini sağlar.
B. Ön Katman Normalizasyonu (Pre-Layer Normalization / Pre-LN)
Artık bağlantı eklemesinden sonra Layer Normalization uygulayan orijinal Transformer mimarisinin aksine (Post-LN), modern GPT mimarileri katman normalizasyonunu attention ve feed-forward katmanlarından önce uygular:
$$x_{l+1} = x_l + \text{Attention}(\text{LayerNorm}(x_l))$$
Pre-LN, eğitim sırasında gradyanları stabilize ederek yüz milyarlarca parametreye sahip çok derin ağların kararlı bir şekilde eğitilmesini sağlar.
C. İleri Beslemeli Ağ (Feed-Forward Network / FFN)
Dikkat bloğunun ardından, her tokenın temsili, iki doğrusal dönüşüm ve bir aktivasyon işlevinden (genellikle GeLU) oluşan çok katmanlı bir algılayıcıdan (MLP) geçer:
$$\text{FFN}(x) = \max(0, x W_1 + b_1) W_2 + b_2$$
4. Örnekleme Mekaniği (Logit’lerden Token’lara)
Son kod çözücü bloğu, her konum için Logit adı verilen ham skorlardan oluşan bir vektör çıktısı verir. Softmax işlevini kullanarak bu logitleri olasılıklara dönüştürürüz. Üretilen metnin rastgeleliğini kontrol etmek için örnekleme sırasında parametreler uygularız:
- Sıcaklık ($T$): Softmax’tan önce logitleri ölçeklendirir. Daha düşük bir sıcaklık (örneğin $T = 0.2$) modeli daha deterministik ve odaklanmış hale getirirken, daha yüksek bir sıcaklık (örneğin $T = 0.8$) yaratıcılığı ve çeşitliliği artırır.
- Top-K: Bir sonraki token seçeneklerini en olası $K$ token ile sınırlar.
- Top-P (Çekirdek Örnekleme / Nucleus Sampling): Olasılık dağılımını biriktirir ve kümülatif olasılığı $P$‘yi (örneğin $P = 0.9$) aşan en küçük token kümesinden seçim yapar.
5. PyTorch ile Nedensel Self-Attention Uygulaması
Aşağıda, nedensel maskeleme ile nedensel self-attention mekanizmasını gösteren bağımsız bir PyTorch uygulaması yer almaktadır:
import torch
import torch.nn as nn
import torch.nn.functional as F
class CausalSelfAttention(nn.Module):
def __init__(self, d_model, n_heads):
super().__init__()
assert d_model % n_heads == 0
self.d_model = d_model
self.n_heads = n_heads
self.d_k = d_model // n_heads
# Query, Key ve Value için projeksiyonlar
self.q_proj = nn.Linear(d_model, d_model)
self.k_proj = nn.Linear(d_model, d_model)
self.v_proj = nn.Linear(d_model, d_model)
self.out_proj = nn.Linear(d_model, d_model)
def forward(self, x):
batch_size, seq_len, d_model = x.size()
# 1. Girdileri Q, K, V'ye projekte et
Q = self.q_proj(x).view(batch_size, seq_len, self.n_heads, self.d_k).transpose(1, 2)
K = self.k_proj(x).view(batch_size, seq_len, self.n_heads, self.d_k).transpose(1, 2)
V = self.v_proj(x).view(batch_size, seq_len, self.n_heads, self.d_k).transpose(1, 2)
# 2. Ham dikkat skorlarını hesapla
scores = torch.matmul(Q, K.transpose(-2, -1)) / (self.d_k ** 0.5)
# 3. Nedensel maske oluştur ve uygula
# Eksi sonsuz ile doldurulmuş üst üçgen maske
mask = torch.triu(torch.ones(seq_len, seq_len, device=x.device), diagonal=1).bool()
scores = scores.masked_fill(mask, float('-inf'))
# 4. Softmax, -inf değerini 0 olasılığa dönüştürür
attn_weights = F.softmax(scores, dim=-1)
# 5. Değerlerin ağırlıklı toplamını hesapla ve çıktıyı döndür
context = torch.matmul(attn_weights, V)
context = context.transpose(1, 2).contiguous().view(batch_size, seq_len, d_model)
return self.out_proj(context)
# Hızlı doğrulama testi
if __name__ == "__main__":
# Batch boyutu = 1, Dizi uzunluğu = 4, Model boyutu = 8, 2 kafa
x = torch.randn(1, 4, 8)
attention_layer = CausalSelfAttention(d_model=8, n_heads=2)
output = attention_layer(x)
print("Girdi Şekli (Input Shape):", x.shape)
print("Çıktı Şekli (Output Shape):", output.shape)
6. Mimari Karşılaştırma
| Özellik | BERT (Sadece Kodlayıcı) | GPT (Sadece Kod Çözücü) | Orijinal Transformer |
|---|---|---|---|
| Birincil Görev | Anlama / Çıkarma | Üretim / Sentez | Çeviri / Diziden Diziye |
| Dikkat Türü | Çift Yönlü Self-Attention | Nedensel Maskelenmiş Self-Attention | Çift Yönlü ve Nedensel Cross-Attention |
| Maskeleme | Maskelenmiş tokenlar ([MASK]) |
Nedensel üçgen maskeleme | Kod çözücüde nedensel maskeleme |
| İşleme | Tüm diziyi tek seferde işler | Otoregresif token üretimi | Kodlayıcı bir kez işler, Kod çözücü üretir |
Sonuç
Kodlayıcıyı devre dışı bırakıp tamamen nedensel maskelenmiş self-attention mekanizmasına odaklanarak GPT, üretken ölçeklemenin yolunu açtı. Bir sonraki tokenı tahmin etmenin basit kuralı, devasa paralel eğitimle birleştiğinde, GPT modellerinin mantık, kodlama ve dilin zengin temsillerini yakalamasını sağlayarak modern bilişsel yapay zekanın temelini oluşturdu.