GPT 트랜스포머의 작동 원리: 인과 관계 셀프 어텐션(Causal Self-Attention) 설명
GPT 트랜스포머의 작동 원리: 인과 관계 셀프 어텐션(Causal Self-Attention) 설명
최근 몇 년 동안 생성형 사전 학습 트랜스포머(GPT)는 인공지능 분야에 혁명을 일으켰습니다. 코딩 보조 도구부터 대화형 에이전트에 이르기까지, GPT 기반 모델은 오늘날 가장 발전된 생성형 애플리케이션의 핵심 원동력입니다. 하지만 이 기술은 실제로 어떻게 작동할까요?
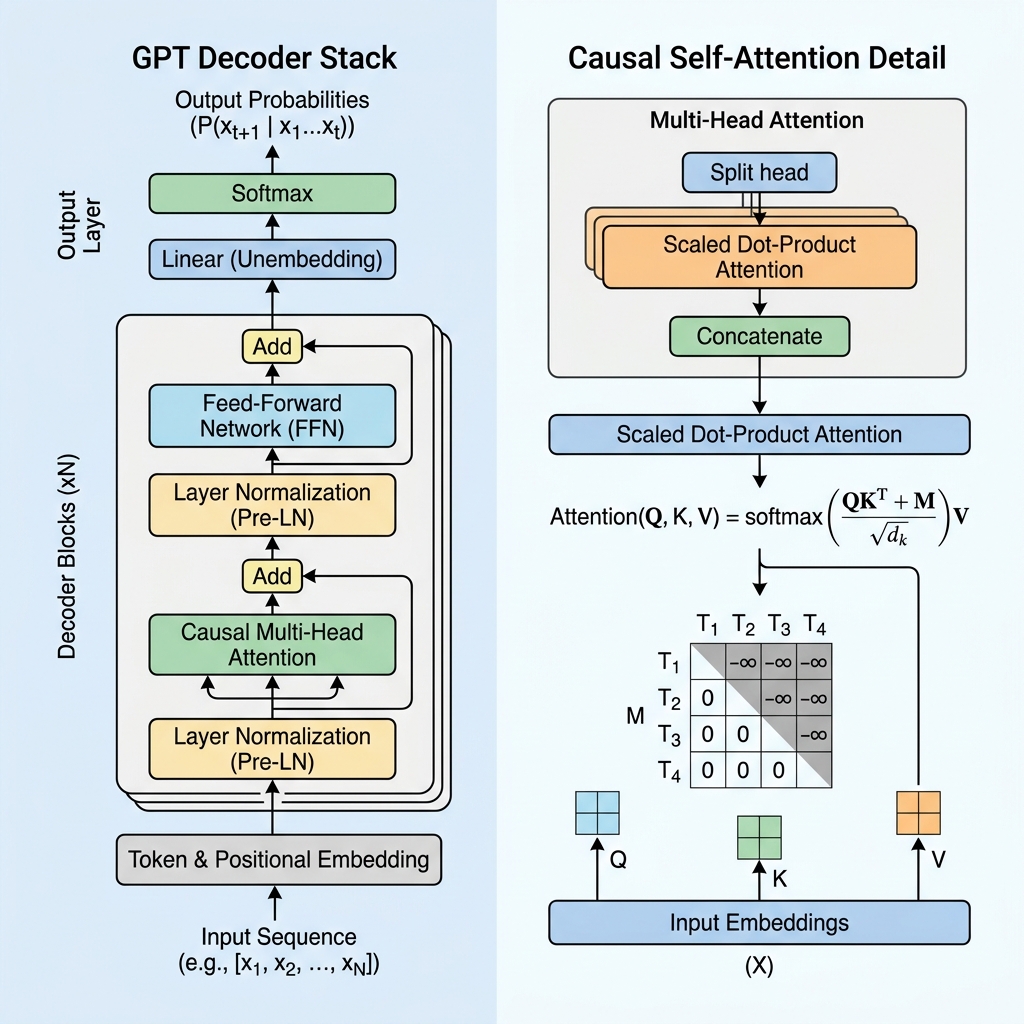
BERT와 같은 모델은 텍스트를 양방향으로 이해하기 위해 트랜스포머의 인코더(Encoder) 부분을 사용하는 반면, GPT는 자기회귀적(autoregressive)인 다음 토큰 예측을 위해 설계된 디코더 전용(Decoder-only) 아키텍처입니다. 이 블로그에서는 GPT 트랜스포머의 작동 원리를 명쾌하게 분석하고, 인과 관계 셀프 어텐션(causal self-attention) 메커니즘을 깊이 있게 다루며, 코드로 직접 구현해 보겠습니다.
1. 자기회귀적 생성 루프
본질적으로 GPT는 자기회귀 모델입니다. 이는 텍스트 시퀀스를 생성할 때 이미 생성된 토큰들을 다음 예측을 위한 컨텍스트(문맥)로 활용하여 다음 토큰을 하나씩 순차적으로 예측함을 의미합니다.
작업 흐름은 다음과 같습니다.
- 입력(Input): 모델이 프롬프트를 받습니다. 예:
"Deep learning is". - 예측(Prediction): 모델이 프롬프트를 처리하고 전체 어휘 사전(vocabulary)에 대한 확률 분포를 출력합니다. 다음 토큰을 샘플링합니다. 예:
"awesome". - 루프(Loop): 새 토큰이 입력 뒤에 추가되어
"Deep learning is awesome"이 됩니다. 이 시퀀스는 다음 단계의 입력이 됩니다. - 종료(Termination): 모델이 특수 문장 끝(
[EOS]) 토큰을 출력하거나 미리 정의된 길이 제한에 도달할 때까지 이 과정이 반복됩니다.
2. 인과 관계 마스킹(Causal Masking): 디코더의 핵심
BERT와 같은 인코더 전용 모델에서는 모든 토큰이 과거와 미래를 모두 보며 다른 모든 토큰에 어텐션을 줄 수 있습니다. 하지만 다음 토큰을 예측해야 하는 생성 모델의 경우, 학습 중에 미래를 보는 것은 “치팅(반칙)“에 해당합니다.
모델이 미래의 토큰을 보지 못하도록 방지하기 위해, GPT는 인과 관계 셀프 어텐션(Causal Self-Attention) (또는 마스킹된 셀프 어텐션)을 사용합니다.
인과 관계 마스크 행렬
셀프 어텐션 연산 중에는 쿼리(Queries, $Q$)와 키(Keys, $K$)의 내적(dot product)을 구하여 토큰 간의 유사도 점수를 계산합니다.
$$\text{Scores} = QK^T$$
인과 관계를 강제하기 위해, 대각선 위의 모든 값은 $-\infty$(음의 무한대)로 설정되고 대각선 및 그 아래 값은 0인 마스크 행렬 $M$을 적용합니다. 이 마스크를 점수에 더한 후 softmax 함수를 적용합니다.
$$\text{Masked Scores} = \frac{QK^T}{\sqrt{d_k}} + M$$
$$M = \begin{pmatrix} 0 & -\infty & -\infty & \dots & -\infty \\ 0 & 0 & -\infty & \dots & -\infty \\ 0 & 0 & 0 & \dots & -\infty \\ \vdots & \vdots & \vdots & \ddots & \vdots \\ 0 & 0 & 0 & \dots & 0 \end{pmatrix}$$
softmax 함수를 적용하면 $e^{-\infty}$는 $0$이 됩니다. 결과적으로 미래 토큰에 대한 어텐션 가중치(Attention Weights)는 정확히 0이 되어, 현재 토큰은 미래 토큰을 볼 수 없게 됩니다.
3. GPT 레이어의 핵심 아키텍처 블록
GPT 모델은 스택 구조로 쌓인 트랜스포머 디코더 레이어들로 구성됩니다. 각 레이어는 다음과 같은 몇 가지 중요한 컴포넌트를 포함합니다.
A. 입력 임베딩 및 위치 인코딩
- 토큰화: 원본 텍스트는 바이트 쌍 인코딩(BPE)을 사용하여 서브워드 토큰으로 분할됩니다.
- 토큰 임베딩: 각 토큰은 고차원 벡터로 매핑됩니다.
- 학습된 위치 임베딩: 셀프 어텐션 자체에는 순서에 대한 개념이 없기 때문에, GPT는 토큰 임베딩에 학습된 위치 임베딩 벡터를 더하여 모델이 시퀀스 내 각 토큰의 위치를 알 수 있도록 합니다.
B. 프리 레이어 정규화(Pre-Layer Normalization / Pre-LN)
잔차 연결(residual addition) 이후에 레이어 정규화를 적용하던 원래 트랜스포머 아키텍처(Post-LN)와 달리, 현대 GPT 아키텍처는 어텐션 및 피드포워드 레이어 이전에 레이어 정규화를 적용합니다.
$$x_{l+1} = x_l + \text{Attention}(\text{LayerNorm}(x_l))$$
Pre-LN은 학습 중 그래디언트(경사) 흐름을 안정화하여 수천억 개의 매개변수를 가진 매우 깊은 네트워크를 안정적으로 학습할 수 있도록 돕습니다.
C. 피드포워드 네트워크(Feed-Forward Network / FFN)
어텐션 블록 다음으로, 각 토큰의 표현은 두 개의 선형 변환과 활성화 함수(일반적으로 GeLU)로 구성된 다층 퍼셉트론(MLP)을 통과합니다.
$$\text{FFN}(x) = \max(0, x W_1 + b_1) W_2 + b_2$$
4. 샘플링 메커니즘 (로짓에서 토큰으로)
최종 디코더 블록은 각 위치에 대해 Logits라고 불리는 가공되지 않은 점수 벡터를 출력합니다. 우리는 softmax 함수를 사용하여 이 로짓들을 확률로 변환합니다. 생성된 텍스트의 무작위성을 제어하기 위해 샘플링 중에 다음과 같은 파라미터를 적용합니다.
- 온도(Temperature, $T$): softmax를 적용하기 전에 로짓의 크기를 조절합니다. 온도가 낮을수록(예: $T = 0.2$) 모델은 결정론적이고 일관된 답변을 생성하며, 온도가 높을수록(예: $T = 0.8$) 창의성과 다양성이 증가합니다.
- Top-K: 다음 토큰 후보를 가장 확률이 높은 상위 $K$개 토큰으로 제한합니다.
- Top-P (핵 샘플링 / Nucleus Sampling): 확률 분포를 누적하여 누적 확률이 $P$(예: $P = 0.9$)를 초과하는 최소한의 토큰 세트 중에서만 선택합니다.
5. 인과 관계 셀프 어텐션의 PyTorch 구현
아래는 인과 관계 마스킹이 적용된 인과 관계 셀프 어텐션을 보여주는 독립적인 PyTorch 구현 코드입니다.
import torch
import torch.nn as nn
import torch.nn.functional as F
class CausalSelfAttention(nn.Module):
def __init__(self, d_model, n_heads):
super().__init__()
assert d_model % n_heads == 0
self.d_model = d_model
self.n_heads = n_heads
self.d_k = d_model // n_heads
# Query, Key, Value 프로젝션 레이어
self.q_proj = nn.Linear(d_model, d_model)
self.k_proj = nn.Linear(d_model, d_model)
self.v_proj = nn.Linear(d_model, d_model)
self.out_proj = nn.Linear(d_model, d_model)
def forward(self, x):
batch_size, seq_len, d_model = x.size()
# 1. 입력을 Q, K, V로 투영
Q = self.q_proj(x).view(batch_size, seq_len, self.n_heads, self.d_k).transpose(1, 2)
K = self.k_proj(x).view(batch_size, seq_len, self.n_heads, self.d_k).transpose(1, 2)
V = self.v_proj(x).view(batch_size, seq_len, self.n_heads, self.d_k).transpose(1, 2)
# 2. 원시 어텐션 점수 계산
scores = torch.matmul(Q, K.transpose(-2, -1)) / (self.d_k ** 0.5)
# 3. 인과 관계 마스크 생성 및 적용
# 음의 무한대로 채워진 상삼각 마스크
mask = torch.triu(torch.ones(seq_len, seq_len, device=x.device), diagonal=1).bool()
scores = scores.masked_fill(mask, float('-inf'))
# 4. Softmax를 거치며 -inf는 0의 확률로 변환됨
attn_weights = F.softmax(scores, dim=-1)
# 5. Value들의 가중합 계산 및 출력
context = torch.matmul(attn_weights, V)
context = context.transpose(1, 2).contiguous().view(batch_size, seq_len, d_model)
return self.out_proj(context)
# 빠른 검증 실행
if __name__ == "__main__":
# 배치 크기 = 1, 시퀀스 길이 = 4, 모델 차원 = 8, 헤드 수 = 2
x = torch.randn(1, 4, 8)
attention_layer = CausalSelfAttention(d_model=8, n_heads=2)
output = attention_layer(x)
print("입력 텐서 크기:", x.shape)
print("출력 텐서 크기:", output.shape)
6. 아키텍처 비교
| 특징 | BERT (인코더 전용) | GPT (디코더 전용) | 원조 트랜스포머 |
|---|---|---|---|
| 주요 작업 | 이해 / 정보 추출 | 생성 / 텍스트 합성 | 번역 / 시퀀스 투 시퀀스 |
| 어텐션 타입 | 양방향 셀프 어텐션 | 인과 관계 마스킹 셀프 어텐션 | 양방향 및 인과 관계 크로스 어텐션 |
| 마스킹 | 마스킹된 토큰 ([MASK]) |
인과 관계 삼각 마스킹 | 디코더 내부의 인과 관계 마스킹 |
| 처리 방식 | 전체 시퀀스를 한 번에 처리 | 자기회귀적 토큰 생성 | 인코더는 한 번만 처리, 디코더가 점진적으로 생성 |
결론
인코더를 제거하고 인과 관계 마스킹 셀프 어텐션에 완전히 집중함으로써, GPT는 생성 모델 스케일링의 길을 열었습니다. 다음 토큰을 예측한다는 간단한 규칙과 대규모 병렬 학습의 결합은 GPT 모델이 논리, 코딩, 그리고 언어의 풍부한 표현을 캡처할 수 있도록 지원하며, 현대 인지형 AI의 초석이 되었습니다.