איך עובد GPT Transformer: קשב עצمی סיבתי מוסבר
בשנים האחרונות, מודלים מסוג Generative Pre-trained Transformers (GPT) לחולל מהפכה בבינה המלאכותית. מעוזרי תכנות ועד לסוכנים שיحתיים, מודלים מבוססי GPT מפעילים כיום את האפליקציות היוצרות המתקדמות ביותר. אבל איך הטכנולוגיה הזו בעצם עובדת?
בעוד שמודלים כמו BERT משתמשים בחלק ה-Encoder של ה-Transformer כדי להבין טקסט באופן דו-כיווני, GPT משתמש בארכיטקטורה של Decoder-only המיועדת לחיזוי אוטו-רגרסיבי של הטוקן הבא. בבלוג זה, נחשוף את סודות ה-GPT Transformer, נצלול לעומק מנגנון הקשב העצמי הסיבתי (causal self-attention), ונממש אותו בקود.
1. לולאת היצירה האוטו-רגרסיבית (Autoregressive Loop)
בבסיסו, GPT הוא מודל אוטו-רגרסיבי. המשمعות היא שכדי ליצור רצף של טקסט, הוא מנבא את הטוקן הבא בזה אחר זה, תוך שימוש בטוקנים שכבר נוצרו כהקשר לחיזוי הבא.
תהליך העבודה כולל את השלבים הבאים:
- קלט (Input): המודל מקבל הנחיה (prompt):
"Deep learning is". - חיזוי (Prediction): המודל מעבד את ההנחיה ומפיק התפלגות הסתברות על פני כל אוצר המילים שלו. הוא דוגם את הטוקן הבא:
"awesome". - לولאה (Loop): הטוקן החדש מתווסף לקלט, והופך אותו ל:
"Deep learning is awesome". רצף זה הופך לקלט לשלב הבא. - סיום (Termination): התהליך חוזר על עצמו עד שהמודל מפיק טוקן מיוחד של סוף רצף (
[EOS]) או מגיע למגבלת אורך מוגدرת מראש.
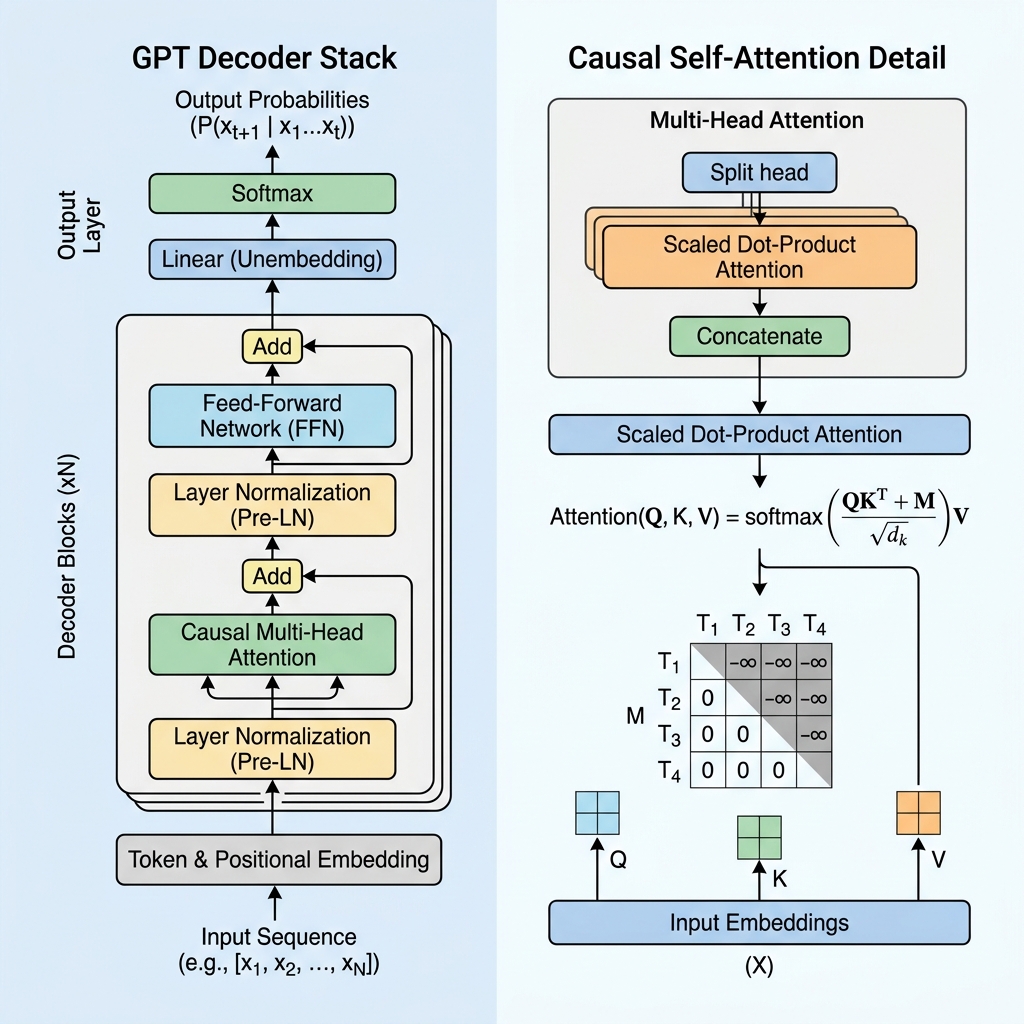
2. מסכה סיבתית (Causal Masking): הלב של ה-Decoder
במודל המבוסס על אנקודר בלבד כמו BERT, כל טוקן יכול להתייחס לכל טוקן אחר, תוך הסתכלות הן על העבר והן על העתיד. עם זאת, עבור מודל גנרטיבי שמנבא את הטוקן הבא, הסתכלות על העתיد במהלך האימון תיחשב כ"רמאות".
כדי למנוע מהמודל להסתכל על טוקנים עתידיים, GPT משתמש ב-Causal Self-Attention (קשב עצמי סיבתי או ממוסך).
מטריצת המסכה הסיבתית
במהלך חיشוב הקשב העצמי, אנו מחשבים ציוני דמיון בין טוקנים על ידי ביצוע מכפלה סקלרית של שאילתות ($Q$) ומפתחות ($K$):
$$\text{Scores} = QK^T$$
כדי לאכוף סיבתיות, אנו מפעילים מטריצת מסכה $M$ שבה כל הערכים מעל האלכסון נקבעים ל-$-\infty$ (מינוס אינסוף), והערכים באלכסון ומתחתיו הם 0. אנו מוסיפים מסכה זו לציונים לפני החלת פונקציית ה-softmax:
$$\text{Masked Scores} = \frac{QK^T}{\sqrt{d_k}} + M$$
$$M = \begin{pmatrix} 0 & -\infty & -\infty & \dots & -\infty \\ 0 & 0 & -\infty & \dots & -\infty \\ 0 & 0 & 0 & \dots & -\infty \\ \vdots & \vdots & \vdots & \ddots & \vdots \\ 0 & 0 & 0 & \dots & 0 \end{pmatrix}$$
כאשר אנו מפעילים את פונקציית ה-softmax, ה-$e^{-\infty}$ הופך ל-$0$. כתוצאה מכך, משקלי הקשב עבור כל טוקן עתידי הופכים בדיוק ל-0, מה שהופך את הטוקנים העתידיים לבלתי נראים עבור הטוקן הנוכחי.
3. רכיבי הארכיטקטורה המרכزيים של שכבת GPT
מודל GPT מורכב משכבות מפענח (decoder) טרנספורמר מוערמות. כל שכבה מכילה כמה רכיבים קריטיים:
א. ייצוגי קלט וקידוד מיקומי (Embeddings & Positional Encoding)
- טוקניזציה: טקסט גולמי מפוצל לטוקנים של תתי-מילים באמצעות קידود זוגות בתים (BPE).
- Embeddings של טוקנים: כל טוקן ממופה לוקטור רב-ממדי.
- קידומי מיקום נלמדים: מכיוון שלקשב עצמי אין תחושת סדר מולדת, GPT מוסיף וקטורי קידוד מיקומיים נלמדים ל-embeddings של הטוקנים, מה שמאפשר למודל לדעת את המיקום של כל טוקן ברצף.
ב. נורמליזציה לפני השכבה (Pre-Layer Normalization / Pre-LN)
בניגود לארכיטקטורת ה-Transformer המקורית, שהחילה נורמליזציית שכבה לאחר החיבור השיורי (Post-LN), ארכיטקטורות GPT מודרניות מפעילות נורמליזציית שכבה לפני שכבות הקשב וההזנה קדימה (feed-forward):
$$x_{l+1} = x_l + \text{Attention}(\text{LayerNorm}(x_l))$$
Pre-LN מייצב את הגרדיאנטים במהלך האימון, ומאפשר אימون יציב של רשתות עמוקות מאוד עם מאות מיליארדי פרמטרים.
ג. רשת הזנה קדימה (Feed-Forward Network / FFN)
בעקבות בלוק הקשب, הייצוג של كل טוקן עובר דרך פרספטרון רב-שכבתי (MLP) המורכב משתי טרנספורמציות ליניאריות ופונקציית אקטיבציה (בדרך כלל GeLU):
$$\text{FFN}(x) = \max(0, x W_1 + b_1) W_2 + b_2$$
4. מנגנון הדגימה (מלוגיטים לטוקנים)
בלוק המפענח האחרון מפיق וקטור של ציונים גולמיים הנקראים Logits עבור כל מיקום. אנו ממירים לוגיטים אלו להסתברויות באמצעות פונקציית ה-softmax. כדי לשלוט באקראיות של הטקסט שנוצר, אנו מפעילים פרמטרים במהלך הדגימה:
- טמפרטורה ($T$): משנה את קנה המידה של הלוגיטים לפני ה-softmax. טמפרטורה נמוכה יותר (למשل, $T = 0.2$) הופכת את המודל לדטרמיניסטי וממוקד יותר, בעוד שטמפרטורה גבוהה יותר (למשل, $T = 0.8$) מגבירה את היצירתיות והגוון.
- Top-K: מגביל את בחירות הטוקן הבא ל-$K$ הטוקנים בעلی ההסתברות הגבוהה ביותר.
- Top-P (דגימת גרעין): צובר את התפלגות ההסתברות ובוחר מתוך קבוצת הטוקנים הקטנה ביותר שההסתברות המצטברת שלהם עולה על $P$ (למשل, $P = 0.9$).
5. מימוש Causal Self-Attention ב-PyTorch
להלن מימוש עצמאי ב-PyTorch המדגים קשב עצמי סיבתי עם מסכה סיבתית:
import torch
import torch.nn as nn
import torch.nn.functional as F
class CausalSelfAttention(nn.Module):
def __init__(self, d_model, n_heads):
super().__init__()
assert d_model % n_heads == 0
self.d_model = d_model
self.n_heads = n_heads
self.d_k = d_model // n_heads
# הטלות עבור Query, Key, ו-Value
self.q_proj = nn.Linear(d_model, d_model)
self.k_proj = nn.Linear(d_model, d_model)
self.v_proj = nn.Linear(d_model, d_model)
self.out_proj = nn.Linear(d_model, d_model)
def forward(self, x):
batch_size, seq_len, d_model = x.size()
# 1. הטلت קלטים ל-Q, K, V
Q = self.q_proj(x).view(batch_size, seq_len, self.n_heads, self.d_k).transpose(1, 2)
K = self.k_proj(x).view(batch_size, seq_len, self.n_heads, self.d_k).transpose(1, 2)
V = self.v_proj(x).view(batch_size, seq_len, self.n_heads, self.d_k).transpose(1, 2)
# 2. חישוב ציוני קשב גולמיים
scores = torch.matmul(Q, K.transpose(-2, -1)) / (self.d_k ** 0.5)
# 3. יצירה והחלה של מסכה סיבתית
# מסכה משולשת עליונה מלאה במינוס אינסוף
mask = torch.triu(torch.ones(seq_len, seq_len, device=x.device), diagonal=1).bool()
scores = scores.masked_fill(mask, float('-inf'))
# 4. Softmax הופך -inf להסתברות 0
attn_weights = F.softmax(scores, dim=-1)
# 5. חישוב סכום משוקלל של ערכים ופלט
context = torch.matmul(attn_weights, V)
context = context.transpose(1, 2).contiguous().view(batch_size, seq_len, d_model)
return self.out_proj(context)
# הרצת אימות מהירה
if __name__ == "__main__":
# גודל אצווה = 1, אורך רצף = 4, מימד מודל = 8, 2 ראשי קשב
x = torch.randn(1, 4, 8)
attention_layer = CausalSelfAttention(d_model=8, n_heads=2)
output = attention_layer(x)
print("Input Shape:", x.shape)
print("Output Shape:", output.shape)
6. השוואה ארכיטקטונית
| תכונה | BERT (אנקודר בלבד) | GPT (مפענח בלבד) | טרנספורמר מקורי |
|---|---|---|---|
| משימה עיקרית | הבנה / חילוץ מידע | יצירה / סינתזה | תרגום / רצף לרצף |
| סוג קשב | קשב עצמי דו-כיווני | קשב עצמי סיבתי ממוסך | קשב חוצה דו-כיווני וסיבתי |
| מסכות | טוקנים ממוסכים ([MASK]) |
מסכה משולשת סיבתית | מסכה סיבתית במפענח |
| עיבוד | מעבד את כל הרצף בבת אחת | יצירת טוקנים אוטו-רגרסיבית | האנקودר מעבד פעם אחת, המפענח מייצר |
סיכום
על ידי ויתור על האנקודר והתמקדות מלאה בקשב עצמי סיבתי ממוסך, GPT פתח את הדרך להרחבה גנרטיבית. הכלל הפשוט של ניבוי הטוקן הבא, בשילوب עם אימון מקבילי עצום, מאפשר למודלי GPT ללכוד ייצוגים עשירים של לוגיקה, קוד ושפה, המהווים את היסוד של הבינה המלאכותית הקוגניטיבית המודרנית.