GPT Transformer 如何工作:因果自注意力机制解析
近年来,生成式预训练 Transformer(GPT)彻底改变了人工智能。从代码助手到对话智能体,基于 GPT 的模型正在为当今最先进的生成式应用提供动力。但是这项技术究竟是如何工作的呢?
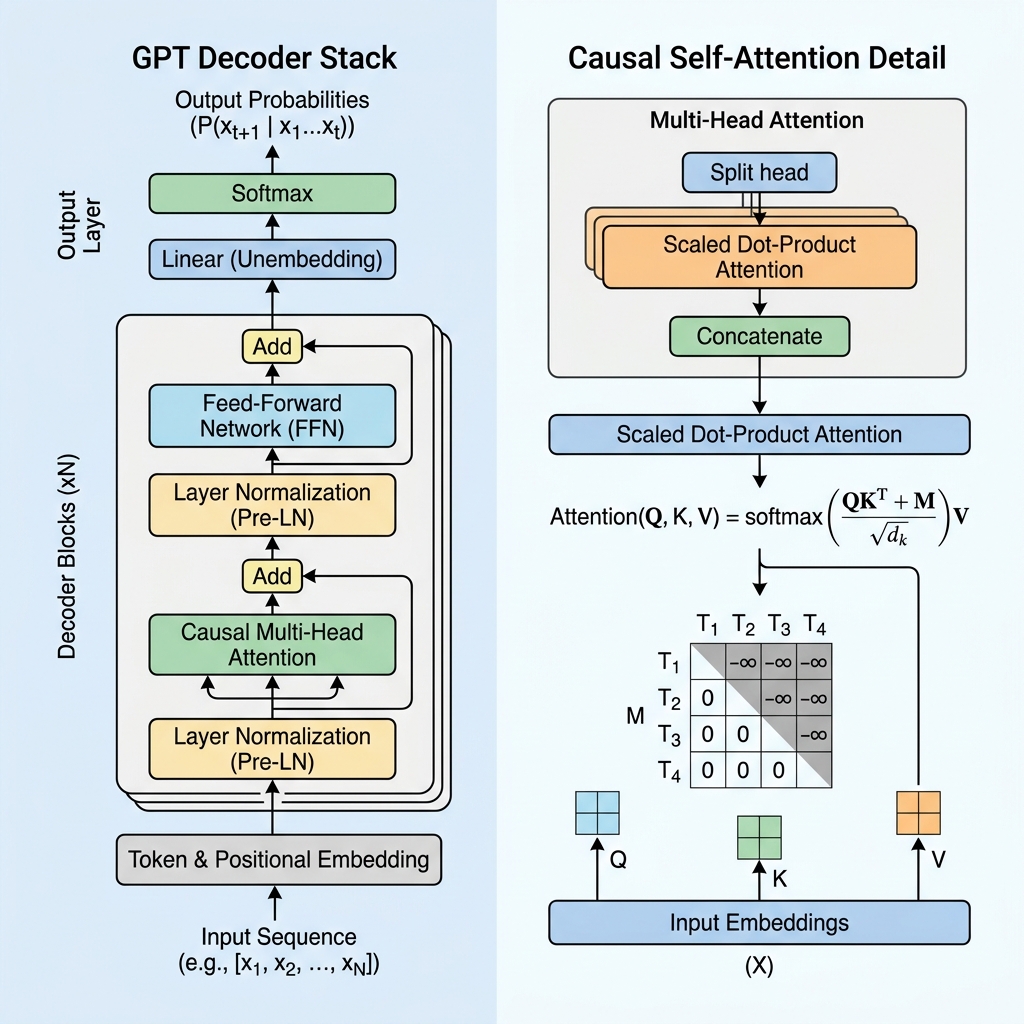
虽然像 BERT 这样的模型使用 Transformer 的**编码器(Encoder)部分来双向理解文本,但 GPT 采用的是仅解码器(Decoder-only)**的架构,专为自回归的下一 token 预测而设计。在本文中,我们将揭秘 GPT Transformer 的工作原理,深入探讨因果自注意力(Causal Self-Attention)机制,并在代码中对其进行实现。
1. 自回归生成循环
在核心层面,GPT 是一个自回归模型。这意味着要生成一段文本序列,它会一个接一个地预测下一个 token,并使用已生成的 token 作为下一次预测的上下文。
其工作流程遵循以下步骤:
- 输入: 模型接收一个提示词(prompt):
"Deep learning is"。 - 预测: 模型处理该提示,并在其整个词汇表上输出一个概率分布。它对下一个 token 进行采样:
"awesome"。 - 循环: 新生成的 token 被追加到输入中,使其变为:
"Deep learning is awesome"。这个新序列成为下一步的输入。 - 终止: 重复该过程,直到模型输出特殊的序列结束符(
[EOS])或达到预设的长度限制。
2. 因果掩码:解码器的核心
在像 BERT 这样仅包含编码器的模型中,每个 token 都可以关注所有其他 token,同时回顾过去并展望未来。然而,对于预测下一个 token 的生成式模型来说,在训练期间看到未来的 token 属于“作弊”。
为了防止模型看到未来的 token, GPT 使用了因果自注意力机制(或称掩码自注意力机制)。
因果掩码矩阵
在自注意力计算期间,我们通过计算查询(Query, $Q$)和键(Key, $K$)的点积来计算 token 之间的相似度得分:
$$\text{Scores} = QK^T$$
为了强制执行因果关系,我们引入一个掩码矩阵 $M$,其中对角线以上的所有值都设为 $-\infty$(负无穷大),对角线及以下的值设为 0。在应用 softmax 函数之前,我们将此掩码加到得分矩阵中:
$$\text{Masked Scores} = \frac{QK^T}{\sqrt{d_k}} + M$$
$$M = \begin{pmatrix} 0 & -\infty & -\infty & \dots & -\infty \\ 0 & 0 & -\infty & \dots & -\infty \\ 0 & 0 & 0 & \dots & -\infty \\ \vdots & \vdots & \vdots & \ddots & \vdots \\ 0 & 0 & 0 & \dots & 0 \end{pmatrix}$$
当我们应用 softmax 函数时,$e^{-\infty}$ 会变为 $0$。因此,任何未来位置的注意力权重都会变为精确的 0,从而使未来的 token 对当前的 token 不可见。
3. GPT 层的核心架构模块
GPT 模型由多个堆叠的 Transformer 解码器层组成。每一层包含以下几个关键部分:
A. 输入嵌入与位置编码
- 分词(Tokenization): 原始文本使用字节对编码(Byte-Pair Encoding, BPE)被拆分为子词 token。
- Token 嵌入: 每个 token 被映射到一个高维向量。
- 可学习的位置嵌入: 由于自注意力本身不包含顺序信息,GPT 将可学习的位置嵌入向量加到 token 嵌入中,以便模型知道每个 token 在序列中的位置。
B. 前置层归一化(Pre-Layer Normalization / Pre-LN)
原始 Transformer 架构在残差连接加法之后应用层归一化(Post-LN),而现代 GPT 架构则在注意力层和前馈网络层之前应用层归一化:
$$x_{l+1} = x_l + \text{Attention}(\text{LayerNorm}(x_l))$$
Pre-LN 稳定了训练期间的梯度流,使我们能够稳定地训练具有数千亿参数的深层网络。
C. 前馈网络(Feed-Forward Network / FFN)
在注意力模块之后,每个 token 的表示通过一个多层感知机(MLP),该感知机由两次线性变换和一个激活函数(通常是 GeLU)组成:
$$\text{FFN}(x) = \max(0, x W_1 + b_1) W_2 + b_2$$
4. 采样机制(从 Logits 到 Token)
最后的解码器模块输出每个位置上原始得分的向量,称为 Logits。我们使用 softmax 函数将这些 logits 转化为概率。为了控制生成文本的随机性,我们在采样时应用以下参数:
- 温度(Temperature, $T$): 在 softmax 之前对 logits 进行缩放。较低的温度(例如 $T = 0.2$)使模型输出更具确定性且更集中,而较高的温度(例如 $T = 0.8$)则会增加创造力和多样性。
- Top-K: 限制下一步选择为概率最高的前 $K$ 个 token。
- Top-P(核采样 / Nucleus Sampling): 累加概率分布,并从累加概率超过 $P$(例如 $P = 0.9$)的最小 token 集合中进行选择。
5. 因果自注意力的 PyTorch 实现
下面是一个自包含的 PyTorch 实现,演示了带有因果掩码的因果自注意力机制:
import torch
import torch.nn as nn
import torch.nn.functional as F
class CausalSelfAttention(nn.Module):
def __init__(self, d_model, n_heads):
super().__init__()
assert d_model % n_heads == 0
self.d_model = d_model
self.n_heads = n_heads
self.d_k = d_model // n_heads
# 查询、键和值的映射层
self.q_proj = nn.Linear(d_model, d_model)
self.k_proj = nn.Linear(d_model, d_model)
self.v_proj = nn.Linear(d_model, d_model)
self.out_proj = nn.Linear(d_model, d_model)
def forward(self, x):
batch_size, seq_len, d_model = x.size()
# 1. 将输入映射到 Q, K, V
Q = self.q_proj(x).view(batch_size, seq_len, self.n_heads, self.d_k).transpose(1, 2)
K = self.k_proj(x).view(batch_size, seq_len, self.n_heads, self.d_k).transpose(1, 2)
V = self.v_proj(x).view(batch_size, seq_len, self.n_heads, self.d_k).transpose(1, 2)
# 2. 计算原始注意力得分
scores = torch.matmul(Q, K.transpose(-2, -1)) / (self.d_k ** 0.5)
# 3. 创建并应用因果掩码
# 用负无穷大填充的上三角掩码
mask = torch.triu(torch.ones(seq_len, seq_len, device=x.device), diagonal=1).bool()
scores = scores.masked_fill(mask, float('-inf'))
# 4. Softmax 将 -inf 转化为 0 概率
attn_weights = F.softmax(scores, dim=-1)
# 5. 计算值的加权和并输出
context = torch.matmul(attn_weights, V)
context = context.transpose(1, 2).contiguous().view(batch_size, seq_len, d_model)
return self.out_proj(context)
# 快速验证运行
if __name__ == "__main__":
# 批大小 = 1, 序列长度 = 4, 模型维度 = 8, 2个注意力头
x = torch.randn(1, 4, 8)
attention_layer = CausalSelfAttention(d_model=8, n_heads=2)
output = attention_layer(x)
print("输入特征维度:", x.shape)
print("输出特征维度:", output.shape)
6. 架构对比
| 特征 | BERT(仅编码器) | GPT(仅解码器) | 原始 Transformer |
|---|---|---|---|
| 主要任务 | 理解 / 信息抽取 | 生成 / 文本合成 | 翻译 / 序列到序列 |
| 注意力类型 | 双向自注意力 | 因果掩码自注意力 | 双向与因果交叉注意力 |
| 掩码机制 | 掩码 token ([MASK]) |
因果三角掩码 | 解码器中的因果掩码 |
| 处理方式 | 一次性处理整个序列 | 自回归 token 生成 | 编码器处理一次,解码器迭代生成 |
结论
通过舍弃编码器并完全专注于因果掩码自注意力,GPT 开启了生成式模型规模扩展的道路。预测下一个 token 的简单规则,结合大规模的并行训练,使得 GPT 模型能够捕捉逻辑、代码和语言的丰富内部表示,构成了现代认知智能的基石。