Wie der GPT-Transformer funktioniert: Kausale Self-Attention erklärt
In den letzten Jahren haben Generative Pre-trained Transformers (GPT) die künstliche Intelligenz revolutioniert. Von Programmierassistenten bis hin zu Konversationsagenten treiben GPT-basierte Modelle heute die fortschrittlichsten generativen Anwendungen an. Aber wie funktioniert diese Technologie eigentlich?
Während Modelle wie BERT den Encoder-Teil des Transformers nutzen, um Text bidirektional zu verstehen, ist GPT eine Decoder-only-Architektur, die für die autoregressive Vorhersage des nächsten Tokens konzipiert ist. In diesem Blog werden wir die Funktionsweise des GPT-Transformers entmystifizieren, tief in den kausalen Self-Attention-Mechanismus eintauchen und ihn im Code implementieren.
1. Die autoregressive Generierungsschleife
Im Kern ist GPT ein autoregressives Modell. Das bedeutet, dass es zur Generierung einer Textsequenz das nächste Token nacheinander vorhersagt, wobei es die bereits generierten Token als Kontext für die nächste Vorhersage verwendet.
Der Arbeitsablauf folgt diesen Schritten:
- Eingabe (Input): Das Modell erhält eine Eingabeaufforderung (Prompt):
"Deep learning is". - Vorhersage (Prediction): Das Modell verarbeitet diesen Prompt und gibt eine Wahrscheinlichkeitsverteilung über sein gesamtes Vokabular aus. Es wählt das nächste Token aus:
"awesome". - Schleife (Loop): Das neue Token wird an die Eingabe angehängt, sodass sie lautet:
"Deep learning is awesome". Diese Sequenz wird zur Eingabe für den nächsten Schritt. - Beendigung (Termination): Der Prozess wiederholt sich, bis das Modell ein spezielles End-of-Sequence-Token (
[EOS]) ausgibt oder ein vordefiniertes Längenlimit erreicht.
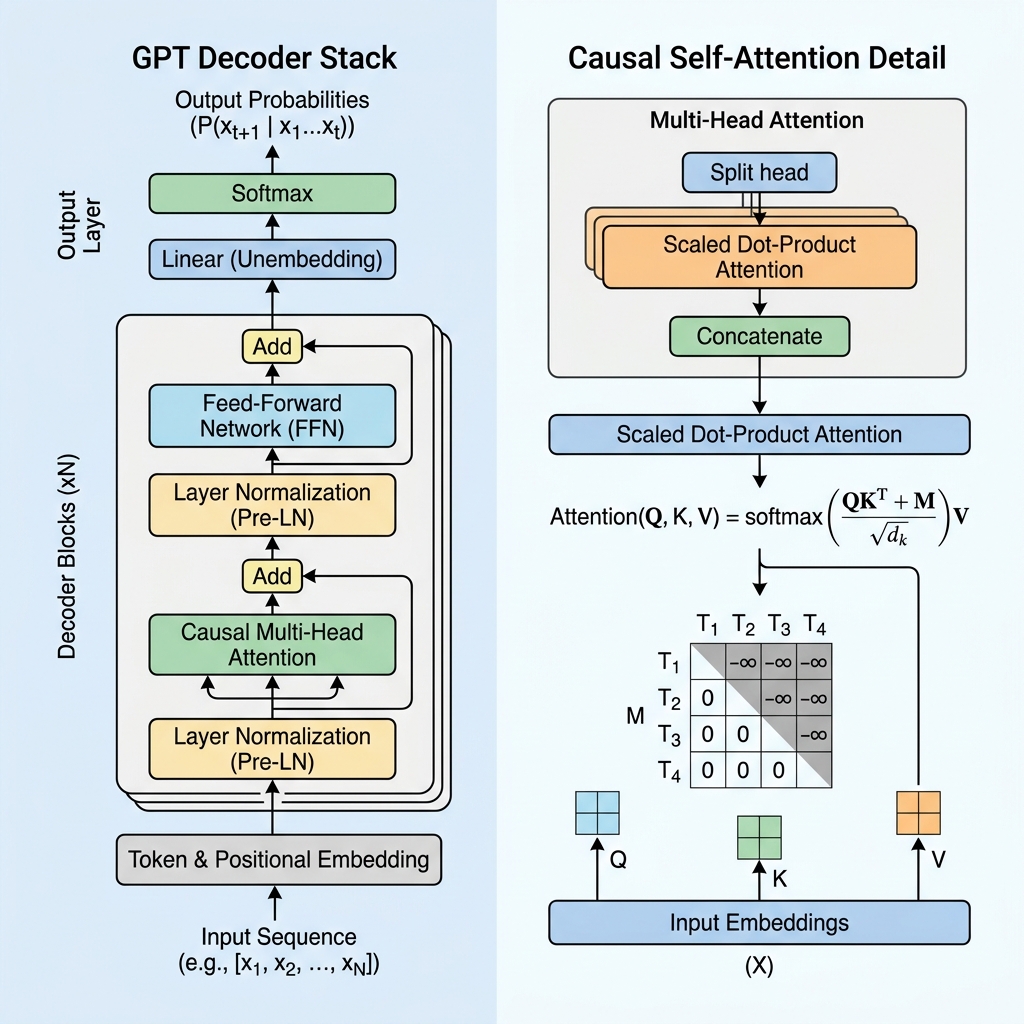
2. Kausale Maskierung: Das Herzstück des Decoders
In einem reinen Encoder-Modell wie BERT kann sich jedes Token auf jedes andere Token beziehen und blickt dabei sowohl in die Vergangenheit als auch in die Zukunft. Für ein generatives Modell, das das nächste Token vorhersagt, wäre der Blick in die Zukunft während des Trainings jedoch „Schummeln“.
Um zu verhindern, dass das Modell zukünftige Token sieht, verwendet GPT Causal Self-Attention (oder maskierte Self-Attention).
Die kausale Maskenmatrix
Während der Self-Attention-Berechnung ermitteln wir Ähnlichkeitswerte zwischen Token, indem wir das Skalarprodukt von Queries ($Q$) und Keys ($K$) bilden:
$$\text{Scores} = QK^T$$
Um die Kausalität zu erzwingen, wenden wir eine Maskenmatrix $M$ an, bei der alle Werte oberhalb der Diagonale auf $-\infty$ (minus unendlich) und Werte auf und unterhalb der Diagonale auf 0 gesetzt werden. Wir addieren diese Maske zu den Scores, bevor wir die Softmax-Funktion anwenden:
$$\text{Masked Scores} = \frac{QK^T}{\sqrt{d_k}} + M$$
$$M = \begin{pmatrix} 0 & -\infty & -\infty & \dots & -\infty \\ 0 & 0 & -\infty & \dots & -\infty \\ 0 & 0 & 0 & \dots & -\infty \\ \vdots & \vdots & \vdots & \ddots & \vdots \\ 0 & 0 & 0 & \dots & 0 \end{pmatrix}$$
Wenn wir die Softmax-Funktion anwenden, wird $e^{-\infty}$ zu $0$. Folglich werden die Aufmerksamkeitsgewichte (Attention Weights) für alle zukünftigen Token genau 0, was zukünftige Token für das aktuelle Token unsichtbar macht.
3. Kernkomponenten einer GPT-Schicht
Ein GPT-Modell besteht aus gestapelten Transformer-Decoder-Schichten. Jede Schicht enthält mehrere wichtige Komponenten:
A. Eingabe-Embeddings und Positionskodierung
- Tokenisierung: Rohtext wird mithilfe von Byte-Pair Encoding (BPE) in Teilwort-Token zerlegt.
- Token-Embeddings: Jedes Token wird auf einen hochdimensionalen Vektor abgebildet.
- Gelernte Positions-Embeddings: Da Self-Attention keine inhärente Reihenfolge kennt, fügt GPT gelernten Positions-Embedding-Vektoren zu den Token-Embeddings hinzu, sodass das Modell die Position jedes Tokens in der Sequenz kennt.
B. Pre-Layer Normalization (Pre-LN)
Im Gegensatz zur ursprünglichen Transformer-Architektur, bei der die Layer Normalization nach der Addition der Residuallayer angewendet wurde (Post-LN), wenden moderne GPT-Architekturen die Layer Normalization vor den Attention- und Feed-Forward-Schichten an:
$$x_{l+1} = x_l + \text{Attention}(\text{LayerNorm}(x_l))$$
Pre-LN stabilisiert die Gradienten während des Trainings und ermöglicht das stabile Trainieren von sehr tiefen Netzwerken mit Hunderten von Milliarden Parametern.
C. Feed-Forward-Netzwerk (FFN)
Nach dem Attention-Block durchläuft die Darstellung jedes Tokens ein mehrschichtiges Perzeptron (MLP), das aus zwei linearen Transformationen und einer Aktivierungsfunktion (normalerweise GeLU) besteht:
$$\text{FFN}(x) = \max(0, x W_1 + b_1) W_2 + b_2$$
4. Die Sampling-Mechanik (Von Logits zu Token)
Der letzte Decoderblock gibt für jede Position einen Vektor mit rohen Werten aus, die als Logits bezeichnet werden. Wir wandeln diese Logits mithilfe der Softmax-Funktion in Wahrscheinlichkeiten um. Um die Zufälligkeit des generierten Textes zu steuern, wenden wir beim Sampling Parameter an:
- Temperatur ($T$): Skaliert die Logits vor dem Softmax. Eine niedrigere Temperatur (z. B. $T = 0,2$) macht das Modell deterministischer und fokussierter, während eine höhere Temperatur (z. B. $T = 0,8$) die Kreativität und Vielfalt erhöht.
- Top-K: Begrenzt die Auswahl des nächsten Tokens auf die Top $K$ der wahrscheinlichsten Token.
- Top-P (Nucleus-Sampling): Kumuliert die Wahrscheinlichkeitsverteilung und wählt aus der kleinsten Menge von Token aus, deren kumulative Wahrscheinlichkeit $P$ übersteigt (z. B. $P = 0,9$).
5. PyTorch-Implementierung der kausalen Self-Attention
Unten finden Sie eine eigenständige PyTorch-Implementierung, die kausale Self-Attention mit kausaler Maskierung demonstriert:
import torch
import torch.nn as nn
import torch.nn.functional as F
class CausalSelfAttention(nn.Module):
def __init__(self, d_model, n_heads):
super().__init__()
assert d_model % n_heads == 0
self.d_model = d_model
self.n_heads = n_heads
self.d_k = d_model // n_heads
# Projektionen für Query, Key und Value
self.q_proj = nn.Linear(d_model, d_model)
self.k_proj = nn.Linear(d_model, d_model)
self.v_proj = nn.Linear(d_model, d_model)
self.out_proj = nn.Linear(d_model, d_model)
def forward(self, x):
batch_size, seq_len, d_model = x.size()
# 1. Projiziere Eingaben auf Q, K, V
Q = self.q_proj(x).view(batch_size, seq_len, self.n_heads, self.d_k).transpose(1, 2)
K = self.k_proj(x).view(batch_size, seq_len, self.n_heads, self.d_k).transpose(1, 2)
V = self.v_proj(x).view(batch_size, seq_len, self.n_heads, self.d_k).transpose(1, 2)
# 2. Berechne rohe Attention-Scores
scores = torch.matmul(Q, K.transpose(-2, -1)) / (self.d_k ** 0.5)
# 3. Erstelle und wende die kausale Maske an
# Obere Dreiecksmaske, gefüllt mit minus unendlich
mask = torch.triu(torch.ones(seq_len, seq_len, device=x.device), diagonal=1).bool()
scores = scores.masked_fill(mask, float('-inf'))
# 4. Softmax verwandelt -inf in 0 Wahrscheinlichkeit
attn_weights = F.softmax(scores, dim=-1)
# 5. Berechne gewichtete Summe der Werte und die Ausgabe
context = torch.matmul(attn_weights, V)
context = context.transpose(1, 2).contiguous().view(batch_size, seq_len, d_model)
return self.out_proj(context)
# Schneller Verifizierungslauf
if __name__ == "__main__":
# Batchgröße = 1, Sequenzlänge = 4, Modelldimension = 8, 2 Köpfe
x = torch.randn(1, 4, 8)
attention_layer = CausalSelfAttention(d_model=8, n_heads=2)
output = attention_layer(x)
print("Eingabe-Shape:", x.shape)
print("Ausgabe-Shape:", output.shape)
6. Architektonischer Vergleich
| Merkmal | BERT (nur Encoder) | GPT (nur Decoder) | Original Transformer |
|---|---|---|---|
| Hauptaufgabe | Verständnis / Extraktion | Generierung / Synthese | Übersetzung / Sequence-to-Sequence |
| Aufmerksamkeitstyp | Bidirektionale Self-Attention | Kausale maskierte Self-Attention | Bidirektionale & kausale Cross-Attention |
| Maskierung | Maskierte Token ([MASK]) |
Kausale Dreiecksmaskierung | Kausale Maskierung im Decoder |
| Verarbeitung | Verarbeitet die ganze Sequenz auf einmal | Autoregressive Token-Generierung | Encoder verarbeitet einmal, Decoder generiert |
Fazit
Durch das Verwerfen des Encoders und die vollständige Fokussierung auf kausale, maskierte Self-Attention ebnete GPT den Weg für die generative Skalierung. Die einfache Regel der Vorhersage des nächsten Tokens, kombiniert mit massivem parallelem Training, ermöglicht es GPT-Modellen, reichhaltige Repräsentationen von Logik, Programmierung und Sprache zu erfassen, die das Fundament der modernen kognitiven KI bilden.
Entdecken Sie weitere technische Einblicke im Ghaznix-Blog →