Cómo funciona el GPT Transformer: Explicación de la Autoatención Causal
En los últimos años, los Transformers Generativos Preentrenados (GPT) han revolucionado la inteligencia artificial. Desde asistentes de código hasta agentes conversacionales, los modelos basados en GPT impulsan las aplicaciones generativas más avanzadas de la actualidad. Pero, ¿cómo funciona realmente esta tecnología?
Mientras que modelos como BERT utilizan la parte del Encoder del Transformer para comprender el texto de forma bidireccional, GPT es una arquitectura Decoder-only (solo decodificador) diseñada para la predicción autorregresiva del siguiente token. En este blog, desmitificaremos cómo funciona el Transformer GPT, profundizaremos en el mecanismo de autoatención causal y lo implementaremos en código.
1. El bucle de generación autorregresiva
En esencia, GPT es un modelo autorregresivo. Esto significa que para generar una secuencia de texto, predice el siguiente token uno por uno, utilizando los tokens que ya ha generado como contexto para la próxima predicción.
El flujo de trabajo sigue estos pasos:
- Entrada (Input): El modelo recibe una instrucción (prompt):
"Deep learning is". - Predicción: El modelo procesa este prompt y genera una distribución de probabilidad sobre todo su vocabulario. Selecciona el siguiente token:
"awesome". - Bucle (Loop): El nuevo token se agrega a la entrada, convirtiéndola en:
"Deep learning is awesome". Esta secuencia se convierte en la entrada para el siguiente paso. - Terminación: El proceso se repite hasta que el modelo genera un token especial de fin de secuencia (
[EOS]) o alcanza un límite de longitud predefinido.
2. Enmascaramiento causal: el corazón del decodificador
En un modelo que solo utiliza el codificador como BERT, cada token puede prestar atención a cualquier otro token, mirando tanto al pasado como al futuro. Sin embargo, para un modelo generativo que predice el siguiente token, mirar al futuro durante el entrenamiento sería “hacer trampa”.
Para evitar que el modelo mire los tokens futuros, GPT utiliza la Autoatención Causal (o autoatención enmascarada).
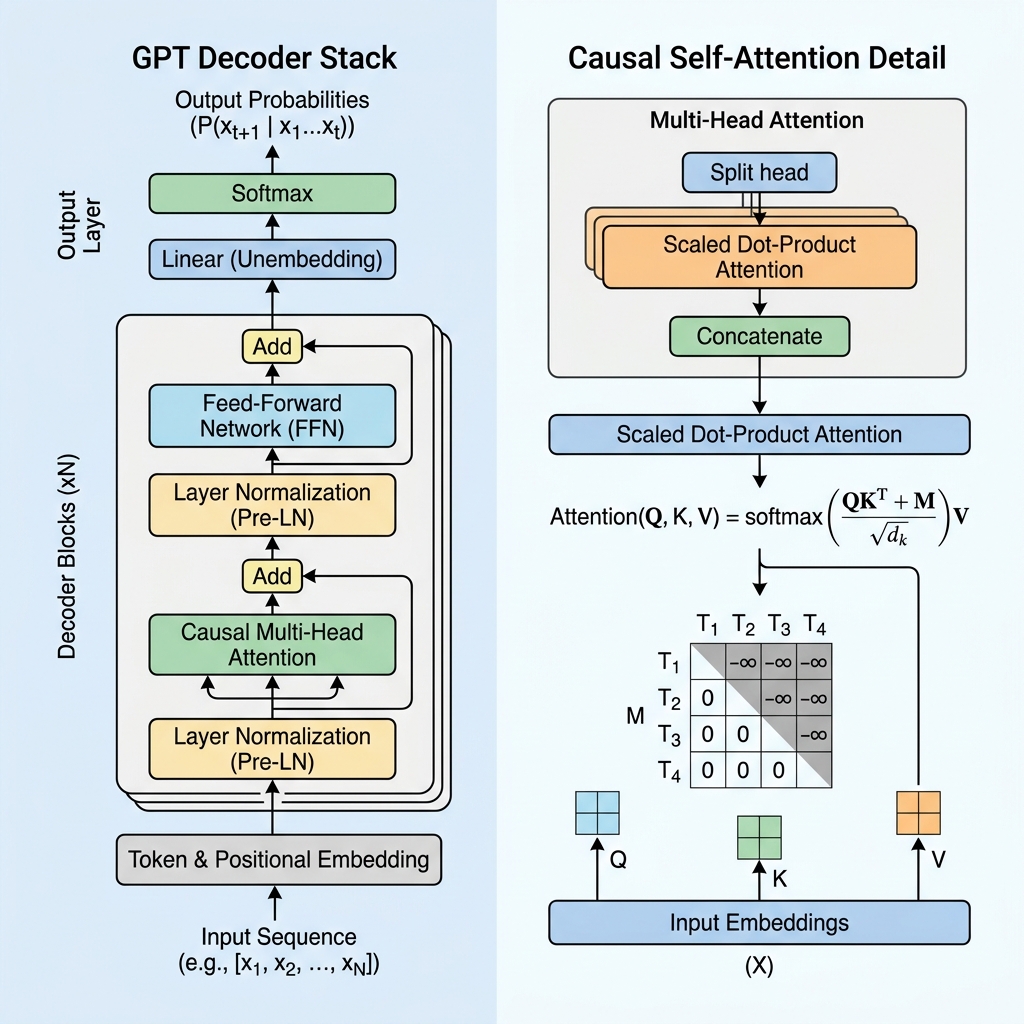
La matriz de máscara causal
Durante el cálculo de la autoatención, calculamos las puntuaciones de similitud entre tokens tomando el producto escalar de las consultas (Queries, $Q$) y las claves (Keys, $K$):
$$\text{Scores} = QK^T$$
Para imponer la causalidad, aplicamos una matriz de máscara $M$ donde todos los valores por encima de la diagonal se establecen en $-\infty$ (infinito negativo), y los valores en y por debajo de la diagonal son 0. Añadimos esta máscara a las puntuaciones antes de aplicar la función softmax:
$$\text{Masked Scores} = \frac{QK^T}{\sqrt{d_k}} + M$$
$$M = \begin{pmatrix} 0 & -\infty & -\infty & \dots & -\infty \\ 0 & 0 & -\infty & \dots & -\infty \\ 0 & 0 & 0 & \dots & -\infty \\ \vdots & \vdots & \vdots & \ddots & \vdots \\ 0 & 0 & 0 & \dots & 0 \end{pmatrix}$$
Cuando aplicamos la función softmax, $e^{-\infty}$ se convierte en $0$. Como consecuencia, los pesos de atención para cualquier token futuro se vuelven exactamente 0, haciendo que los tokens futuros sean invisibles para el token actual.
3. Bloques arquitectónicos principales de una capa GPT
Un modelo GPT consta de capas de decodificador Transformer apiladas. Cada capa contiene varios componentes cruciales:
A. Embeddings de entrada y codificación posicional
- Tokenización: El texto sin procesar se divide en tokens de subpalabras utilizando la codificación de pares de bytes (BPE).
- Token Embeddings: Cada token se asigna a un vector de alta dimensión.
- Learned Positional Embeddings: Dado que la autoatención no tiene un sentido del orden inherente, GPT añade vectores de embeddings posicionales aprendidos a los embeddings de tokens, lo que permite al modelo conocer la posición de cada token en la secuencia.
B. Normalización previa a la capa (Pre-LN)
A diferencia de la arquitectura original del Transformer, que aplicaba la normalización de capa después de la adición residual (Post-LN), las arquitecturas GPT modernas aplican la normalización de capa antes de las capas de atención y de alimentación hacia adelante (feed-forward):
$$x_{l+1} = x_l + \text{Attention}(\text{LayerNorm}(x_l))$$
Pre-LN estabiliza los gradientes durante el entrenamiento, lo que permite el entrenamiento estable de redes muy profundas con cientos de miles de millones de parámetros.
C. Red de alimentación hacia adelante (Feed-Forward Network / FFN)
Tras el bloque de atención, la representación de cada token pasa por un perceptrón multicapa (MLP) que consta de dos transformaciones lineales y una función de activación (normalmente GeLU):
$$\text{FFN}(x) = \max(0, x W_1 + b_1) W_2 + b_2$$
4. Mecánica de muestreo (de Logits a Tokens)
El bloque decodificador final genera un vector de puntuaciones brutas llamadas Logits para cada posición. Convertimos estos logits en probabilidades utilizando la función softmax. Para controlar la aleatoriedad del texto generado, aplicamos parámetros durante el muestreo:
- Temperatura ($T$): Escala los logits antes de la softmax. Una temperatura más baja (p. ej., $T = 0.2$) hace que el modelo sea más determinista y enfocado, mientras que una temperatura más alta (p. ej., $T = 0.8$) aumenta la creatividad y la diversidad.
- Top-K: Limita las opciones del siguiente token a los $K$ tokens más probables.
- Top-P (Muestreo de núcleo / Nucleus Sampling): Acumula la distribución de probabilidad y elige del conjunto más pequeño de tokens cuya probabilidad acumulada supera $P$ (p. ej., $P = 0.9$).
5. Implementación en PyTorch de la Autoatención Causal
A continuación se presenta una implementación independiente en PyTorch que demuestra la autoatención causal con enmascaramiento causal:
import torch
import torch.nn as nn
import torch.nn.functional as F
class CausalSelfAttention(nn.Module):
def __init__(self, d_model, n_heads):
super().__init__()
assert d_model % n_heads == 0
self.d_model = d_model
self.n_heads = n_heads
self.d_k = d_model // n_heads
# Proyecciones para Query, Key y Value
self.q_proj = nn.Linear(d_model, d_model)
self.k_proj = nn.Linear(d_model, d_model)
self.v_proj = nn.Linear(d_model, d_model)
self.out_proj = nn.Linear(d_model, d_model)
def forward(self, x):
batch_size, seq_len, d_model = x.size()
# 1. Proyectar entradas a Q, K, V
Q = self.q_proj(x).view(batch_size, seq_len, self.n_heads, self.d_k).transpose(1, 2)
K = self.k_proj(x).view(batch_size, seq_len, self.n_heads, self.d_k).transpose(1, 2)
V = self.v_proj(x).view(batch_size, seq_len, self.n_heads, self.d_k).transpose(1, 2)
# 2. Calcular puntuaciones de atención brutas
scores = torch.matmul(Q, K.transpose(-2, -1)) / (self.d_k ** 0.5)
# 3. Crear y aplicar máscara causal
# Máscara triangular superior llena de infinito negativo
mask = torch.triu(torch.ones(seq_len, seq_len, device=x.device), diagonal=1).bool()
scores = scores.masked_fill(mask, float('-inf'))
# 4. Softmax convierte -inf en probabilidad 0
attn_weights = F.softmax(scores, dim=-1)
# 5. Calcular suma ponderada de valores y salida
context = torch.matmul(attn_weights, V)
context = context.transpose(1, 2).contiguous().view(batch_size, seq_len, d_model)
return self.out_proj(context)
# Ejecución de verificación rápida
if __name__ == "__main__":
# Tamaño de lote = 1, Longitud de secuencia = 4, Dimensión de modelo = 8, 2 cabezas
x = torch.randn(1, 4, 8)
attention_layer = CausalSelfAttention(d_model=8, n_heads=2)
output = attention_layer(x)
print("Forma de entrada (Input Shape):", x.shape)
print("Forma de salida (Output Shape):", output.shape)
6. Comparación arquitectónica
| Característica | BERT (solo Codificador) | GPT (solo Decodificador) | Transformer Original |
|---|---|---|---|
| Tarea Principal | Comprensión / Extracción | Generación / Síntesis | Traducción / Secuencia a Secuencia |
| Tipo de Atención | Autoatención bidireccional | Autoatención causal enmascarada | Atenciones cruzadas bidireccionales y causales |
| Enmascaramiento | Tokens enmascarados ([MASK]) |
Enmascaramiento triangular causal | Enmascaramiento causal en el decodificador |
| Procesamiento | Procesa toda la secuencia a la vez | Generación autorregresiva de tokens | El codificador procesa una vez, el decodificador genera |
Conclusión
Al descartar el codificador y centrarse por completo en la autoatención enmascarada causal, GPT abrió el camino hacia la escala generativa. La regla simple de predecir el siguiente token, combinada con un entrenamiento en paralelo masivo, permite a los modelos GPT capturar ricas representaciones lógicas, de programación y de lenguaje, formando la base de la IA cognitiva moderna.