جی پی ٹی ٹرانسفارمر کیسے کام کرتا ہے؟ کازل سیلف اٹینشن کی تفصیل
حالیہ برسوں میں، جنریٹو پری ٹرینڈ ٹرانسفارمرز (GPT) نے مصنوعی ذہانت کی دنیا میں ایک انقلاب برپا کر دیا ہے۔ کوڈنگ کے معاونین سے لے کر گفتگو کرنے والے سافٹ وئیرز تک، آج کی سب سے جدید ترین جنریٹو ایپلی کیشنز جی پی ٹی ماڈلز پر ہی چلتی ہیں۔ لیکن یہ ٹیکنالوجی اصل میں کیسے کام کرتی ہے؟
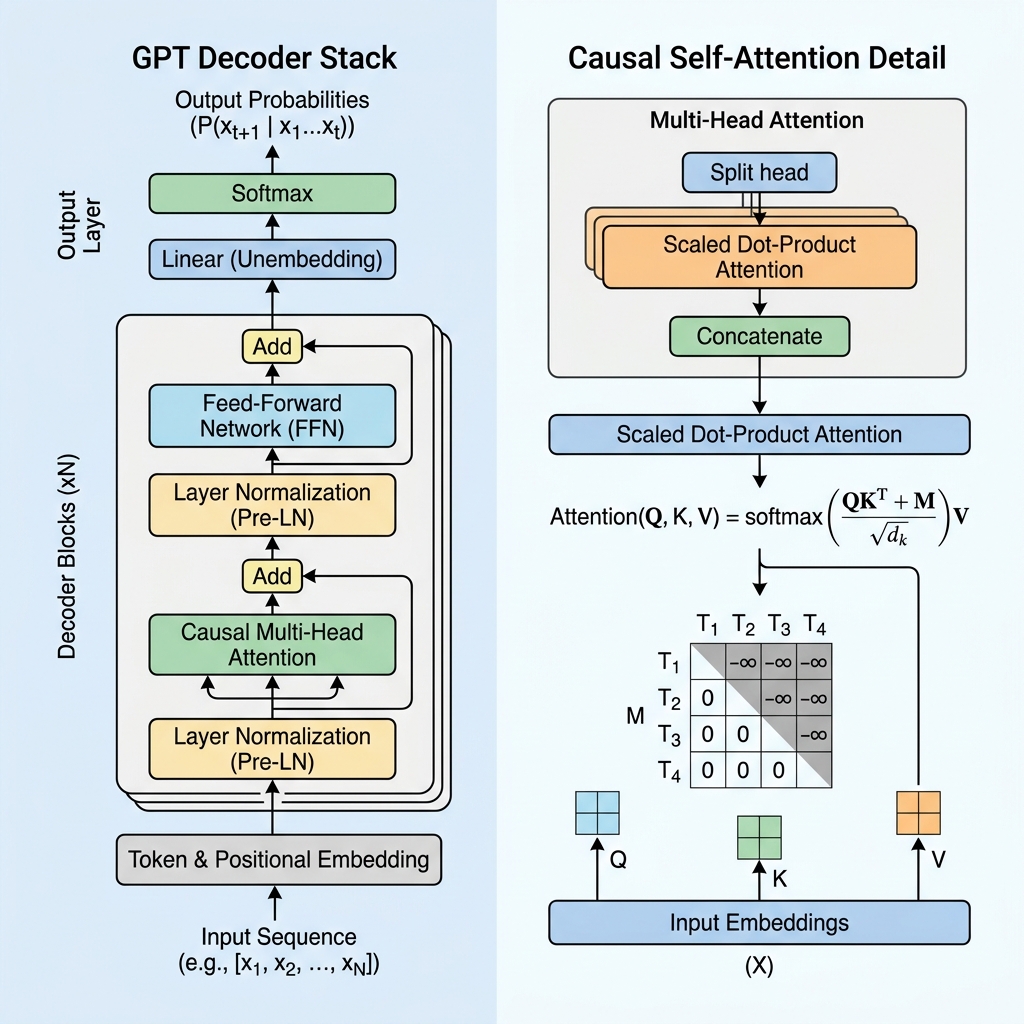
جبکہ BERT جیسے ماڈل متن کو دو طرفہ طور پر سمجھنے کے لیے ٹرانسفارمر کے انکوڈر (Encoder) والے حصے کا استعمال کرتے ہیں، GPT ایک ڈیکوڈر اونلی (Decoder-only) آرکیٹیکچر ہے جو آٹوریگریسیو (autoregressive)، یعنی اگلے ٹوکن کی پیش گوئی کرنے کے لیے ڈیزائن کیا گیا ہے۔ اس بلاگ میں، ہم ڈی کوڈ کریں گے کہ جی پی ٹی ٹرانسفارمر کیسے کام کرتا ہے، کازل سیلف اٹینشن (causal self-attention) میکانزم کا گہرائی سے جائزہ لیں گے، اور اسے کوڈ کے ذریعے عملی جامہ پہنائیں گے۔
1. آٹوریگریسیو جنریشن لوپ (Autoregressive Loop)
بنیادی طور پر، جی پی ٹی ایک آٹوریگریسیو ماڈل ہے۔ اس کا مطلب ہے کہ متن کی ترتیب بنانے کے لیے، یہ ایک ایک کر کے اگلے ٹوکن کی پیش گوئی کرتا ہے، اور جو ٹوکن یہ پہلے ہی تیار کر چکا ہوتا ہے انہیں اگلی پیش گوئی کے لیے سیاق و سباق (context) کے طور پر استعمال کرتا ہے۔
اس کا طریقہ کار ان مراحل پر مشتمل ہوتا ہے:
- ان پٹ (Input): ماڈل کو ایک جملہ ملتا ہے:
"Deep learning is"۔ - پیش گوئی (Prediction): ماڈل اس پرامپٹ پر کام کرتا ہے اور اپنی پوری لغت (vocabulary) پر امکانی تقسیم (probability distribution) تیار کرتا ہے۔ یہ اگلا ٹوکن منتخب کرتا ہے:
"awesome"۔ - لوپ (Loop): نیا ٹوکن پرانے ان پٹ کے ساتھ جوڑ دیا جاتا ہے، جس سے یہ جملہ بن جاتا ہے:
"Deep learning is awesome"۔ اب یہ جملہ اگلے مرحلے کے لیے ان پٹ بن جاتا ہے۔ - خاتمہ (Termination): یہ عمل تب تک دہرایا جاتا ہے جب تک کہ ماڈل ایک خاص اینڈ آف سیکوئنس ٹوکن (
[EOS]) تیار نہ کر لے یا پہلے سے طے شدہ لمبائی کی حد تک نہ پہنچ جائے۔
2. کازل ماسکنگ (Causal Masking): ڈیکوڈر کا دل
انکوڈر اونلی ماڈل جیسے کہ BERT میں، ہر ٹوکن ماضی اور مستقبل دونوں طرف دیکھ کر جملے کے ہر دوسرے ٹوکن پر توجہ مرکوز کر سکتا ہے۔ تاہم، ایک ایسے جنریٹو ماڈل کے لیے جو اگلے ٹوکن کی پیش گوئی کر رہا ہو، ٹریننگ کے دوران مستقبل کے ٹوکنز کو دیکھنا “دھوکہ دہی” کے برابر ہوگا۔
ماڈل کو مستقبل کے ٹوکنز دیکھنے سے روکنے کے لیے، GPT کازل سیلف اٹینشن (Causal Self-Attention) یا ماسکڈ سیلف اٹینشن کا استعمال کرتا ہے۔
کازل ماسک میٹرکس
سیلف اٹینشن کے حساب کتاب کے دوران، ہم Queries ($Q$) اور Keys ($K$) کا ڈاٹ پروڈکٹ لے کر ٹوکنز کے درمیان مماثلت کے اسکور کا حساب لگاتے ہیں:
$$\text{Scores} = QK^T$$
اس عمل میں سب کو ترتیب کے مطابق رکھنے کے لیے، ہم ایک ماسک میٹرکس $M$ کا اطلاق کرتے ہیں جہاں ترچھی لکیر (diagonal) سے اوپر کی تمام اقدار کو $-\infty$ (منفی لامتناہی) پر سیٹ کیا جاتا ہے، اور ترچھی لکیر پر اور اس سے نیچے کی اقدار 0 ہوتی ہیں۔ ہم سافٹ میکس (softmax) فنکشن کو لاگو کرنے سے پہلے اس ماسک کو اسکورز میں شامل کرتے ہیں:
$$\text{Masked Scores} = \frac{QK^T}{\sqrt{d_k}} + M$$
$$M = \begin{pmatrix} 0 & -\infty & -\infty & \dots & -\infty \\ 0 & 0 & -\infty & \dots & -\infty \\ 0 & 0 & 0 & \dots & -\infty \\ \vdots & \vdots & \vdots & \ddots & \vdots \\ 0 & 0 & 0 & \dots & 0 \end{pmatrix}$$
جب ہم سافٹ میکس فنکشن کا اطلاق کرتے ہیں، تو $e^{-\infty}$ صفر (0) بن جاتا ہے۔ نتیجتاً، مستقبل کے کسی بھی ٹوکن کے لیے اٹینشن کی ویلیوز بالکل 0 ہو جاتی ہیں، جس سے مستقبل کے ٹوکن موجودہ ٹوکن کے لیے پوشیدہ ہو جاتے ہیں۔
3. جی پی ٹی لیئر کے بنیادی اجزاء
ایک جی پی ٹی ماڈل ٹرانسفارمر ڈیکوڈر لیئرز کے ایک ڈھیر پر مشتمل ہوتا ہے۔ ہر لیئر میں کئی اہم اجزاء ہوتے ہیں:
الف۔ ان پٹ ایمبیڈنگز اور پوزیشن کی معلومات (Embeddings & Positional Encoding)
- ٹوکنائزیشن (Tokenization): خام متن کو بائٹ پیئر انکوڈنگ (BPE) کا استعمال کرتے ہوئے چھوٹے ٹوکنز میں تقسیم کیا جاتا ہے۔
- ٹوکن ایمبیڈنگز (Token Embeddings): ہر ٹوکن کو ایک کثیر جہتی ویکٹر پر میپ کیا جاتا ہے۔
- سیکھی ہوئی پوزیشن ایمبیڈنگز: چونکہ سیلف اٹینشن میں ترتیب کا کوئی فطری احساس نہیں ہوتا، اس لیے GPT ٹوکن ایمبیڈنگز میں سیکھے ہوئے پوزیشنی ویکٹرز کو شامل کرتا ہے، جس سے ماڈل کو معلوم ہوتا ہے کہ جملے میں ہر ٹوکن کس پوزیشن پر ہے۔
ب. پری لیئر نارملائزیشن (Pre-Layer Normalization / Pre-LN)
اصل ٹرانسفارمر آرکیٹیکچر کے برعکس، جو بقایا اضافے (residual addition) کے بعد لیئر نارملائزیشن کو لاگو کرتا تھا (Post-LN), جدید جی پی ٹی ماڈلز اٹینشن اور فیڈ فارورڈ لیئرز سے پہلے لیئر نارملائزیشن لاگو کرتے ہیں:
$$x_{l+1} = x_l + \text{Attention}(\text{LayerNorm}(x_l))$$
Pre-LN ٹریننگ کے دوران توازن کو برقرار رکھتا ہے، جس سے سیکڑوں ارب پیرامیٹرز پر مشتمل انتہائی گہرے نیٹ ورکس کی مستحکم ٹریننگ ممکن ہوتی ہے۔
ج. فیڈ فارورڈ نیٹ ورک (Feed-Forward Network / FFN)
اٹینشن بلاک کے بعد، ہر ٹوکن کی نمائندگی ایک ملٹی لیئر پرسیپٹرون (MLP) سے گزرتی ہے جو دو لکیری تبدیلیوں (linear transformations) اور ایک ایکٹیویشن فنکشن (عام طور پر GeLU) پر مشتمل ہوتی ہے:
$$\text{FFN}(x) = \max(0, x W_1 + b_1) W_2 + b_2$$
4. سیمپلنگ کے طریقے (لاگٹس سے ٹوکنز تک)
آخری ڈیکوڈر بلاک ہر پوزیشن کے لیے خام اسکورز کا ایک ویکٹر آؤٹ پٹ کرتا ہے جسے Logits کہا جاتا ہے۔ ہم سافٹ میکس فنکشن کا استعمال کرتے ہوئے ان لاگٹس کو امکانات (probabilities) میں تبدیل کرتے ہیں۔ تیار کردہ متن کی تخلیقی صلاحیت کو کنٹرول کرنے کے لیے، ہم سیمپلنگ کے دوران مختلف پیرامیٹرز کا استعمال کرتے ہیں:
- ٹمپریچر ($T$): سافٹ میکس سے پہلے لاگٹس کے اسکیل کو تبدیل کرتا ہے۔ کم ٹمپریچر (مثلاً $T = 0.2$) ماڈل کو زیادہ یقینی اور فوکسڈ بناتا ہے، جبکہ زیادہ ٹمپریچر (مثلاً $T = 0.8$) تنوع اور تخلیقی صلاحیت کو بڑھاتا ہے۔
- Top-K: اگلے ٹوکن کے انتخاب کو سب سے زیادہ امکانی $K$ ٹوکنز تک محدود کرتا ہے۔
- Top-P (Nucleus Sampling): امکانی تقسیم کو جمع کرتا ہے اور ان ٹوکنز کے سب سے چھوٹے سیٹ میں سے انتخاب کرتا ہے جن کا مجموعی احتمال $P$ (مثلاً $P = 0.9$) سے زیادہ ہو جاتا ہے۔
5. پائیتھون اور PyTorch میں کازل سیلف اٹینشن کا عملی کوڈ
ذیل میں PyTorch میں ایک مکمل کوڈ دیا گیا ہے جو کازل ماسکنگ کے ساتھ کازل سیلف اٹینشن کو ظاہر کرتا ہے:
import torch
import torch.nn as nn
import torch.nn.functional as F
class CausalSelfAttention(nn.Module):
def __init__(self, d_model, n_heads):
super().__init__()
assert d_model % n_heads == 0
self.d_model = d_model
self.n_heads = n_heads
self.d_k = d_model // n_heads
# پروژیکشنز برائے Query, Key اور Value
self.q_proj = nn.Linear(d_model, d_model)
self.k_proj = nn.Linear(d_model, d_model)
self.v_proj = nn.Linear(d_model, d_model)
self.out_proj = nn.Linear(d_model, d_model)
def forward(self, x):
batch_size, seq_len, d_model = x.size()
# 1. ان پٹ کو Q, K, V پر پروجیکٹ کریں
Q = self.q_proj(x).view(batch_size, seq_len, self.n_heads, self.d_k).transpose(1, 2)
K = self.k_proj(x).view(batch_size, seq_len, self.n_heads, self.d_k).transpose(1, 2)
V = self.v_proj(x).view(batch_size, seq_len, self.n_heads, self.d_k).transpose(1, 2)
# 2. اٹینشن اسکورز کا حساب لگائیں
scores = torch.matmul(Q, K.transpose(-2, -1)) / (self.d_k ** 0.5)
# 3. کازل ماسک بنائیں اور لاگو کریں
# اوپری تکون والا ماسک جو منفی لامتناہی سے بھرا ہوا ہے
mask = torch.triu(torch.ones(seq_len, seq_len, device=x.device), diagonal=1).bool()
scores = scores.masked_fill(mask, float('-inf'))
# 4. سافٹ میکس منفی لامتناہی کو 0 کے احتمال میں بدل دیتا ہے
attn_weights = F.softmax(scores, dim=-1)
# 5. ویلیوز کا وزنی مجموعہ لیں اور آؤٹ پٹ حاصل کریں
context = torch.matmul(attn_weights, V)
context = context.transpose(1, 2).contiguous().view(batch_size, seq_len, d_model)
return self.out_proj(context)
# فوری تصدیقی کوڈ
if __name__ == "__main__":
# بیچ سائز = 1، ترتیب کی لمبائی = 4، ماڈل جہت = 8، 2 اٹینشن ہیڈز
x = torch.randn(1, 4, 8)
attention_layer = CausalSelfAttention(d_model=8, n_heads=2)
output = attention_layer(x)
print("ان پٹ شیپ (Input Shape):", x.shape)
print("آؤٹ پٹ شیپ (Output Shape):", output.shape)
6. آرکیٹیکچر کا موازنہ
| خصوصیت | BERT (انکوڈر اونلی) | GPT (ڈیکوڈر اونلی) | اصل ٹرانسفارمر |
|---|---|---|---|
| بنیادی کام | سمجھنا / معلومات نکالنا | جنریشن / ترکیب | ترجمہ / سیکوئنس ٹو سیکوئنس |
| توجہ کی قسم | دو طرفہ سیلف اٹینشن | کازل ماسکڈ سیلف اٹینشن | دو طرفہ اور کازل کراس اٹینشن |
| ماسکنگ | ماسکڈ ٹوکنز ([MASK]) |
کازل تکون ماسکنگ | ڈیکوڈر میں کازل ماسکنگ |
| پروسیسنگ | ایک ہی وقت میں پوری ترتیب پر کارروائی | آٹوریگریسیو ٹوکن جنریشن | انکوڈر ایک بار پروسیس کرتا ہے، ڈیکوڈر جنریٹ کرتا ہے |
نتیجہ
انکوڈر کو چھوڑ کر اور مکمل طور پر کازل ماسکڈ سیلف اٹینشن پر توجہ مرکوز کر کے، GPT نے تخلیقی ماڈلنگ کے راستے کھول دیے۔ اگلے ٹوکن کی پیش گوئی کرنے کا آسان اصول، جب بڑے پیمانے پر متوازی تربیت کے ساتھ جوڑا جاتا ہے، تو جی پی ٹی ماڈلز کو منطق، کوڈنگ اور زبان کی بھرپور نمائندگی حاصل کرنے کی اجازت دیتا ہے، جو جدید علمی AI کی بنیاد بناتا ہے۔