جیپیتی ترانسفورمر چگونه کار میکند؟ توضیح توجه خودکار علی (Causal Self-Attention)
جیپیتی ترانسفورمر چگونه کار میکند؟ توضیح توجه خودکار علی (Causal Self-Attention)
در سالهای اخیر، ترانسفورمرهای تولیدی پیشآموزشدیده (GPT) هوش مصنوعی را متحول کردهاند. از دستیاران کدنویسی گرفته تا عوامل گفتگوی هوشمند، امروزه مدلهای مبتنی بر GPT پیشرفتهترین برنامههای کاربردی تولیدی را هدایت میکنند. اما این فناوری در واقع چگونه کار میکند؟
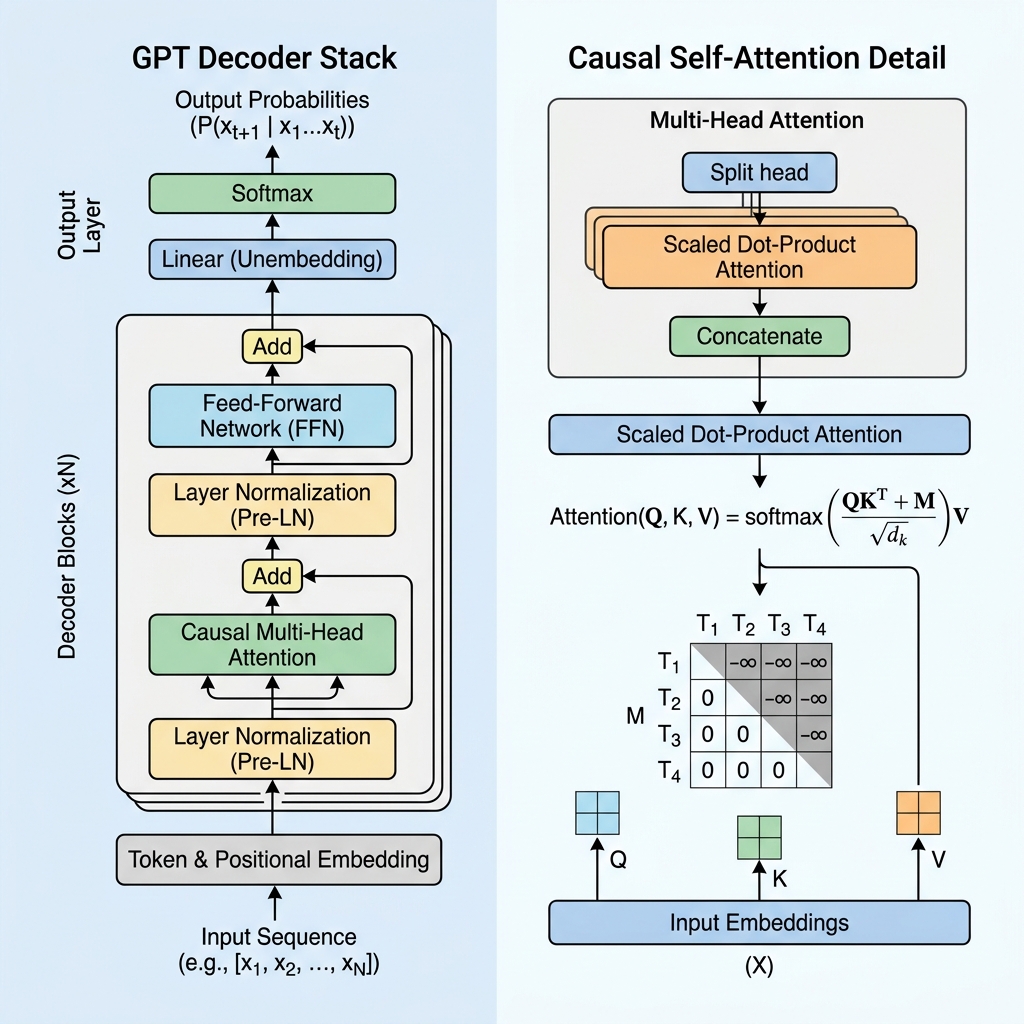
در حالی که مدلهایی مانند BERT از بخش رمزگذار (Encoder) ترانسفورمر برای درک دوطرفه متن استفاده میکنند، GPT یک معماری فقط رمزگشا (Decoder-only) است که برای پیشبینی خودکار بازگشتی توکن بعدی طراحی شده است. در این وبلاگ، نحوه کارکرد ترانسفورمر GPT را ابهامزدایی میکنیم، به اعماق مکانیسم توجه خودکار علی (causal self-attention) نفوذ میکنیم و آن را در کد پیادهسازی میکنیم.
۱. حلقه تولید خودکار بازگشتی (Autoregressive Loop)
در هسته خود، GPT یک مدل خودکار بازگشتی است. این بدان معناست که برای تولید یک دنباله از متن، توکن بعدی را یکی یکی پیشبینی میکند و از توکنهایی که قبلاً تولید کرده است به عنوان زمینه (context) برای پیشبینی بعدی استفاده میکند.
گردش کار مراحل زیر را دنبال میکند:
۱. ورودی (Input): مدل یک پرامپت دریافت میکند: "Deep learning is".
۲. پیشبینی (Prediction): مدل این پرامپت را پردازش میکند و یک توزیع احتمال را در کل دایره واژگان خود خروجی میدهد. توکن بعدی را نمونهبرداری میکند: "awesome".
۳. حلقه (Loop): توکن جدید به ورودی ضمیمه میشود و آن را به صورت زیر در میآورد: "Deep learning is awesome". این دنباله به ورودی مرحله بعدی تبدیل میشود.
۴. پایان (Termination): این فرآیند تکرار میشود تا زمانی که مدل یک توکن ویژه پایان دنباله ([EOS]) را خروجی دهد یا به محدودیت طول از پیش تعریفشده برسد.
۲. ماسک علی (Causal Masking): قلب دکودر
در یک مدل فقط رمزگذار مانند BERT، هر توکن میتواند به هر توکن دیگری توجه کند و هم به گذشته و هم به آینده نگاه کند. با این حال، برای یک مدل تولیدی که توکن بعدی را پیشبینی میکند، نگاه کردن به آینده در طول آموزش “تقلب” محسوب میشود.
برای جلوگیری از نگاه کردن مدل به توکنهای آینده، GPT از توجه خودکار علی (Causal Self-Attention) یا توجه خودکار ماسکشده استفاده میکند.
ماتریس ماسک علی
در طول محاسبات توجه خودکار، ما با گرفتن ضرب داخلی پرسوجوها ($Q$) و کلیدها ($K$)، امتیازات شباهت بین توکنها را محاسبه میکنیم:
$$\text{Scores} = QK^T$$
برای اعمال علیت، ما یک ماتریس ماسک $M$ را اعمال میکنیم که در آن تمام مقادیر بالای قطر روی $-\infty$ (منهای بینهایت) تنظیم میشوند و مقادیر روی قطر و زیر آن 0 هستند. ما این ماسک را قبل از اعمال تابع softmax به امتیازات اضافه میکنیم:
$$\text{Masked Scores} = \frac{QK^T}{\sqrt{d_k}} + M$$
$$M = \begin{pmatrix} 0 & -\infty & -\infty & \dots & -\infty \\ 0 & 0 & -\infty & \dots & -\infty \\ 0 & 0 & 0 & \dots & -\infty \\ \vdots & \vdots & \vdots & \ddots & \vdots \\ 0 & 0 & 0 & \dots & 0 \end{pmatrix}$$
وقتی تابع softmax را اعمال میکنیم، $e^{-\infty}$ تبدیل به $0$ میشود. در نتیجه، وزنهای توجه برای هر توکن آینده دقیقاً 0 میشود و توکنهای آینده را برای توکن فعلی نامرئی میکند.
۳. بلوکهای معماری اصلی یک لایه GPT
یک مدل GPT از لایههای دکودر ترانسفورمر روی هم قرار گرفته تشکیل شده است. هر لایه شامل چندین جزء حیاتی است:
الف. امبدینگهای ورودی و کدگذاری موقعیتی (Embeddings & Positional Encoding)
- توکنسازی: متن خام با استفاده از کدگذاری جفت بایت (BPE) به توکنهای فرعی کلمات تقسیم میشود.
- امبدینگهای توکن (Token Embeddings): هر توکن به یک وکتور چندبعدی نگاشت میشود.
- امبدینگهای موقعیتی یادگیریشده: از آنجایی که توجه خودکار حس ذاتی از ترتیب ندارد، GPT وکتورهای امبدینگ موقعیتی یادگیریشده را به امبدینگهای توکن اضافه میکند و به مدل اجازه میدهد موقعیت هر توکن را در دنباله بداند.
ب. نرمالسازی پیشلایه (Pre-Layer Normalization / Pre-LN)
برخلاف معماری ترانسفورمر اصلی که نرمالسازی لایه را بعد از افزودن باقیمانده اعمال میکرد (Post-LN)، معماریهای مدرن GPT نرمالسازی لایه را قبل از لایههای توجه و پیشرو اعمال میکنند:
$$x_{l+1} = x_l + \text{Attention}(\text{LayerNorm}(x_l))$$
Pre-LN گرادیانها را در طول آموزش پایدار میکند و امکان آموزش پایدار شبکههای بسیار عمیق با صدها میلیارد پارامتر را فراهم میکند.
ج. شبکه پیشرو (Feed-Forward Network / FFN)
به دنبال بلوک توجه، نمایش هر توکن از یک پرسپترون چند لایه (MLP) عبور میکند که شامل دو تبدیل خطی و یک تابع فعالساز (معمولاً GeLU) است:
$$\text{FFN}(x) = \max(0, x W_1 + b_1) W_2 + b_2$$
۴. مکانیک نمونهبرداری (از لاگیتها به توکنها)
بلوک دکودر نهایی یک وکتور از امتیازات خام به نام Logits را برای هر موقعیت خروجی میدهد. ما این لاگیتها را با استفاده از تابع softmax به احتمالات تبدیل میکنیم. برای کنترل تصادفی بودن متن تولید شده، پارامترهایی را در حین نمونهبرداری اعمال میکنیم:
- دما ($T$): لاگیتها را قبل از softmax مقیاسبندی میکند. دمای پایینتر (به عنوان مثال، $T = 0.2$) مدل را قطعیتر و متمرکزتر میکند، در حالی که دمای بالاتر (به عنوان مثال، $T = 0.8$) خلاقیت و تنوع را افزایش میدهد.
- Top-K: گزینههای توکن بعدی را به $K$ توکن محتملتر محدود میکند.
- Top-P (نمونهبرداری هسته): توزیع احتمال را جمع میکند و از کوچکترین مجموعه توکنهایی انتخاب میکند که احتمال تجمعی آنها از $P$ (به عنوان مثال، $P = 0.9$) بیشتر شود.
۵. پیادهسازی توجه خودکار علی در PyTorch
در زیر یک پیادهسازی مستقل در PyTorch آورده شده است که توجه خودکار علی را با ماسک علی نشان میدهد:
import torch
import torch.nn as nn
import torch.nn.functional as F
class CausalSelfAttention(nn.Module):
def __init__(self, d_model, n_heads):
super().__init__()
assert d_model % n_heads == 0
self.d_model = d_model
self.n_heads = n_heads
self.d_k = d_model // n_heads
# پروجکشنها برای Query، Key و Value
self.q_proj = nn.Linear(d_model, d_model)
self.k_proj = nn.Linear(d_model, d_model)
self.v_proj = nn.Linear(d_model, d_model)
self.out_proj = nn.Linear(d_model, d_model)
def forward(self, x):
batch_size, seq_len, d_model = x.size()
# ۱. نگاشت ورودیها به Q, K, V
Q = self.q_proj(x).view(batch_size, seq_len, self.n_heads, self.d_k).transpose(1, 2)
K = self.k_proj(x).view(batch_size, seq_len, self.n_heads, self.d_k).transpose(1, 2)
V = self.v_proj(x).view(batch_size, seq_len, self.n_heads, self.d_k).transpose(1, 2)
# ۲. محاسبه امتیازات خام توجه
scores = torch.matmul(Q, K.transpose(-2, -1)) / (self.d_k ** 0.5)
# ۳. ایجاد و اعمال ماسک علی
# ماسک مثلثی بالا پر شده با منهای بینهایت
mask = torch.triu(torch.ones(seq_len, seq_len, device=x.device), diagonal=1).bool()
scores = scores.masked_fill(mask, float('-inf'))
# ۴. تابع Softmax منهای بینهایت را به احتمال ۰ تبدیل میکند
attn_weights = F.softmax(scores, dim=-1)
# ۵. محاسبه مجموع وزنی مقادیر و خروجی
context = torch.matmul(attn_weights, V)
context = context.transpose(1, 2).contiguous().view(batch_size, seq_len, d_model)
return self.out_proj(context)
# اجرای راستیآزمایی سریع
if __name__ == "__main__":
# اندازه دسته = 1، طول دنباله = 4، بعد مدل = 8، تعداد سر = 2
x = torch.randn(1, 4, 8)
attention_layer = CausalSelfAttention(d_model=8, n_heads=2)
output = attention_layer(x)
print("شکل ورودی (Input Shape):", x.shape)
print("شکل خروجی (Output Shape):", output.shape)
۶. مقایسه معماریها
| ویژگی | BERT (فقط رمزگذار) | GPT (فقط رمزگشا) | ترانسفورمر اصلی |
|---|---|---|---|
| وظیفه اصلی | درک / استخراج | تولید / سنتز | ترجمه / دنباله به دنباله |
| نوع توجه | توجه خودکار دوطرفه | توجه خودکار علی ماسکشده | توجه متقاطع دوطرفه و علی |
| ماسک کردن | توکنهای ماسکشده ([MASK]) |
ماسک کردن مثلثی علی | ماسک کردن علی در رمزگشا |
| پردازش | پردازش کل دنباله در یک مرحله | تولید خودکار بازگشتی توکنها | رمزگذار یک بار پردازش میکند، رمزگشا تولید میکند |
نتیجهگیری
با کنار گذاشتن رمزگذار و تمرکز کامل بر توجه خودکار ماسکشده علی، GPT مسیر را برای مقیاسپذیری تولیدی هموار کرد. قانون ساده پیشبینی توکن بعدی، همراه با آموزش موازی عظیم، به مدلهای GPT اجازه میدهد تا نمایشهای غنی از منطق، کدنویسی و زبان را به تصویر بکشند و پایهای برای هوش مصنوعی شناختی مدرن ایجاد کنند.