Comment fonctionne le Transformer GPT : L'auto-attention causale expliquée
Ces dernières années, les modèles GPT (Generative Pre-trained Transformer) ont révolutionné l’intelligence artificielle. Des assistants de code aux agents conversationnels, les modèles basés sur GPT alimentent aujourd’hui les applications génératives les plus avancées. Mais comment fonctionne réellement cette technologie ?
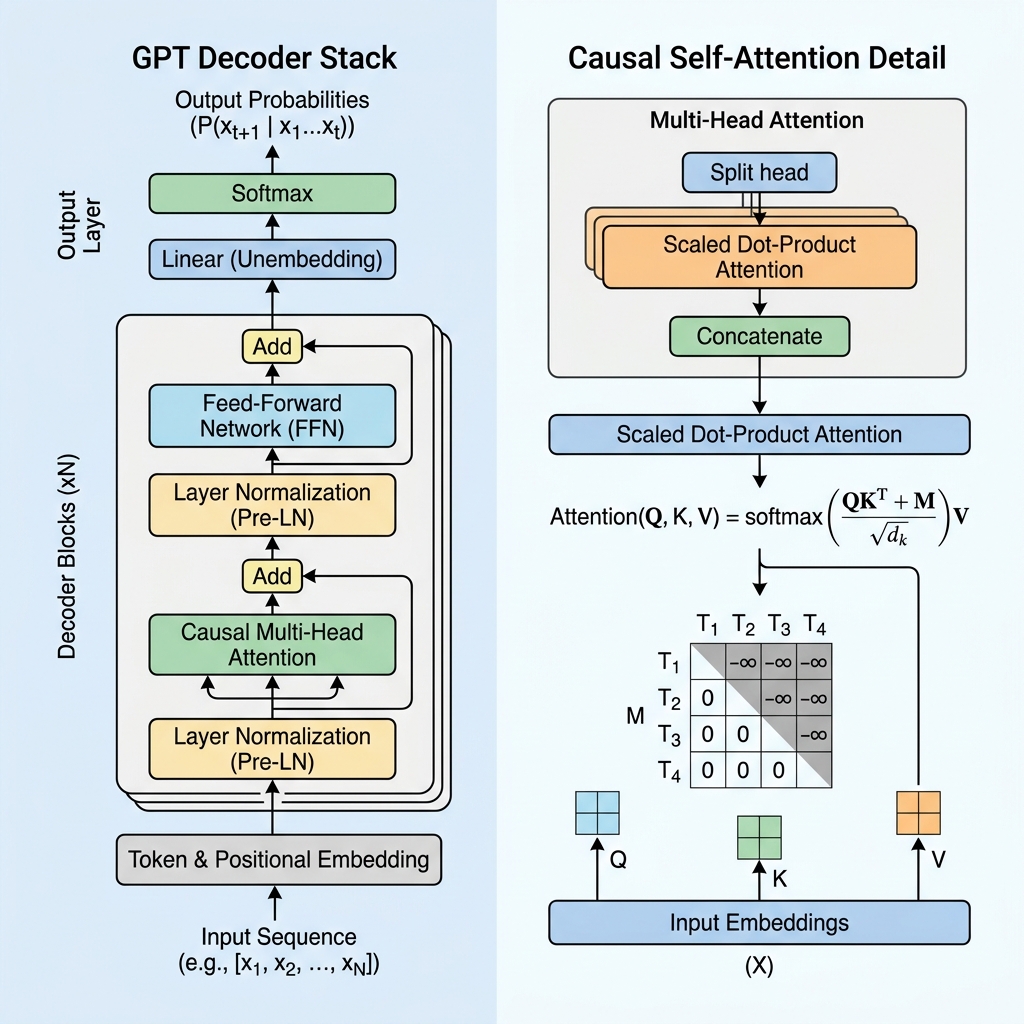
Alors que les modèles comme BERT utilisent la partie Encoder du Transformer pour comprendre le texte de manière bidirectionnelle, GPT est une architecture Decoder-only (décodeur uniquement) conçue pour la prédiction autorégressive du token suivant. Dans cet article, nous allons démystifier le fonctionnement du Transformer GPT, plonger dans le mécanisme d’auto-attention causale et l’implémenter en code.
1. La boucle de génération autorégressive
À la base, GPT est un modèle autorégressif. Cela signifie que pour générer une séquence de texte, il prédit le token suivant un par un, en utilisant les tokens qu’il a déjà générés comme contexte pour la prédiction suivante.
Le flux de travail suit ces étapes :
- Entrée (Input) : Le modèle reçoit une invite (prompt) :
"Deep learning is". - Prédiction : Le modèle traite ce prompt et génère une distribution de probabilité sur l’ensemble de son vocabulaire. Il échantillonne le token suivant :
"awesome". - Boucle (Loop) : Le nouveau token est ajouté à l’entrée, ce qui donne :
"Deep learning is awesome". Cette séquence devient l’entrée pour l’étape suivante. - Terminaison : Le processus se répète jusqu’à ce que le modèle génère un token spécial de fin de séquence (
[EOS]) ou atteigne une limite de longueur prédéfinie.
2. Le masquage causal : le cœur du décodeur
Dans un modèle basé uniquement sur l’encodeur comme BERT, chaque token peut prêter attention à tous les autres tokens, regardant à la fois vers le passé et le futur. Cependant, pour un modèle génératif prédisant le token suivant, regarder vers le futur pendant l’entraînement équivaudrait à « tricher ».
Pour empêcher le modèle de regarder les tokens futurs, GPT utilise l’Auto-attention causale (ou auto-attention masquée).
La matrice de masque causal
Pendant le calcul de l’auto-attention, nous calculons les scores de similitude entre les tokens en effectuant le produit scalaire des requêtes (Queries, $Q$) et des clés (Keys, $K$) :
$$\text{Scores} = QK^T$$
Pour imposer la causalité, nous appliquons une matrice de masque $M$ où toutes les valeurs au-dessus de la diagonale sont définies sur $-\infty$ (l’infini négatif), et les valeurs sur et sous la diagonale sont à 0. Nous ajoutons ce masque aux scores avant d’appliquer la fonction softmax :
$$\text{Masked Scores} = \frac{QK^T}{\sqrt{d_k}} + M$$
$$M = \begin{pmatrix} 0 & -\infty & -\infty & \dots & -\infty \\ 0 & 0 & -\infty & \dots & -\infty \\ 0 & 0 & 0 & \dots & -\infty \\ \vdots & \vdots & \vdots & \ddots & \vdots \\ 0 & 0 & 0 & \dots & 0 \end{pmatrix}$$
Lorsque nous appliquons la fonction softmax, $e^{-\infty}$ devient $0$. Par conséquent, les poids d’attention pour tous les tokens futurs deviennent exactement 0, rendant les tokens futurs invisibles pour le token actuel.
3. Les blocs architecturaux clés d’une couche GPT
Un modèle GPT est composé de couches de décodeur Transformer empilées. Chaque couche contient plusieurs composants essentiels :
A. Embeddings d’entrée et encodage positionnel
- Tokenisation : Le texte brut est découpé en tokens de sous-mots à l’aide de l’encodage par paires d’octets (BPE).
- Embeddings de tokens : Chaque token est mappé à un vecteur de haute dimension.
- Embeddings positionnels appris : Comme l’auto-attention n’a pas de sens inhérent de l’ordre, GPT ajoute des vecteurs d’embeddings positionnels appris aux embeddings de tokens, permettant au modèle de connaître la position de chaque token dans la séquence.
B. Pré-normalisation des couches (Pre-LN)
Contrairement à l’architecture Transformer originale, qui appliquait la normalisation des couches après l’ajout résiduel (Post-LN), les architectures GPT modernes appliquent la normalisation des couches avant les couches d’attention et de réseau de neurones à propagation avant (feed-forward) :
$$x_{l+1} = x_l + \text{Attention}(\text{LayerNorm}(x_l))$$
La Pre-LN stabilise les gradients pendant l’entraînement, permettant l’entraînement stable de réseaux très profonds comportant des centaines de milliards de paramètres.
C. Réseau de neurones à propagation avant (Feed-Forward Network / FFN)
Après le bloc d’attention, la représentation de chaque token passe par un perceptron multicouche (MLP) composé de deux transformations linéaires et d’une fonction d’activation (généralement GeLU) :
$$\text{FFN}(x) = \max(0, x W_1 + b_1) W_2 + b_2$$
4. La mécanique d’échantillonnage (des Logits aux Tokens)
Le bloc décodeur final produit un vecteur de scores bruts appelés Logits pour chaque position. Convertisons ces logits en probabilités à l’aide de la fonction softmax. Pour contrôler le caractère aléatoire du texte généré, nous appliquons des paramètres lors de l’échantillonnage :
- Température ($T$) : Échelle les logits avant la fonction softmax. Une température plus basse (par ex. $T = 0,2$) rend le modèle déterministe et concentré, tandis qu’une température plus élevée (par ex. $T = 0,8$) augmente la créativité et la diversité.
- Top-K : Limite les choix du token suivant aux $K$ tokens les plus probables.
- Top-P (Échantillonnage nucléaire / Nucleus Sampling) : Accumule la distribution de probabilité et choisit parmi le plus petit ensemble de tokens dont la probabilité cumulative dépasse $P$ (par ex. $P = 0,9$).
5. Implémentation PyTorch de l’auto-attention causale
Voici une implémentation PyTorch autonome illustrant l’auto-attention causale avec un masquage causal :
import torch
import torch.nn as nn
import torch.nn.functional as F
class CausalSelfAttention(nn.Module):
def __init__(self, d_model, n_heads):
super().__init__()
assert d_model % n_heads == 0
self.d_model = d_model
self.n_heads = n_heads
self.d_k = d_model // n_heads
# Projections pour Query, Key et Value
self.q_proj = nn.Linear(d_model, d_model)
self.k_proj = nn.Linear(d_model, d_model)
self.v_proj = nn.Linear(d_model, d_model)
self.out_proj = nn.Linear(d_model, d_model)
def forward(self, x):
batch_size, seq_len, d_model = x.size()
# 1. Projeter les entrées en Q, K, V
Q = self.q_proj(x).view(batch_size, seq_len, self.n_heads, self.d_k).transpose(1, 2)
K = self.k_proj(x).view(batch_size, seq_len, self.n_heads, self.d_k).transpose(1, 2)
V = self.v_proj(x).view(batch_size, seq_len, self.n_heads, self.d_k).transpose(1, 2)
# 2. Calculer les scores d'attention bruts
scores = torch.matmul(Q, K.transpose(-2, -1)) / (self.d_k ** 0.5)
# 3. Créer et appliquer le masque causal
# Masque triangulaire supérieur rempli d'infini négatif
mask = torch.triu(torch.ones(seq_len, seq_len, device=x.device), diagonal=1).bool()
scores = scores.masked_fill(mask, float('-inf'))
# 4. Softmax transforme -inf en probabilité 0
attn_weights = F.softmax(scores, dim=-1)
# 5. Calculer la somme pondérée des valeurs et retourner la sortie
context = torch.matmul(attn_weights, V)
context = context.transpose(1, 2).contiguous().view(batch_size, seq_len, d_model)
return self.out_proj(context)
# Test rapide de vérification
if __name__ == "__main__":
# Batch size = 1, Longueur de séquence = 4, Dimension du modèle = 8, 2 têtes
x = torch.randn(1, 4, 8)
attention_layer = CausalSelfAttention(d_model=8, n_heads=2)
output = attention_layer(x)
print("Forme d'entrée :", x.shape)
print("Forme de sortie :", output.shape)
6. Comparaison architecturale
| Caractéristique | BERT (décodeur uniquement) | GPT (décodeur uniquement) | Transformer d’origine |
|---|---|---|---|
| Tâche Principale | Compréhension / Extraction | Génération / Synthèse | Traduction / Séquence à Séquence |
| Type d’Attention | Auto-attention bidirectionnelle | Auto-attention causale masquée | Attention croisée bidirectionnelle & causale |
| Masquage | Tokens masqués ([MASK]) |
Masquage triangulaire causal | Masquage causal dans le décodeur |
| Traitement | Traite toute la séquence en même temps | Génération autorégressive de tokens | L’encodeur traite une fois, le décodeur génère |
Conclusion
En abandonnant l’encodeur pour se concentrer uniquement sur l’auto-attention causale masquée, GPT a ouvert la voie au passage à l’échelle génératif. La règle simple de prédiction du token suivant, combinée à un entraînement parallèle massif, permet aux modèles GPT de capturer des représentations riches de la logique, du code et du langage, formant ainsi le socle de l’IA cognitive moderne.