Geminiトランスフォーマーモデルの仕組み:GQA、SwiGLU、およびネイティブマルチモダリティ
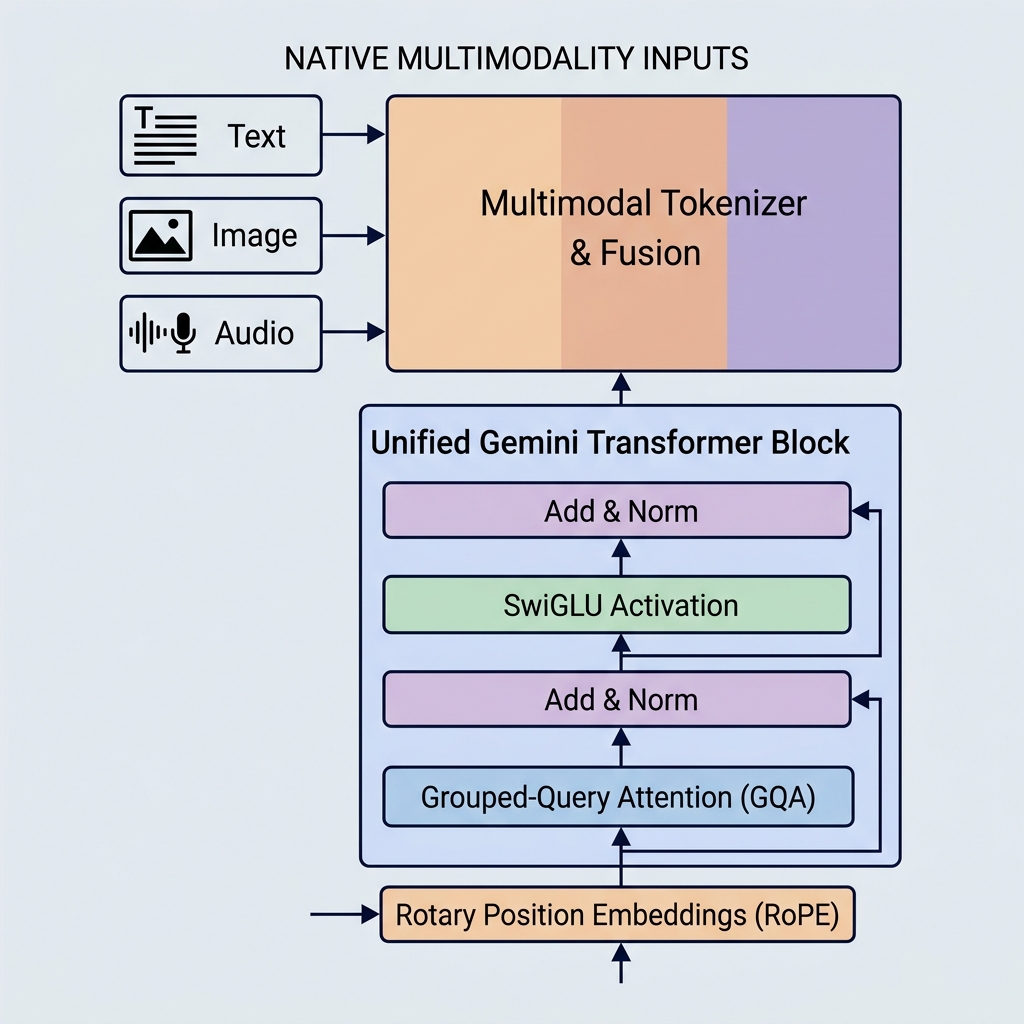
GoogleのGeminiモデルは、ネイティブマルチモダリティ、大規模なコンテキストウィンドウ、および主要なアーキテクチャの最適化を導入することにより、AI機能の新しいベンチマークを設定しました。GPT-3やBERTなどの古いモデルとは異なり、Geminiは初日から複数のタイプのデータを処理するように構築されており、非常に効率的なアテンションメカニズムを利用しています。
この記事では、Geminiトランスフォーマーモデルの主要なアーキテクチャの選択を分解し、それらが従来のアーキテクチャとどのように比較されるかを探索し、PyTorchでグループ化クエリ注意(GQA)およびSwiGLUフィードフォワードネットワークを実装します。
1. ネイティブマルチモダリティ(統一された埋め込み空間)
従来のAIシステムは、個別のモデルをつなぎ合わせることでマルチモーダルな動作を実現しています。たとえば、マッピングレイヤーやアダプターを使用して、画像エンコーダー(CLIPなど)やオーディオプロセッサー(Whisperなど)を事前トレーニング済みのテキストモデルとペアリングします。
Geminiは異なって構築されています。ネイティブにマルチモーダルであり、最初から異なるモダリティ(テキスト, コード, 画像, 音声, ビデオ)で同時にトレーニングされたことを意味します。
- 統一されたトークナイザー: 個別の前処理パイプラインの代わりに、異なる入力が共有の統一された潜在埋め込み空間のトークンに変換されます。
- クロスモーダルな推論: 表現空間が共有されているため、単一のデコーダーブロックは、まったく同じシーケンス内の視覚トークン、音声トークン、およびテキストトークンに注意を向けることができます。これにより、Geminiはビデオフレームの説明や音声のテキストへの直接翻訳などの複雑なタスクを実行できます。
2. グループ化クエリ注意(Grouped-Query Attention, GQA)
コンテキストウィンドウが拡張する(数百万トークンに達する)につれて、キー値(KV)キャッシュのメモリフットプリントが主要なサービングのボトルネックになります。
これを解決するために:
- マルチヘッドアテンション(MHA): すべてのクエリヘッド(Query head, $Q$)に、一致するキー(Key, $K$)および値(Value, $V$)ヘッドがあります。32個のヘッドがある場合、32セットのKVベクトルを保存する必要があります。
- マルチクエリアテンション(MQA): すべてのクエリヘッドが単一のキーおよび値ヘッドを共有します。これによりメモリは節約されますが、モデルの容量と出力の品質が低下します。
- グループ化クエリ注意(GQA): クエリヘッドがグループ化されます(たとえば、4ヘッドの8グループ)。各グループは単一のキーおよび値ヘッドを共有します。
$$\text{Scores} = QK^T \text{ computation in GQA groups Q heads to share a single KV pair}$$
GQAは中間層として機能し、MHA의 거의 모든 품질을 회복하면서도 MQAに近い推論速度とメモリ節約を提供します。
3. SwiGLU活性化関数
BERTや古いGPTモデルで使用されている標準のGeLU活性化の代わりに、GeminiはフィードフォワードブロックでSwiGLU(Swish-Gated Linear Unit)を利用しています。
ゲート付き線形ユニット(GLU)は、2つの線形変換の要素ごとの積として定義されるニューラルネットワーク層であり、その一方はシグモイド活性化によってゲートされます。SwiGLUは、シグモイドをSwish(またはSiLU)活性化に置き換えます。
$$\text{SwiGLU}(x) = \text{Swish}_\beta(x W) \otimes (x V)$$
ここで:
- $W$ と $V$ は線形投影の重み行列です。
- $\otimes$ は要素ごとの乗算を表します。
- $\text{Swish}(x) = x \cdot \sigma(\beta x)$ はゲートメカニズムとして機能します。
SwiGLUは、標準のGeLUやReLU活性化と比較して、トレーニング中の収ザーが速く、ダウンストリームタスクの精度が高くなることが示されています。
4. 回転位置埋め込み(Rotary Position Embeddings, RoPE)
入力トークン埋め込みに絶対的な位置埋め込みベクトルを追加したオリジナルのトランスフォーマーとは異なり、Geminiモデルは**回転位置埋め込み(RoPE)**を採用しています。
RoPEは、複素数空間でクエリ($Q$)およびキー($K$)ベクトルを回転させることによって位置情報をエンコードします。2Dベクトルの場合、回転は次のように定義されます。
$$R_{\Theta, m}^d x_m = \begin{pmatrix} \cos m\theta & -\sin m\theta \\ \sin m\theta & \cos m\theta \end{pmatrix} \begin{pmatrix} x_{m, 1} \\ x_{m, 2} \end{pmatrix}$$
この定式化により、位置 $m$ のクエリと位置 $n$ のキーの間のドット積は、それらの相対的な距離 $m - n$ にのみ依存することが保証されます。
$$\langle R_{\Theta, m}^d q_m, R_{\Theta, n}^d k_n \rangle = g(q, k, m - n)$$
RoPEにより、モデルは自然に長いシーケンス長に補外することができ、これは大規模なコンテキストウィンドウを処理するために重要です。
5. GeminiブロックのPyTorch実装
以下は、グループ化クエリ注意(GQA)およびSwiGLUフィードフォワードネットワークを実装する方法を示す完全なPyTorchモジュールです。
import torch
import torch.nn as nn
import torch.nn.functional as F
class SwiGLUFFN(nn.Module):
def __init__(self, d_model, hidden_dim):
super().__init__()
self.w_gate = nn.Linear(d_model, hidden_dim, bias=False)
self.w_val = nn.Linear(d_model, hidden_dim, bias=False)
self.w_down = nn.Linear(hidden_dim, d_model, bias=False)
def forward(self, x):
gate = F.silu(self.w_gate(x))
val = self.w_val(x)
return self.w_down(gate * val)
class GroupedQueryAttention(nn.Module):
def __init__(self, d_model, n_q_heads, n_kv_heads, d_k):
super().__init__()
self.n_q_heads = n_q_heads
self.n_kv_heads = n_kv_heads
self.d_k = d_k
self.group_size = n_q_heads // n_kv_heads
self.q_proj = nn.Linear(d_model, n_q_heads * d_k, bias=False)
self.k_proj = nn.Linear(d_model, n_kv_heads * d_k, bias=False)
self.v_proj = nn.Linear(d_model, n_kv_heads * d_k, bias=False)
self.out_proj = nn.Linear(n_q_heads * d_k, d_model, bias=False)
def forward(self, x):
batch, seq_len, _ = x.shape
q = self.q_proj(x).view(batch, seq_len, self.n_q_heads, self.d_k).transpose(1, 2)
k = self.k_proj(x).view(batch, seq_len, self.n_kv_heads, self.d_k).transpose(1, 2)
v = self.v_proj(x).view(batch, seq_len, self.n_kv_heads, self.d_k).transpose(1, 2)
k = k.repeat_interleave(self.group_size, dim=1)
v = v.repeat_interleave(self.group_size, dim=1)
scores = torch.matmul(q, k.transpose(-2, -1)) / (self.d_k ** 0.5)
mask = torch.triu(torch.ones(seq_len, seq_len, device=x.device), diagonal=1).bool()
scores = scores.masked_fill(mask, float('-inf'))
attn_weights = F.softmax(scores, dim=-1)
context = torch.matmul(attn_weights, v)
context = context.transpose(1, 2).contiguous().view(batch, seq_len, -1)
return self.out_proj(context)
6. アーキテクチャの比較:BERT vs. GPT vs. Gemini
| 機能 | BERT (エンコーダー) | GPT (デコーダー) | Gemini (マルチモーダルデコーダー) |
|---|---|---|---|
| 入力モダリティ | テキストのみ | テキストのみ | テキスト、画像、音声、ビデオ、コード |
| アテンションタイプ | 双方向アテンション | 因果アテンション (MHA) | グループ化クエリ注意 (GQA) |
| 位置エンコーディング | 学習済み / 絶対 | 学习済み / 絶対 | 回転位置埋め込み (RoPE) |
| 活性化関数 | GeLU | GeLU | SwiGLU |
| スケール制約 | 短いコンテキスト | 中程度のコンテキスト | 大規模に拡張されたコンテキスト |
結論
GoogleのGeminiは、トランスフォーマーアーキテクチャの成熟を代表しています。KVキャッシュのボトルネックを解決するためのGQA、モデル容量を最適化するためのSwiGLU、および長いシーケンスの外挿を可能にするためのRoPEを選択することにより、Googleはトランスフォーマーをそもそも成功させた数学的なシンプルさを失うことなく、多様な感覚入力をネイティブに消化できるアーキテクチャを作成しました。