جیمنائی ٹرانسفارمر ماڈل کیسے کام کرتا ہے: GQA، SwiGLU اور نیٹیو ملٹی موڈالٹی
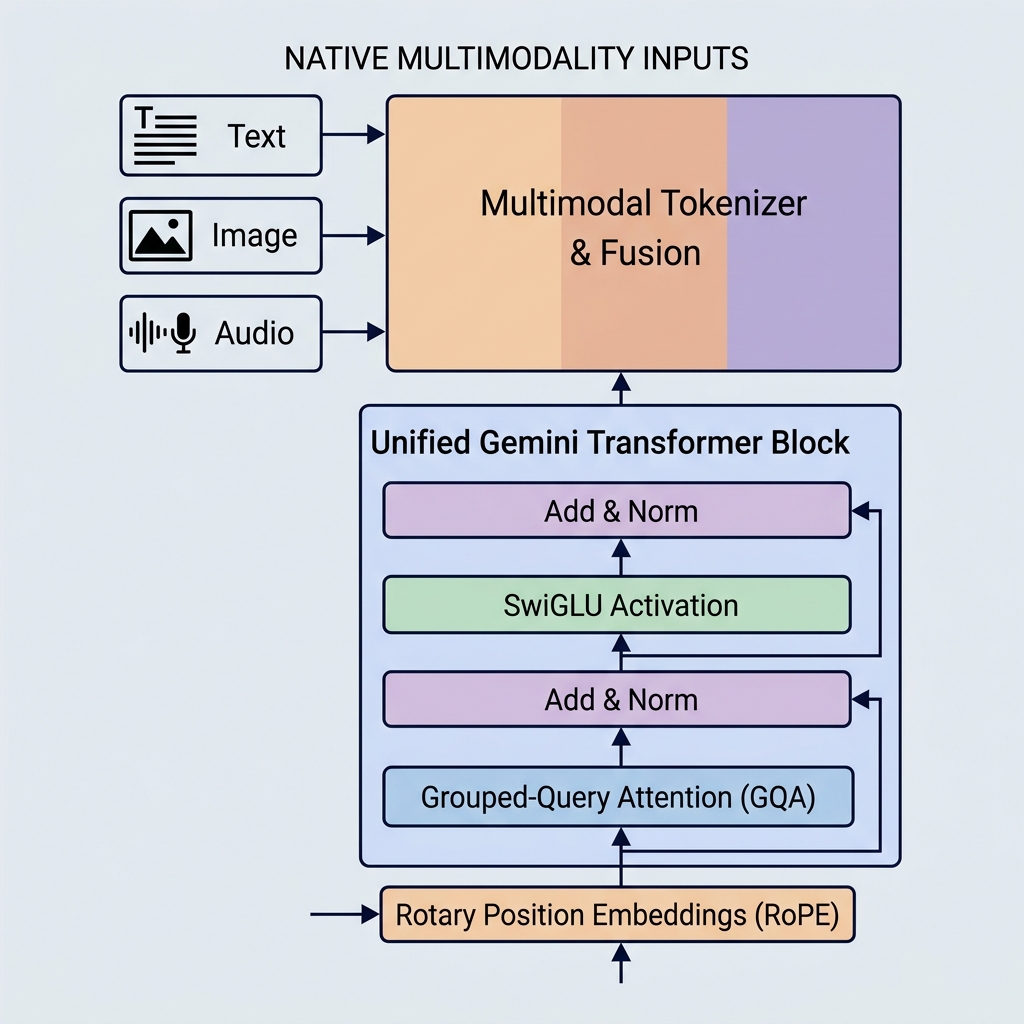
گوگل کے جیمنائی ماڈلز نے نیٹیو ملٹی موڈالٹی، بڑے کانٹیکسٹ ونڈوز، اور اہم فن تعمیراتی اصلاحات متعارف کروا کر اے آئی کی صلاحیتوں میں نئے معیارات قائم کیے ہیں۔ GPT-3 یا BERT جیسے پرانے ماڈلز کے برعکس، جیمنائی کو پہلے دن سے ہی متعدد قسم کے ڈیٹا کو سنبھالنے کے لیے بنایا گیا ہے اور یہ انتہائی موثر توجہ کے میکانزم کا استعمال کرتا ہے۔
اس مضمون میں، ہم جیمنائی ٹرانسفارمر ماڈل کے بنیادی ڈھانچے کے انتخاب کا تجزیہ کریں گے، یہ دیکھیں گے کہ وہ روایتی فن تعمیر کے مقابلے کیسے ہیں، اور PyTorch میں Grouped-Query Attention (GQA) اور SwiGLU Feed-Forward نیٹ ورکس کو نافذ کریں گے۔
1. نیٹیو ملٹی موڈالٹی (متحدہ ایمبیڈنگ اسپیس)
روایتی اے آئی سسٹمز الگ الگ ماڈلز کو ایک ساتھ جوڑ کر ملٹی موڈل سلوک حاصل کرتے ہیں۔ مثال کے طور پر، وہ نقشہ سازی کی تہوں یا اڈاپٹرز کا استعمال کرتے ہوئے پہلے سے تربیت یافتہ ٹیکسٹ ماڈل کے ساتھ امیج انکوڈر (جیسے CLIP) یا آڈیو پروسیسر (جیسے Whisper) جوڑ سکتے ہیں۔
جیمنائی مختلف طریقے سے بنایا گیا ہے۔ یہ نیٹیو ملٹی موڈل (natively multimodal) ہے، جس کا مطلب ہے کہ اسے شروع ہی سے مختلف طریقوں (متن، کوڈ، تصاویر، آڈیو اور ویڈیو) پر بیک وقت تربیت دی گئی ہے۔
- متحدہ ٹوکنائزر: الگ الگ پری پروسیسنگ پائپ لائنوں کے بجائے، مختلف ان پٹس کو ایک مشترکہ، متحدہ لٹنٹ ایمبیڈنگ اسپیس میں ٹوکنز میں تبدیل کیا جاتا ہے۔
- کراس موڈل استدلال: چونکہ نمائندگی کی جگہ مشترک ہے، اس لیے ایک سنگل ڈیکوڈر بلاک بالکل اسی ترتیب میں بصری ٹوکن، آڈیو ٹوکن، اور ٹیکسٹ ٹوکن پر توجہ دے سکتا ہے۔ یہ جیمنائی کو ویڈیو فریموں کی وضاحت کرنے یا آڈیو کو براہ راست متن میں ترجمہ کرنے جیسے پیچیدہ کام انجام دینے کی اجازت دیتا ہے۔
2. Grouped-Query Attention (GQA)
جیسے جیسے کانٹیکسٹ ونڈوز وسیع ہوتی ہیں (لاکھوں ٹوکنز تک)، کی-ویلیو (KV) کیشے کی میموری کا حجم سرونگ میں ایک بڑی رکاوٹ بن جاتا ہے۔
اس کو حل کرنے کے لیے:
- Multi-Head Attention (MHA): ہر Query ہیڈ ($Q$) کا ایک مماثل Key ($K$) اور Value ($V$) ہیڈ ہوتا ہے۔ اگر 32 ہیڈز ہیں تو ہمیں KV ویکٹرز کے 32 سیٹ اسٹور کرنے ہوں گے۔
- Multi-Query Attention (MQA): تمام Query ہیڈز ایک ہی Key اور Value ہیڈ کا اشتراک کرتے ہیں۔ اگرچہ اس سے میموری بچ جاتی ہے، لیکن یہ ماڈل کی صلاحیت اور آؤٹ پٹ کے معیار کو کم کرتا ہے۔
- Grouped-Query Attention (GQA): Query ہیڈز کو گروپ کیا جاتا ہے (مثال کے طور پر، 4 ہیڈز کے 8 گروپس میں)۔ ہر گروپ ایک Key اور Value ہیڈ کا اشتراک کرتا ہے۔
$$\text{Scores} = QK^T \text{ کا حساب Q ہیڈز کو گروپ کرتا ہے تاکہ ایک سنگل KV جوڑے کا اشتراک کیا جا سکے}$$
GQA ایک درمیانی راستے کے طور پر کام کرتا ہے، MHA کے تقریباً تمام معیار کو بحال کرتا ہے جبکہ میموری کی بچت اور رفتار MQA کے قریب فراہم کرتا ہے۔
3. SwiGLU ایکٹیویشن فنکشن
BERT اور پرانے GPT ماڈلز میں استعمال ہونے والے معیاری GeLU ایکٹیویشن کے بجائے، جیمنائی اپنے فیڈ فارورڈ بلاکس میں SwiGLU (Swish-Gated Linear Unit) کا استعمال کرتا ہے۔
ایک گیٹڈ لکیری یونٹ (GLU) ایک نیورل نیٹ ورک کی تہہ ہے جسے دو لکیری تبدیلیوں کے جزو وار مصنوع کے طور پر بیان کیا جاتا ہے، جن میں سے ایک کو سگماڈ ایکٹیویشن کے ذریعے گیٹ کیا جاتا ہے۔ SwiGLU سگماڈ کو Swish (یا SiLU) ایکٹیویشن سے بدل دیتا ہے:
$$\text{SwiGLU}(x) = \text{Swish}_\beta(x W) \otimes (x V)$$
جہاں:
- $W$ اور $V$ لکیری پروجیکشن ویٹ میٹرکس ہیں۔
- $\otimes$ عنصر وار ضرب کی نمائندگی کرتا ہے۔
- $\text{Swish}(x) = x \cdot \sigma(\beta x)$ گیٹنگ میکانزم کے طور پر کام کرتا ہے۔
دکھایا گیا ہے کہ SwiGLU تربیت کے دوران تیزی سے کنورج ہوتا ہے اور معیاری GeLU یا ReLU ایکٹیویشنز کے مقابلے میں ڈاؤن اسٹریم کاموں میں زیادہ درستگی کا باعث بنتا ہے۔
4. Rotary Position Embeddings (RoPE)
اصل ٹرانسفارمرز کے برعکس جنہوں نے ان پٹ ٹوکن ایمبیڈنگز میں مطلق پوزیشنی ایمبیڈنگ ویکٹرز کا اضافہ کیا تھا، جیمنائی ماڈلز Rotary Position Embeddings (RoPE) کا استعمال کرتے ہیں۔
RoPE کمپلیکس اسپیس میں Query ($Q$) اور Key ($K$) ویکٹرز کو گھما کر پوزیشنی معلومات کو انکوڈ کرتا ہے۔ 2D ویکٹر کے لیے، گردش کو اس طرح بیان کیا گیا ہے:
$$R_{\Theta, m}^d x_m = \begin{pmatrix} \cos m\theta & -\sin m\theta \\ \sin m\theta & \cos m\theta \end{pmatrix} \begin{pmatrix} x_{m, 1} \\ x_{m, 2} \end{pmatrix}$$
یہ فارمولیشن اس بات کی ضمانت دیتی ہے کہ پوزیشن $m$ پر کیوری اور پوزیشن $n$ پر کی کے درمیان ڈاٹ پروڈکٹ صرف ان کے رشتہ دار فاصلے $m - n$ پر منحصر ہے:
$$\langle R_{\Theta, m}^d q_m, R_{\Theta, n}^d k_n \rangle = g(q, k, m - n)$$
RoPE ماڈل کو قدرتی طور پر طویل ترتیب کی لمبائی تک پہنچنے کی اجازت دیتا ہے، جو بڑے کانٹیکسٹ ونڈوز کو سنبھالنے کے لیے اہم ہے۔
5. جیمنائی بلاکس کا PyTorch نفاذ
نیچے ایک مکمل PyTorch ماڈیول ہے جو یہ ظاہر کرتا ہے کہ Grouped-Query Attention (GQA) اور ایک SwiGLU Feed-Forward Network کو کیسے نافذ کیا جائے:
import torch
import torch.nn as nn
import torch.nn.functional as F
class SwiGLUFFN(nn.Module):
def __init__(self, d_model, hidden_dim):
super().__init__()
self.w_gate = nn.Linear(d_model, hidden_dim, bias=False)
self.w_val = nn.Linear(d_model, hidden_dim, bias=False)
self.w_down = nn.Linear(hidden_dim, d_model, bias=False)
def forward(self, x):
gate = F.silu(self.w_gate(x))
val = self.w_val(x)
return self.w_down(gate * val)
class GroupedQueryAttention(nn.Module):
def __init__(self, d_model, n_q_heads, n_kv_heads, d_k):
super().__init__()
self.n_q_heads = n_q_heads
self.n_kv_heads = n_kv_heads
self.d_k = d_k
self.group_size = n_q_heads // n_kv_heads
self.q_proj = nn.Linear(d_model, n_q_heads * d_k, bias=False)
self.k_proj = nn.Linear(d_model, n_kv_heads * d_k, bias=False)
self.v_proj = nn.Linear(d_model, n_kv_heads * d_k, bias=False)
self.out_proj = nn.Linear(n_q_heads * d_k, d_model, bias=False)
def forward(self, x):
batch, seq_len, _ = x.shape
q = self.q_proj(x).view(batch, seq_len, self.n_q_heads, self.d_k).transpose(1, 2)
k = self.k_proj(x).view(batch, seq_len, self.n_kv_heads, self.d_k).transpose(1, 2)
v = self.v_proj(x).view(batch, seq_len, self.n_kv_heads, self.d_k).transpose(1, 2)
k = k.repeat_interleave(self.group_size, dim=1)
v = v.repeat_interleave(self.group_size, dim=1)
scores = torch.matmul(q, k.transpose(-2, -1)) / (self.d_k ** 0.5)
mask = torch.triu(torch.ones(seq_len, seq_len, device=x.device), diagonal=1).bool()
scores = scores.masked_fill(mask, float('-inf'))
attn_weights = F.softmax(scores, dim=-1)
context = torch.matmul(attn_weights, v)
context = context.transpose(1, 2).contiguous().view(batch, seq_len, -1)
return self.out_proj(context)
6. فن تعمیر کا موازنہ: BERT بمقابلہ GPT بمقابلہ Gemini
| خصوصیت | BERT (Encoder) | GPT (Decoder) | Gemini (Multimodal Decoder) |
|---|---|---|---|
| ان پٹ موڈالٹیز | صرف متن | صرف متن | متن، تصاویر، آڈیو، ویڈیو، کوڈ |
| توجہ کی قسم | دو طرفہ توجہ | اسبابی توجہ (MHA) | گروپڈ کیوری اٹینشن (GQA) |
| پوزیشنی انکوڈنگ | سیکھی ہوئی / مطلق | سیکھی ہوئی / مطلق | روٹری پوزیشن ایمبیڈنگز (RoPE) |
| ایکٹیویشن | GeLU | GeLU | SwiGLU |
| پیمانے کی حد | مختصر سیاق و سباق | درمیانہ سیاق و سباق | بڑے پیمانے پر توسیعی کانٹیکسٹ ونڈو |
نتیجہ
گوگل کا جیمنائی ٹرانسفارمر فن تعمیر کی پختگی کی نمائندگی کرتا ہے۔ KV کیشے کی رکاوٹ کو دور کرنے کے لیے GQA، ماڈل کی صلاحیت کو بہتر بنانے کے لیے SwiGLU، اور طویل ترتیب کو فعال کرنے کے لیے RoPE کا انتخاب کر کے، گوگل نے ایک ایسا فن تعمیر تیار کیا ہے جو ریاضیاتی سادگی کو کھوئے بغیر متنوع حسی ان پٹس کو نیٹیو طور پر ہضم کر سکتا ہے جس نے ٹرانسفارمر کو شروع میں ہی کامیاب بنایا تھا۔