How Gemini Transformer Model Works: GQA, SwiGLU, and Native Multimodality
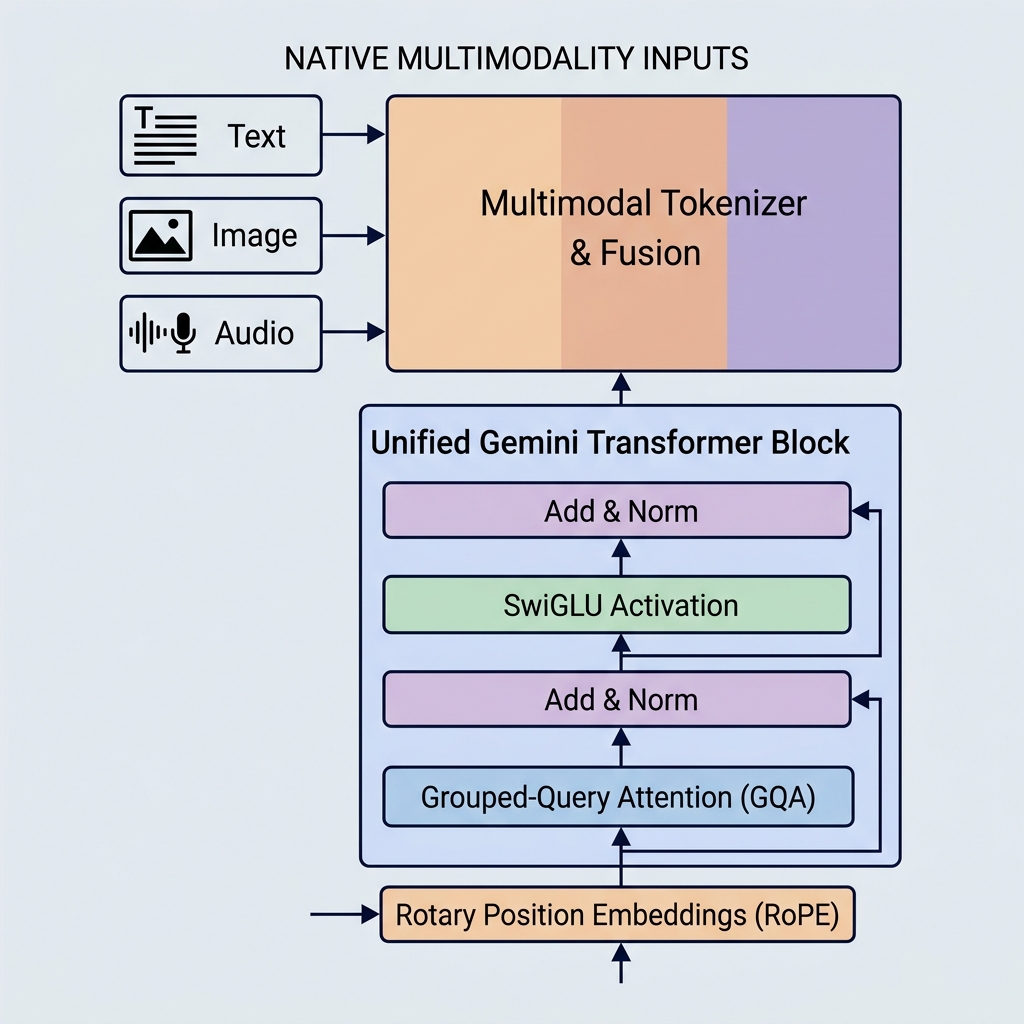
Google’s Gemini models have set new benchmarks in AI capability by introducing native multimodality, massive context windows, and key architectural optimizations. Unlike older models like GPT-3 or BERT, Gemini is built to handle multiple types of data from day one and utilizes highly efficient attention mechanisms.
In this article, we will break down the core architectural choices of the Gemini Transformer model, explore how they compare to traditional architectures, and implement Grouped-Query Attention (GQA) and SwiGLU Feed-Forward Networks in PyTorch.
1. Native Multimodality (Unified Embedding Space)
Traditional AI systems achieve multimodal behavior by stitching separate models together. For example, they might pair an image encoder (like CLIP) or an audio processor (like Whisper) with a pre-trained text model using mapping layers or adapters.
Gemini is built differently. It is natively multimodal, meaning it was trained on different modalities (text, code, images, audio, and video) simultaneously from the ground up.
- Unified Tokenizer: Instead of separate pre-processing pipelines, different inputs are converted into tokens in a shared, unified latent embedding space.
- Cross-Modal Reasoning: Since the representation space is shared, a single decoder block can attend to a visual token, an audio token, and a text token in the exact same sequence. This allows Gemini to perform complex tasks like explaining video frames or translating audio to text directly.
2. Grouped-Query Attention (GQA)
As context windows expand (up to millions of tokens), the memory footprint of the Key-Value (KV) cache becomes a major serving bottleneck.
To solve this:
- Multi-Head Attention (MHA): Every Query head ($Q$) has a matching Key ($K$) and Value ($V$) head. If there are 32 heads, we must store 32 sets of KV vectors.
- Multi-Query Attention (MQA): All Query heads share a single Key and Value head. While this saves memory, it degrades model capacity and output quality.
- Grouped-Query Attention (GQA): Query heads are grouped (e.g., into 8 groups of 4 heads). Each group shares one Key and Value head.
$$\text{Scores} = QK^T \text{ computation in GQA groups Q heads to share a single KV pair}$$
GQA serves as a middle-ground, recovering almost all the quality of MHA while delivering inference speeds and memory savings close to MQA.
3. SwiGLU Activation Function
Instead of the standard GeLU activation used in BERT and older GPT models, Gemini utilizes SwiGLU (Swish-Gated Linear Unit) in its feed-forward blocks.
A gated linear unit (GLU) is a neural network layer defined as the component-wise product of two linear transformations, one of which is gated by a sigmoid activation. SwiGLU replaces the sigmoid with a Swish (or SiLU) activation:
$$\text{SwiGLU}(x) = \text{Swish}_\beta(x W) \otimes (x V)$$
Where:
- $W$ and $V$ are linear projection weight matrices.
- $\otimes$ represents element-wise multiplication.
- $\text{Swish}(x) = x \cdot \sigma(\beta x)$ acts as the gating mechanism.
SwiGLU has been shown to converge faster during training and lead to higher downstream task accuracy compared to standard GeLU or ReLU activations.
4. Rotary Position Embeddings (RoPE)
Unlike original Transformers which added absolute positional embedding vectors to the input token embeddings, Gemini models employ Rotary Position Embeddings (RoPE).
RoPE encodes positional information by rotating the Query ($Q$) and Key ($K$) vectors in the complex space. For a 2D vector, the rotation is defined as:
$$R_{\Theta, m}^d x_m = \begin{pmatrix} \cos m\theta & -\sin m\theta \\ \sin m\theta & \cos m\theta \end{pmatrix} \begin{pmatrix} x_{m, 1} \\ x_{m, 2} \end{pmatrix}$$
This formulation guarantees that the dot product between a query at position $m$ and a key at position $n$ only depends on their relative distance $m - n$:
$$\langle R_{\Theta, m}^d q_m, R_{\Theta, n}^d k_n \rangle = g(q, k, m - n)$$
RoPE allows the model to extrapolate naturally to longer sequence lengths, which is critical for handling massive context windows.
5. PyTorch Implementation of Gemini’s Blocks
Below is a complete PyTorch module demonstrating how to implement Grouped-Query Attention (GQA) and a SwiGLU Feed-Forward Network:
import torch
import torch.nn as nn
import torch.nn.functional as F
class SwiGLUFFN(nn.Module):
def __init__(self, d_model, hidden_dim):
super().__init__()
# Two linear projections for the gate and the value
self.w_gate = nn.Linear(d_model, hidden_dim, bias=False)
self.w_val = nn.Linear(d_model, hidden_dim, bias=False)
self.w_down = nn.Linear(hidden_dim, d_model, bias=False)
def forward(self, x):
# SwiGLU computation: SiLU(x * W_gate) * (x * W_val)
gate = F.silu(self.w_gate(x))
val = self.w_val(x)
return self.w_down(gate * val)
class GroupedQueryAttention(nn.Module):
def __init__(self, d_model, n_q_heads, n_kv_heads, d_k):
super().__init__()
self.n_q_heads = n_q_heads
self.n_kv_heads = n_kv_heads
self.d_k = d_k
self.group_size = n_q_heads // n_kv_heads
self.q_proj = nn.Linear(d_model, n_q_heads * d_k, bias=False)
self.k_proj = nn.Linear(d_model, n_kv_heads * d_k, bias=False)
self.v_proj = nn.Linear(d_model, n_kv_heads * d_k, bias=False)
self.out_proj = nn.Linear(n_q_heads * d_k, d_model, bias=False)
def forward(self, x):
batch, seq_len, _ = x.shape
# 1. Project inputs
q = self.q_proj(x).view(batch, seq_len, self.n_q_heads, self.d_k).transpose(1, 2)
k = self.k_proj(x).view(batch, seq_len, self.n_kv_heads, self.d_k).transpose(1, 2)
v = self.v_proj(x).view(batch, seq_len, self.n_kv_heads, self.d_k).transpose(1, 2)
# 2. Replicate Key and Value heads for GQA grouping
# Repeat KV heads along the head dimension to match Q heads
k = k.repeat_interleave(self.group_size, dim=1)
v = v.repeat_interleave(self.group_size, dim=1)
# 3. Scale dot-product attention
scores = torch.matmul(q, k.transpose(-2, -1)) / (self.d_k ** 0.5)
# Apply causal mask
mask = torch.triu(torch.ones(seq_len, seq_len, device=x.device), diagonal=1).bool()
scores = scores.masked_fill(mask, float('-inf'))
attn_weights = F.softmax(scores, dim=-1)
context = torch.matmul(attn_weights, v)
# Reshape and project out
context = context.transpose(1, 2).contiguous().view(batch, seq_len, -1)
return self.out_proj(context)
# Verify shapes
if __name__ == "__main__":
x = torch.randn(1, 8, 16) # batch=1, seq_len=8, d_model=16
gqa = GroupedQueryAttention(d_model=16, n_q_heads=4, n_kv_heads=2, d_k=4)
ffn = SwiGLUFFN(d_model=16, hidden_dim=32)
attn_out = gqa(x)
ffn_out = ffn(attn_out)
print("Input Shape:", x.shape)
print("Attention Output Shape:", attn_out.shape)
print("FFN Output Shape:", ffn_out.shape)
6. Architectural Comparison: BERT vs. GPT vs. Gemini
| Feature | BERT (Encoder) | GPT (Decoder) | Gemini (Multimodal Decoder) |
|---|---|---|---|
| Input Modalities | Text only | Text only | Text, Images, Audio, Video, Code |
| Attention Type | Bidirectional Attention | Causal Self-Attention (MHA) | Grouped-Query Attention (GQA) |
| Positional Encoding | Learned / Absolute | Learned / Absolute | Rotary Position Embeddings (RoPE) |
| Activation | GeLU | GeLU | SwiGLU |
| Scale Constraint | Short Context | Medium Context | Massively Extended Context |
Conclusion
Google’s Gemini represents the maturation of the Transformer architecture. By selecting GQA to resolve the KV cache bottleneck, SwiGLU to optimize model capacity, and RoPE to enable long-sequence extrapolation, Google created an architecture that can digest diverse sensory inputs natively without losing the mathematical simplicity that made the Transformer successful in the first place.