Comment fonctionne le modèle Transformer Gemini : GQA, SwiGLU et multimodalité native
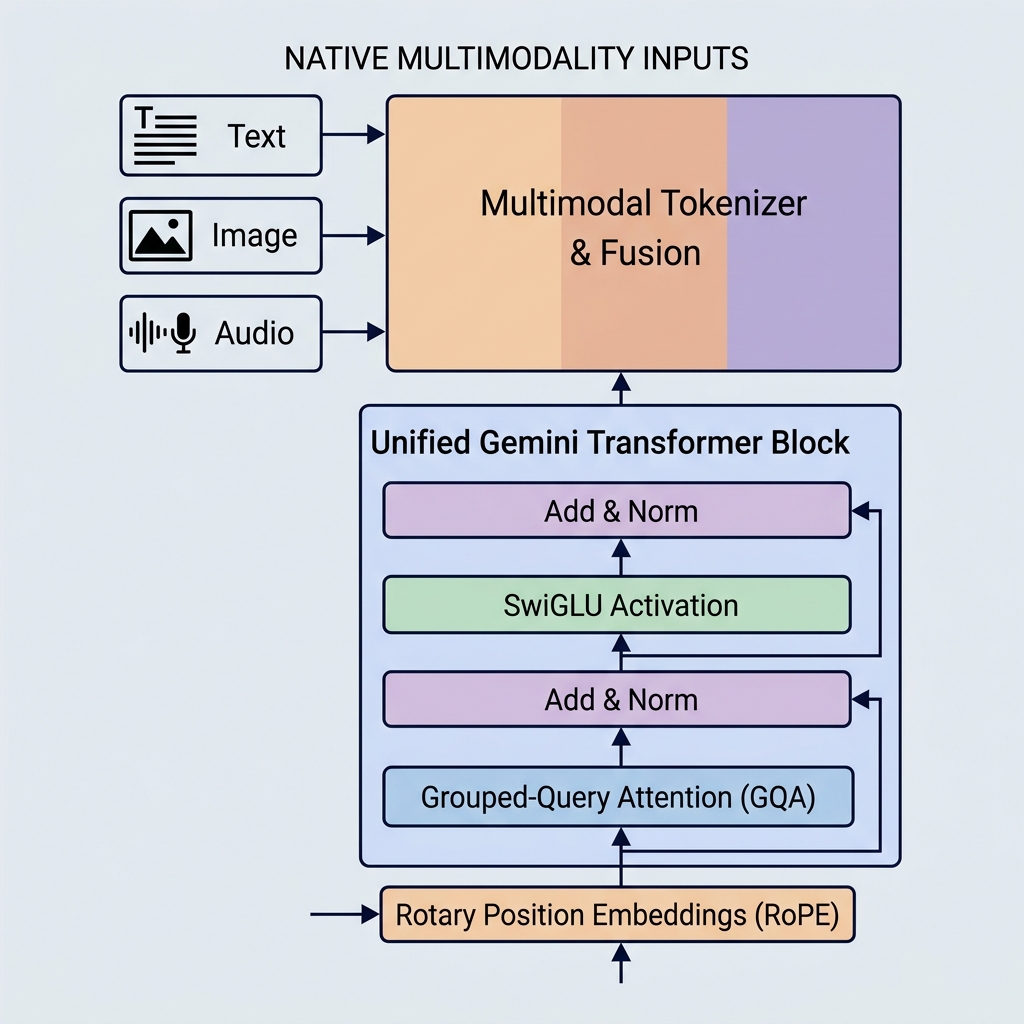
Les modèles Gemini de Google ont défini de nouvelles références en matière d’intelligence artificielle en introduisant une multimodalité native, des fenêtres de contexte massives et des optimisations architecturales clés. Contrairement aux modèles plus anciens comme GPT-3 ou BERT, Gemini est conçu pour gérer plusieurs types de données dès le premier jour et utilise des mécanismes d’attention hautement efficaces.
Dans cet article, nous analyserons les choix architecturaux fondamentaux du modèle Gemini Transformer, explorerons leur comparaison avec les architectures traditionnelles et implémenterons Grouped-Query Attention (GQA) et des réseaux Feed-Forward SwiGLU en PyTorch.
1. Multimodalité native (Espace d’embedding unifié)
Les systèmes d’IA traditionnels obtiennent un comportement multimodal en reliant des modèles distincts. For example, ils peuvent associer un encodeur d’images (comme CLIP) ou un processeur audio (comme Whisper) avec un modèle de texte pré-entraîné à l’aide de couches de mappage ou d’adaptateurs.
Gemini est construit différemment. Il est nativement multimodal, ce qui signifie qu’il a été entraîné sur différentes modalités (texte, code, images, audio et vidéo) simultanément dès le départ.
- Tokenizer unifié : Au lieu de pipelines de prétraitement distincts, les différentes entrées sont converties en tokens dans un espace d’embedding latent partagé et unifié.
- Raisonnement cross-modal : L’espace de représentation étant partagé, un seul bloc décodeur peut traiter un token visuel, un token audio et un token de texte dans la même séquence exacte. Cela permet à Gemini d’exécuter des tâches complexes comme expliquer des images vidéo ou traduire directement de l’audio en texte.
2. Grouped-Query Attention (GQA)
À mesure que les fenêtres de contexte s’élargissent (jusqu’à des millions de tokens), l’empreinte mémoire du cache Key-Value (KV) devient un goulot d’étranglement majeur pour le service.
Pour résoudre cela :
- Multi-Head Attention (MHA) : Chaque tête Query ($Q$) a une tête Key ($K$) et Value ($V$) correspondante. S’il y a 32 têtes, nous devons stocker 32 ensembles de vecteurs KV.
- Multi-Query Attention (MQA) : Toutes les têtes Query partagent une seule tête Key et Value. Bien que cela économise de la mémoire, cela dégrade la capacité du modèle et la qualité de la sortie.
- Grouped-Query Attention (GQA) : Les têtes Query sont regroupées (par exemple, en 8 groupes de 4 têtes). Chaque groupe partage une tête Key et Value.
$$\text{Scores} = QK^T \text{ le calcul dans GQA regroupe les têtes Q pour partager une seule paire KV}$$
La GQA sert de juste milieu, récupérant presque toute la qualité de la MHA tout en offrant des vitesses d’inférence et des économies de mémoire proches de la MQA.
3. Fonction d’activation SwiGLU
Au lieu de l’activation GeLU standard utilisée dans BERT et les anciens modèles GPT, Gemini utilise SwiGLU (Swish-Gated Linear Unit) dans ses blocs feed-forward.
Une unité linéaire contrôlée (GLU) est une couche de réseau neuronal définie comme le produit élément par élément de deux transformations linéaires, dont l’une est contrôlée par une activation sigmoïde. SwiGLU remplace la sigmoïde par une activation Swish (ou SiLU) :
$$\text{SwiGLU}(x) = \text{Swish}_\beta(x W) \otimes (x V)$$
Où :
- $W$ et $V$ sont des matrices de poids de projection linéaire.
- $\otimes$ représente la multiplication élément par élément.
- $\text{Swish}(x) = x \cdot \sigma(\beta x)$ agit comme mécanisme de contrôle.
Il a été démontré que SwiGLU converge plus rapidement pendant l’entraînement et conduit à une plus grande précision sur les tâches en aval par rapport aux activations GeLU ou ReLU standard.
4. Rotary Position Embeddings (RoPE)
Contrairement aux Transformers originaux qui ajoutaient des vecteurs d’embedding positionnel absolu aux embeddings des tokens d’entrée, les modèles Gemini utilisent des Rotary Position Embeddings (RoPE).
RoPE encode les informations positionnelles en faisant tourner les vecteurs Query ($Q$) et Key ($K$) dans l’espace complexe. Pour un vecteur 2D, la rotation est définie comme suit :
$$R_{\Theta, m}^d x_m = \begin{pmatrix} \cos m\theta & -\sin m\theta \\ \sin m\theta & \cos m\theta \end{pmatrix} \begin{pmatrix} x_{m, 1} \\ x_{m, 2} \end{pmatrix}$$
Cette formulation garantit que le produit scalaire entre une requête à la position $m$ et une clé à la position $n$ dépend uniquement de leur distance relative $m - n$ :
$$\langle R_{\Theta, m}^d q_m, R_{\Theta, n}^d k_n \rangle = g(q, k, m - n)$$
RoPE permet au modèle de s’extrapoler naturellement à des longueurs de séquence plus longues, ce qui est essentiel pour gérer des fenêtres de contexte massives.
5. Implémentation PyTorch des blocs de Gemini
Voici un module PyTorch complet montrant comment implémenter Grouped-Query Attention (GQA) et un réseau Feed-Forward SwiGLU :
import torch
import torch.nn as nn
import torch.nn.functional as F
class SwiGLUFFN(nn.Module):
def __init__(self, d_model, hidden_dim):
super().__init__()
self.w_gate = nn.Linear(d_model, hidden_dim, bias=False)
self.w_val = nn.Linear(d_model, hidden_dim, bias=False)
self.w_down = nn.Linear(hidden_dim, d_model, bias=False)
def forward(self, x):
gate = F.silu(self.w_gate(x))
val = self.w_val(x)
return self.w_down(gate * val)
class GroupedQueryAttention(nn.Module):
def __init__(self, d_model, n_q_heads, n_kv_heads, d_k):
super().__init__()
self.n_q_heads = n_q_heads
self.n_kv_heads = n_kv_heads
self.d_k = d_k
self.group_size = n_q_heads // n_kv_heads
self.q_proj = nn.Linear(d_model, n_q_heads * d_k, bias=False)
self.k_proj = nn.Linear(d_model, n_kv_heads * d_k, bias=False)
self.v_proj = nn.Linear(d_model, n_kv_heads * d_k, bias=False)
self.out_proj = nn.Linear(n_q_heads * d_k, d_model, bias=False)
def forward(self, x):
batch, seq_len, _ = x.shape
q = self.q_proj(x).view(batch, seq_len, self.n_q_heads, self.d_k).transpose(1, 2)
k = self.k_proj(x).view(batch, seq_len, self.n_kv_heads, self.d_k).transpose(1, 2)
v = self.v_proj(x).view(batch, seq_len, self.n_kv_heads, self.d_k).transpose(1, 2)
k = k.repeat_interleave(self.group_size, dim=1)
v = v.repeat_interleave(self.group_size, dim=1)
scores = torch.matmul(q, k.transpose(-2, -1)) / (self.d_k ** 0.5)
mask = torch.triu(torch.ones(seq_len, seq_len, device=x.device), diagonal=1).bool()
scores = scores.masked_fill(mask, float('-inf'))
attn_weights = F.softmax(scores, dim=-1)
context = torch.matmul(attn_weights, v)
context = context.transpose(1, 2).contiguous().view(batch, seq_len, -1)
return self.out_proj(context)
6. Comparaison architecturale : BERT vs. GPT vs. Gemini
| Fonctionnalité | BERT (Encodeur) | GPT (Décodeur) | Gemini (Décodeur Multimodal) |
|---|---|---|---|
| Modalités d’entrée | Texte uniquement | Texte uniquement | Texte, images, audio, video, code |
| Type d’attention | Attention bidirectionnelle | Attention causale (MHA) | Grouped-Query Attention (GQA) |
| Codage positionnel | Appris / Absolu | Appris / Absolu | Rotary Position Embeddings (RoPE) |
| Activation | GeLU | GeLU | SwiGLU |
| Contrainte d’échelle | Contexte court | Contexte moyen | Contexte massivement étendu |
Conclusion
Le modèle Gemini de Google représente la maturation de l’architecture Transformer. En choisissant la GQA pour résoudre le goulot d’étranglement du cache KV, SwiGLU pour optimiser la capacité du modèle et RoPE pour permettre l’extrapolation sur de longues séquences, Google a créé une architecture capable de digérer nativement diverses entrées sensorielles sans perdre la simplicité mathématique qui a fait le succès du Transformer en premier lieu.
Explorez plus de perspectives techniques sur le blog de Ghaznix →