Como funciona o modelo Transformer Gemini: GQA, SwiGLU e multimodalidade nativa
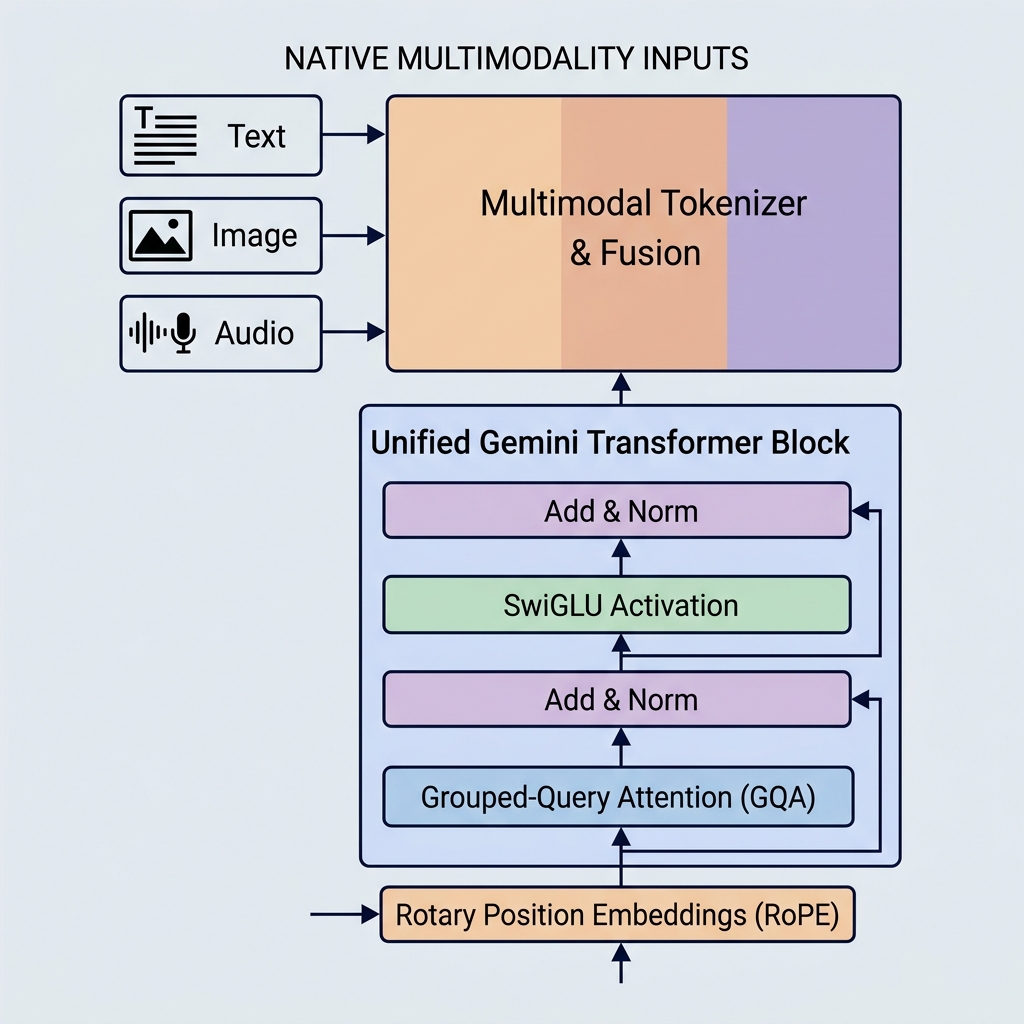
Os modelos Gemini do Google estabeleceram novos padrões de referência na capacidade de IA ao introduzir multimodalidade nativa, janelas de contexto massivas e otimizações arquitetônicas essenciais. Ao contrário de modelos mais antigos como GPT-3 ou BERT, o Gemini é construído para lidar com múltiplos tipos de dados desde o primeiro dia e utiliza mecanismos de atenção altamente eficientes.
Neste artigo, analisaremos as principais escolhas arquitetônicas do modelo Gemini Transformer, exploraremos como elas se comparam às arquiteturas tradicionais e implementaremos Grouped-Query Attention (GQA) e redes Feed-Forward SwiGLU em PyTorch.
1. Multimodalidade nativa (Espaço de embedding unificado)
Os sistemas de IA tradicionais alcançam comportamento multimodal unindo modelos separados. Por exemplo, eles podem emparelhar um codificador de imagem (como CLIP) ou um processador de áudio (como Whisper) com um modelo de texto pré-treinado usando camadas de mapeamento ou adaptadores.
O Gemini é construído de forma diferente. Ele é nativamente multimodal, o que significa que foi treinado em diferentes modalidades (texto, código, imagens, áudio e vídeo) simultaneamente desde o início.
- Tokenizer unificado: Em vez de pipelines de pré-processamento separados, as diferentes entradas são convertidas em tokens em um espaço de embedding latente compartilhado e unificado.
- Raciocínio cross-modal: Como o espaço de representação é compartilhado, um único bloco decodificador pode prestar atenção a um token visual, um token de áudio e um token de texto na mesma sequência exata. Isso permite que o Gemini realize tarefas complexas, como explicar quadros de vídeo ou traduzir áudio em texto diretamente.
2. Grouped-Query Attention (GQA)
À medida que as janelas de contexto se expandem (para até milhões de tokens), a pegada de memória do cache Key-Value (KV) torna-se um grande gargalo de serviço.
Para resolver isso:
- Multi-Head Attention (MHA): Cada cabeça Query ($Q$) tem uma cabeça Key ($K$) e Value ($V$) correspondente. Se houver 32 cabeças, devemos armazenar 32 conjuntos de vetores KV.
- Multi-Query Attention (MQA): Todas as cabeças Query compartilham uma única cabeça Key e Value. Embora isso economize memória, degrada a capacidade do modelo e a qualidade da saída.
- Grouped-Query Attention (GQA): As cabeças Query são agrupadas (por exemplo, em 8 grupos de 4 cabeças). Cada grupo classifica uma cabeça Key e Value.
$$\text{Scores} = QK^T \text{ computação em GQA agrupa cabeças Q para compartilhar um único par KV}$$
A GQA serve como um meio-termo, recuperando quase toda a qualidade da MHA, ao mesmo tempo que oferece velocidades de inferência e economia de memória próximas à MQA.
3. Função de ativação SwiGLU
Em vez da ativação GeLU padrão usada no BERT e em modelos GPT mais antigos, o Gemini utiliza SwiGLU (Swish-Gated Linear Unit) em seus blocos feed-forward.
Uma unidade linear controlada (GLU) é uma camada de rede neural definida como o produto componente a componente de duas transformações lineares, uma das quais é controlada por uma ativação sigmoide. O SwiGLU substitui a sigmoide por uma ativação Swish (ou SiLU):
$$\text{SwiGLU}(x) = \text{Swish}_\beta(x W) \otimes (x V)$$
Onde:
- $W$ e $V$ são matrizes de peso de aplicação linear.
- $\otimes$ representa a multiplicação elemento a elemento.
- $\text{Swish}(x) = x \cdot \sigma(\beta x)$ atua como o mecanismo de controle.
Foi demonstrado que o SwiGLU converge mais rapidamente durante o treinamento e leva a uma maior precisão nas tarefas subsequentes em comparação com as ativações padrão GeLU ou ReLU.
4. Rotary Position Embeddings (RoPE)
Ao contrário dos Transformers originais, que adicionavam vetores de embedding posicional absoluto aos embeddings dos tokens de entrada, os modelos Gemini usam Rotary Position Embeddings (RoPE).
O RoPE codifica informações posicionais rotacionando os vetores Query ($Q$) e Key ($K$) no espaço complexo. Para um vetor 2D, a rotação é definida como:
$$R_{\Theta, m}^d x_m = \begin{pmatrix} \cos m\theta & -\sin m\theta \\ \sin m\theta & \cos m\theta \end{pmatrix} \begin{pmatrix} x_{m, 1} \\ x_{m, 2} \end{pmatrix}$$
Esta formulação garante que o produto escalar entre uma query na posição $m$ e uma key na posição $n$ dependa apenas da sua distância relativa $m - n$:
$$\langle R_{\Theta, m}^d q_m, R_{\Theta, n}^d k_n \rangle = g(q, k, m - n)$$
O RoPE permite que o modelo se extrapole naturalmente para comprimentos de sequência mais longos, o que é fundamental para lidar com janelas de contexto massivas.
5. Implementação em PyTorch dos blocos do Gemini
Abaixo está um módulo PyTorch completo que demonstra como implementar Grouped-Query Attention (GQA) e uma rede Feed-Forward SwiGLU:
import torch
import torch.nn as nn
import torch.nn.functional as F
class SwiGLUFFN(nn.Module):
def __init__(self, d_model, hidden_dim):
super().__init__()
self.w_gate = nn.Linear(d_model, hidden_dim, bias=False)
self.w_val = nn.Linear(d_model, hidden_dim, bias=False)
self.w_down = nn.Linear(hidden_dim, d_model, bias=False)
def forward(self, x):
gate = F.silu(self.w_gate(x))
val = self.w_val(x)
return self.w_down(gate * val)
class GroupedQueryAttention(nn.Module):
def __init__(self, d_model, n_q_heads, n_kv_heads, d_k):
super().__init__()
self.n_q_heads = n_q_heads
self.n_kv_heads = n_kv_heads
self.d_k = d_k
self.group_size = n_q_heads // n_kv_heads
self.q_proj = nn.Linear(d_model, n_q_heads * d_k, bias=False)
self.k_proj = nn.Linear(d_model, n_kv_heads * d_k, bias=False)
self.v_proj = nn.Linear(d_model, n_kv_heads * d_k, bias=False)
self.out_proj = nn.Linear(n_q_heads * d_k, d_model, bias=False)
def forward(self, x):
batch, seq_len, _ = x.shape
q = self.q_proj(x).view(batch, seq_len, self.n_q_heads, self.d_k).transpose(1, 2)
k = self.k_proj(x).view(batch, seq_len, self.n_kv_heads, self.d_k).transpose(1, 2)
v = self.v_proj(x).view(batch, seq_len, self.n_kv_heads, self.d_k).transpose(1, 2)
k = k.repeat_interleave(self.group_size, dim=1)
v = v.repeat_interleave(self.group_size, dim=1)
scores = torch.matmul(q, k.transpose(-2, -1)) / (self.d_k ** 0.5)
mask = torch.triu(torch.ones(seq_len, seq_len, device=x.device), diagonal=1).bool()
scores = scores.masked_fill(mask, float('-inf'))
attn_weights = F.softmax(scores, dim=-1)
context = torch.matmul(attn_weights, v)
context = context.transpose(1, 2).contiguous().view(batch, seq_len, -1)
return self.out_proj(context)
6. Comparação arquitetônica: BERT vs. GPT vs. Gemini
| Recurso | BERT (Encoder) | GPT (Decoder) | Gemini (Decoder Multimodal) |
|---|---|---|---|
| Modalidades de Entrada | Apenas texto | Apenas texto | Texto, imagens, áudio, vídeo, código |
| Tipo de atenção | Atenção bidirecional | Atenção causal (MHA) | Grouped-Query Attention (GQA) |
| Codificação posicional | Aprendida / Absoluta | Aprendida / Absoluta | Rotary Position Embeddings (RoPE) |
| Ativação | GeLU | GeLU | SwiGLU |
| Restrição de escala | Contexto curto | Contexto médio | Contexto massivamente estendido |
Conclusão
O Gemini do Google representa o amadurecimento da arquitetura Transformer. Ao escolher a GQA para resolver o gargalo do cache KV, o SwiGLU para otimizar a capacidade do modelo e o RoPE para permitir a extrapolação de sequências longas, o Google criou uma arquitetura que pode digerir diversas entradas sensoriais nativamente sem perder a simplicidade matemática que tornou o Transformer um sucesso em primeiro lugar.