Gemini Transformer Modeli Nasıl Çalışır: GQA, SwiGLU ve Yerel Multimodalite
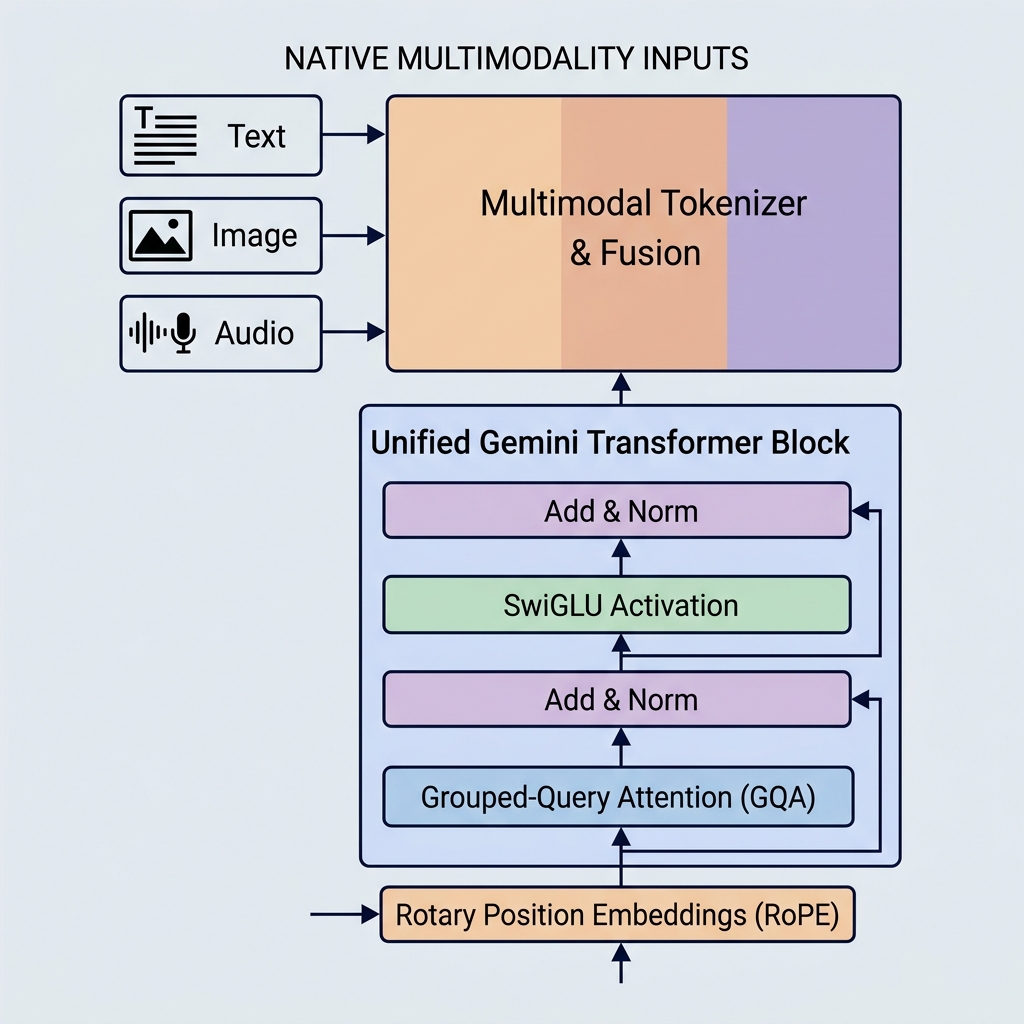
Google’ın Gemini modelleri; yerel multimodaliteyi, devasa bağlam pencerelerini ve temel mimari optimizasyonları sunarak yapay zeka yeteneklerinde yeni standartlar belirledi. GPT-3 veya BERT gibi daha eski modellerin aksine Gemini, ilk günden itibaren birden fazla veri türünü işleyecek şekilde tasarlanmıştır ve son derece verimli dikkat mekanizmaları kullanır.
Bu yazıda, Gemini Transformer modelinin temel mimari seçimlerini ayrıntılarıyla inceleyecek, geleneksel mimarilerle nasıl karşılaştırıldıklarını keşfedecek ve PyTorch’ta Grouped-Query Attention (GQA) ve SwiGLU Feed-Forward ağlarını uygulayacağız.
1. Yerel Multimodalite (Birleşik Gömme Uzayı)
Geleneksel yapay zeka sistemleri, ayrı modelleri birbirine dikerek multimodal davranış elde eder. Örneğin, haritalama katmanları veya adaptörler kullanarak bir görüntü kodlayıcıyı (CLIP gibi) veya bir ses işlemcisini (Whisper gibi) önceden eğitilmiş bir metin modeliyle eşleştirebilirler.
Gemini farklı şekilde inşa edilmiştir. Yerel olarak multimodaldir (natively multimodal), yani başlangıçtan itibaren farklı modaliteler (metin, kod, görüntüler, ses ve video) üzerinde aynı anda eğitilmiştir.
- Birleşik Tokenizer: Ayrı ön işleme hatları yerine, farklı girdiler paylaşılan, birleşik bir gizli gömme uzayındaki tokenlara dönüştürür.
- Modallar Arası Akıl Yürütme: Temsil uzayı paylaşıldığından, tek bir kod çözücü (decoder) bloğu tam olarak aynı dizideki görsel bir tokene, ses tokenine ve metin tokenine dikkat edebilir. Bu durum Gemini’nin video karelerini açıklamak veya sesi doğrudan metne çevirmek gibi karmaşık görevleri gerçekleştirmesini sağlar.
2. Grouped-Query Attention (GQA)
Bağlam pencereleri genişledikçe (milyonlarca tokene kadar), Anahtar-Değer (KV) önbelleğinin bellek ayak izi sunumda önemli bir darboğaz haline gelir.
Bunu çözmek için:
- Multi-Head Attention (MHA): Her Sorgu kafasının (Query head, $Q$) eşleşen bir Anahtar (Key, $K$) ve Değer (Value, $V$) kafası vardır. 32 kafa varsa, 32 set KV vektörü saklamamız gerekir.
- Multi-Query Attention (MQA): Tüm Sorgu kafaları tek bir Anahtar ve Değer kafasını paylaşır. Bu bellek tasarrufu sağlasa da model kapasitesini ve çıktı kalitesini düşürür.
- Grouped-Query Attention (GQA): Sorgu kafaları gruplandırılır (örneğin, 4 kafalı 8 gruba). Her grup tek bir Anahtar ve Değer kafasını paylaşır.
$$\text{Scores} = QK^T \text{ hesaplaması, tek bir KV çiftini paylaşmak için Q kafalarını gruplandırır}$$
GQA bir orta yol görevi görerek MHA’nın neredeyse tüm kalitesini geri kazanırken, MQA’ya yakın çıkarım hızları ve bellek tasarrufu sunar.
3. SwiGLU Aktivasyon Fonksiyonu
BERT ve eski GPT modellerinde kullanılan standart GeLU aktivasyonu yerine Gemini, feed-forward bloklarında SwiGLU (Swish-Gated Linear Unit) kullanır.
Kapılı doğrusal birim (GLU), biri sigmoid aktivasyonu ile kapılanan iki doğrusal dönüşümün bileşen bazında çarpımı olarak tanımlanan bir yapay sinir ağı katmanıdır. SwiGLU, sigmoidi bir Swish (veya SiLU) aktivasyonuyla değiştirir:
$$\text{SwiGLU}(x) = \text{Swish}_\beta(x W) \otimes (x V)$$
Burada:
- $W$ ve $V$ doğrusal projeksiyon ağırlık matrisleridir.
- $\otimes$ eleman bazında çarpmayı temsil eder.
- $\text{Swish}(x) = x \cdot \sigma(\beta x)$ kapılama mekanizması olarak işlev görür.
SwiGLU’nun eğitim sırasında daha hızlı yakınsadığı ve standart GeLU veya ReLU aktivasyonlarına kıyasla sonraki görevlerde daha yüksek doğruluk sağladığı gösterilmiştir.
4. Rotary Position Embeddings (RoPE)
Girdi token gömmelerine mutlak konumsal gömme vektörleri ekleyen orijinal Transformer’ların aksine Gemini modelleri Rotary Position Embeddings (RoPE) kullanır.
RoPE, karmaşık uzaydaki Sorgu ($Q$) ve Anahtar ($K$) vektörlerini döndürerek konumsal bilgileri kodlar. 2D bir vektör için döndürme şu şekilde tanımlanır:
$$R_{\Theta, m}^d x_m = \begin{pmatrix} \cos m\theta & -\sin m\theta \\ \sin m\theta & \cos m\theta \end{pmatrix} \begin{pmatrix} x_{m, 1} \\ x_{m, 2} \end{pmatrix}$$
Bu formül, $m$ konumundaki bir sorgu ile $n$ konumundaki bir anahtar arasındaki nokta çarpımının yalnızca onların göreceli mesafesi olan $m - n$‘ye bağlı olmasını garanti eder:
$$\langle R_{\Theta, m}^d q_m, R_{\Theta, n}^d k_n \rangle = g(q, k, m - n)$$
RoPE, modelin daha uzun dizi uzunluklarına doğal olarak ekstrapolasyon yapmasına olanak tanır ve bu durum devasa bağlam pencerelerini işlemek için kritik öneme sahiptir.
5. Gemini Bloklarının PyTorch Uygulaması
Aşağıda, Grouped-Query Attention (GQA) ve bir SwiGLU Feed-Forward Network‘ün nasıl uygulanacağını gösteren eksiksiz bir PyTorch modülü yer almaktadır:
import torch
import torch.nn as nn
import torch.nn.functional as F
class SwiGLUFFN(nn.Module):
def __init__(self, d_model, hidden_dim):
super().__init__()
self.w_gate = nn.Linear(d_model, hidden_dim, bias=False)
self.w_val = nn.Linear(d_model, hidden_dim, bias=False)
self.w_down = nn.Linear(hidden_dim, d_model, bias=False)
def forward(self, x):
gate = F.silu(self.w_gate(x))
val = self.w_val(x)
return self.w_down(gate * val)
class GroupedQueryAttention(nn.Module):
def __init__(self, d_model, n_q_heads, n_kv_heads, d_k):
super().__init__()
self.n_q_heads = n_q_heads
self.n_kv_heads = n_kv_heads
self.d_k = d_k
self.group_size = n_q_heads // n_kv_heads
self.q_proj = nn.Linear(d_model, n_q_heads * d_k, bias=False)
self.k_proj = nn.Linear(d_model, n_kv_heads * d_k, bias=False)
self.v_proj = nn.Linear(d_model, n_kv_heads * d_k, bias=False)
self.out_proj = nn.Linear(n_q_heads * d_k, d_model, bias=False)
def forward(self, x):
batch, seq_len, _ = x.shape
q = self.q_proj(x).view(batch, seq_len, self.n_q_heads, self.d_k).transpose(1, 2)
k = self.k_proj(x).view(batch, seq_len, self.n_kv_heads, self.d_k).transpose(1, 2)
v = self.v_proj(x).view(batch, seq_len, self.n_kv_heads, self.d_k).transpose(1, 2)
k = k.repeat_interleave(self.group_size, dim=1)
v = v.repeat_interleave(self.group_size, dim=1)
scores = torch.matmul(q, k.transpose(-2, -1)) / (self.d_k ** 0.5)
mask = torch.triu(torch.ones(seq_len, seq_len, device=x.device), diagonal=1).bool()
scores = scores.masked_fill(mask, float('-inf'))
attn_weights = F.softmax(scores, dim=-1)
context = torch.matmul(attn_weights, v)
context = context.transpose(1, 2).contiguous().view(batch, seq_len, -1)
return self.out_proj(context)
6. Mimari Karşılaştırma: BERT vs. GPT vs. Gemini
| Özellik | BERT (Kodlayıcı) | GPT (Kod Çözücü) | Gemini (Çok Modlu Kod Çözücü) |
|---|---|---|---|
| Girdi Modaliteleri | Yalnızca Metin | Yalnızca Metin | Metin, Resimler, Ses, Video, Kod |
| Dikkat Türü | Çift Yönlü Dikkat | Nedensel Dikkat (MHA) | Grouped-Query Attention (GQA) |
| Konumsal Kodlama | Öğrenilmiş / Mutlak | Öğrenilmiş / Mutlak | Döner Konum Gömmeleri (RoPE) |
| Aktivasyon | GeLU | GeLU | SwiGLU |
| Ölçek Kısıtlaması | Kısa Bağlam | Orta Bağlam | Devasa Genişletilmiş Bağlam |
Sonuç
Google’ın Gemini’si, Transformer mimarisinin olgunlaşmasını temsil ediyor. KV önbellek darboğazını gidermek için GQA’yı, model kapasitesini optimize etmek için SwiGLU’yu ve uzun dizi ekstrapolasyonunu sağlamak için RoPE’yi seçerek Google, Transformer’ı ilk etapta başarılı kılan matematiksel sadeliği kaybetmeden çeşitli duyusal girdileri yerel olarak sindirebilen bir mimari yarattı.