مدل ترانسفورمر جمینای چگونه کار میکند: GQA، SwiGLU و چندوجهی بومی
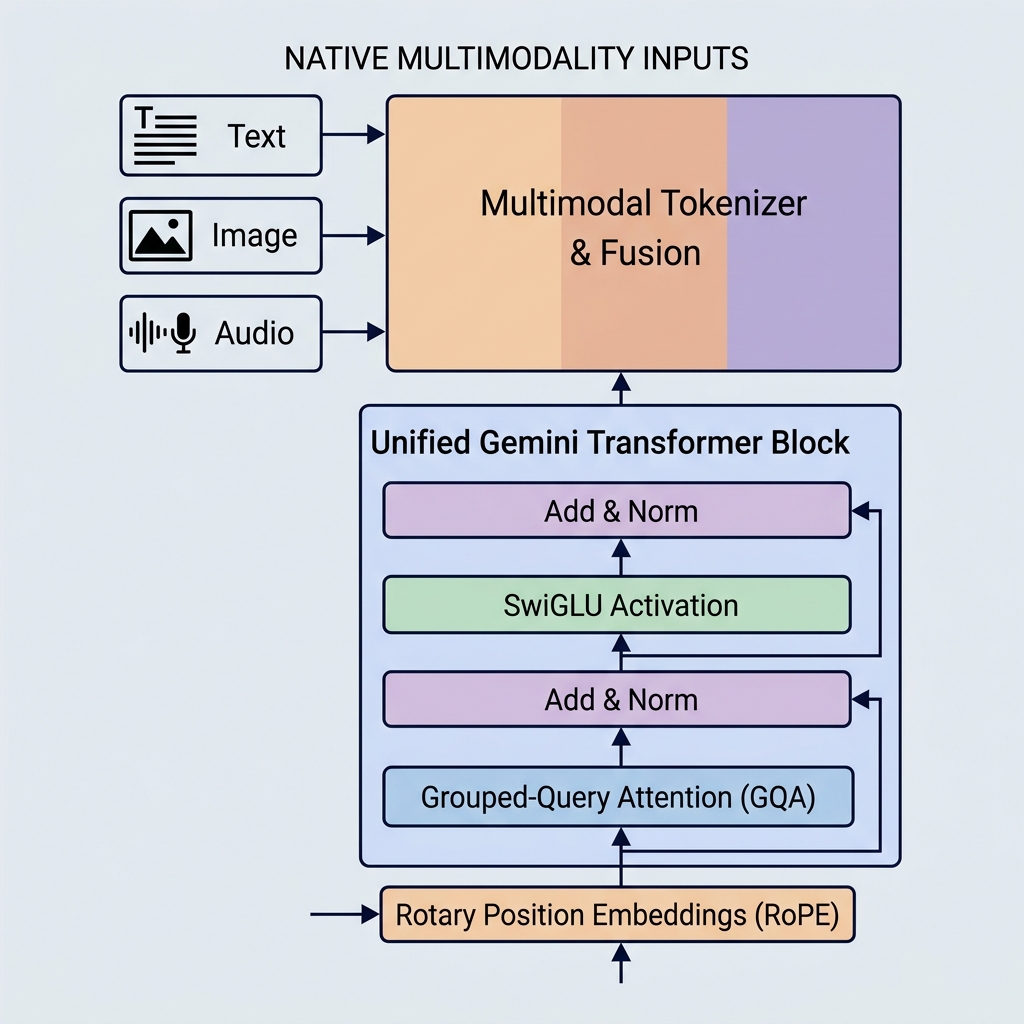
مدلهای جمینای گوگل با معرفی چندوجهی بومی، پنجرههای زمینه عظیم و بهینهسازیهای کلیدی در معماری، معیارهای جدیدی را در تواناییهای هوش مصنوعی ایجاد کردهاند. برخلاف مدلهای قدیمیتر مانند GPT-3 یا BERT، جمینای از همان روز اول برای مدیریت چندین نوع داده ساخته شده است و از مکانیسمهای توجه بسیار کارآمد استفاده میکند.
در این مقاله، ما به انتخابهای اصلی معماری مدل ترانسفورمر جمینای میپردازیم، چگونگی مقایسه آنها با معماریهای سنتی را بررسی میکنیم و مکانیسم Grouped-Query Attention (GQA) و شبکههای Feed-Forward از نوع SwiGLU را در PyTorch پیادهسازی میکنیم.
۱. چندوجهی بومی (فضای تعبیهسازی یکپارچه)
سیستمهای هوش مصنوعی سنتی با اتصال مدلهای مجزا به یکدیگر رفتار چندوجهی پیدا میکنند. به عنوان مثال، آنها ممکن است یک رمزگذار تصویر (مانند CLIP) یا یک پردازشگر صوتی (مانند Whisper) را با یک مدل متنی از پیش آموزش دیده با استفاده از لایههای نقشهبرداری یا آداپتورها جفت کنند.
جمینای متفاوت ساخته شده است. این مدل به طور بومی چندوجهی (natively multimodal) است، به این معنی که از همان ابتدا به طور همزمان بر روی حالتهای مختلف (متن، کد، تصاویر، صدا و ویدئو) آموزش دیده است.
- توکنایزر یکپارچه: به جای خطوط لوله پیشپردازش مجزا، ورودیهای مختلف به توکنهایی در یک فضای تعبیهسازی پنهان مشترک و یکپارچه تبدیل میشوند.
- استدلال بینوجهی: از آنجایی که فضای نمایش مشترک است، یک بلوک دکودر میتواند دقیقاً در همان دنباله به یک توکن بصری، یک توکن صوتی و یک توکن متنی توجه کند. این به جمینای اجازه میدهد تا کارهای پیچیدهای مانند توضیح فریمهای ویدئویی یا ترجمه مستقیم صدا به متن را انجام دهد.
۲. Grouped-Query Attention (GQA)
با گسترش پنجرههای زمینه (تا میلیونها توکن)، حجم حافظه اشغال شده توسط کش Key-Value (KV) به یک گلوگاه اصلی در سرویسدهی تبدیل میشود.
برای حل این مشکل:
- Multi-Head Attention (MHA): هر سر Query ($Q$) دارای یک سر Key ($K$) و Value ($V$) مطابقت دارد. اگر ۳۲ سر وجود داشته باشد، باید ۳۲ مجموعه از بردارهای KV را ذخیره کنیم.
- Multi-Query Attention (MQA): همه سرهای Query یک سر Key و Value مشترک را به اشتراک میگذارند. در حالی که این کار باعث صرفهجویی در حافظه میشود، اما ظرفیت مدل و کیفیت خروجی را کاهش میدهد.
- Grouped-Query Attention (GQA): سرهای Query گروه بندی میشوند (مثلاً به ۸ گروه ۴ سره). هر گروه یک سر Key و Value را به اشتراک میگذارد.
$$\text{Scores} = QK^T \text{ محاسبات در GQA سرهای Q را گروهبندی میکند تا یک جفت KV واحد را به اشتراک بگذارند}$$
GQA به عنوان یک راه میانه عمل میکند، تقریباً تمام کیفیت MHA را بازیابی میکند و در عین حال سرعت استنتاج و صرفهجویی در حافظه نزدیک به MQA را ارائه میدهد.
۳. تابع فعالساز SwiGLU
به جای فعالساز استاندارد GeLU که در BERT و مدلهای قدیمیتر GPT استفاده میشود، جمینای از SwiGLU (Swish-Gated Linear Unit) در بلوکهای Feed-Forward خود استفاده میکند.
یک واحد خطی دروازهدار (GLU) یک لایه شبکه عصبی است که به عنوان حاصلضرب عنصر به عنصر دو تبدیل خطی تعریف میشود که یکی از آنها توسط یک فعالساز سیگموئید دروازهدهی میشود. SwiGLU سیگموئید را با فعالساز Swish (یا SiLU) جایگزین میکند:
$$\text{SwiGLU}(x) = \text{Swish}_\beta(x W) \otimes (x V)$$
جایی که:
- $W$ و $V$ ماتریسهای وزن پروجکشن خطی هستند.
- $\otimes$ نشاندهنده ضرب عنصر به عنصر است.
- $\text{Swish}(x) = x \cdot \sigma(\beta x)$ به عنوان مکانیسم دروازهدهی عمل میکند.
نشان داده شده است که SwiGLU در طول آموزش سریعتر همگرا میشود و در مقایسه با فعالسازهای استاندارد GeLU یا ReLU منجر به دقت بالاتر در کارهای بعدی میشود.
۴. Rotary Position Embeddings (RoPE)
برخلاف ترانسفورمرهای اصلی که بردارهای تعبیهسازی موقعیتی مطلق را به تعبیهسازیهای توکن ورودی اضافه میکردند، مدلهای جمینای از Rotary Position Embeddings (RoPE) استفاده میکنند.
RoPE اطلاعات موقعیتی را با چرخاندن بردارهای Query ($Q$) و Key ($K$) در فضای مختلط رمزگذاری میکند. برای یک بردار ۲ بعدی، چرخش به صورت زیر تعریف میشود:
$$R_{\Theta, m}^d x_m = \begin{pmatrix} \cos m\theta & -\sin m\theta \\ \sin m\theta & \cos m\theta \end{pmatrix} \begin{pmatrix} x_{m, 1} \\ x_{m, 2} \end{pmatrix}$$
این فرمولبندی تضمین میکند که ضرب داخلی بین یک query در موقعیت $m$ و یک key در موقعیت $n$ فقط به فاصله نسبی آنها $m - n$ بستگی دارد:
$$\langle R_{\Theta, m}^d q_m, R_{\Theta, n}^d k_n \rangle = g(q, k, m - n)$$
RoPE به مدل اجازه میدهد تا به طور طبیعی به طولهای دنباله طولانیتر تعمیم یابد، که برای مدیریت پنجرههای زمینه عظیم حیاتی است.
۵. پیادهسازی بلوکهای جمینای در PyTorch
در زیر یک ماژول کامل PyTorch آورده شده است که نحوه پیادهسازی Grouped-Query Attention (GQA) و یک شبکه SwiGLU Feed-Forward را نشان میدهد:
import torch
import torch.nn as nn
import torch.nn.functional as F
class SwiGLUFFN(nn.Module):
def __init__(self, d_model, hidden_dim):
super().__init__()
self.w_gate = nn.Linear(d_model, hidden_dim, bias=False)
self.w_val = nn.Linear(d_model, hidden_dim, bias=False)
self.w_down = nn.Linear(hidden_dim, d_model, bias=False)
def forward(self, x):
gate = F.silu(self.w_gate(x))
val = self.w_val(x)
return self.w_down(gate * val)
class GroupedQueryAttention(nn.Module):
def __init__(self, d_model, n_q_heads, n_kv_heads, d_k):
super().__init__()
self.n_q_heads = n_q_heads
self.n_kv_heads = n_kv_heads
self.d_k = d_k
self.group_size = n_q_heads // n_kv_heads
self.q_proj = nn.Linear(d_model, n_q_heads * d_k, bias=False)
self.k_proj = nn.Linear(d_model, n_kv_heads * d_k, bias=False)
self.v_proj = nn.Linear(d_model, n_kv_heads * d_k, bias=False)
self.out_proj = nn.Linear(n_q_heads * d_k, d_model, bias=False)
def forward(self, x):
batch, seq_len, _ = x.shape
q = self.q_proj(x).view(batch, seq_len, self.n_q_heads, self.d_k).transpose(1, 2)
k = self.k_proj(x).view(batch, seq_len, self.n_kv_heads, self.d_k).transpose(1, 2)
v = self.v_proj(x).view(batch, seq_len, self.n_kv_heads, self.d_k).transpose(1, 2)
k = k.repeat_interleave(self.group_size, dim=1)
v = v.repeat_interleave(self.group_size, dim=1)
scores = torch.matmul(q, k.transpose(-2, -1)) / (self.d_k ** 0.5)
mask = torch.triu(torch.ones(seq_len, seq_len, device=x.device), diagonal=1).bool()
scores = scores.masked_fill(mask, float('-inf'))
attn_weights = F.softmax(scores, dim=-1)
context = torch.matmul(attn_weights, v)
context = context.transpose(1, 2).contiguous().view(batch, seq_len, -1)
return self.out_proj(context)
۶. مقایسه معماری: BERT در مقابل GPT در مقابل Gemini
| ویژگی | BERT (رمزگذار) | GPT (رمزگشا) | Gemini (رمزگشای چندوجهی) |
|---|---|---|---|
| حالتهای ورودی | فقط متن | فقط متن | متن، تصاویر، صدا، ویدئو، کد |
| نوع توجه | توجه دوطرفه | توجه علیتی (MHA) | Grouped-Query Attention (GQA) |
| کدگذاری موقعیتی | آموخته شده / مطلق | آموخته شده / مطلق | Rotary Position Embeddings (RoPE) |
| فعالساز | GeLU | GeLU | SwiGLU |
| محدودیت مقیاس | زمینه کوتاه | زمینه متوسط | زمینه بسیار گسترش یافته |
نتیجهگیری
جمینای گوگل نشاندهنده بلوغ معماری ترانسفورمر است. با انتخاب GQA برای حل گلوگاه کش KV، فعالساز SwiGLU برای بهینهسازی ظرفیت مدل، و RoPE برای فعال کردن درونیابی دنبالههای طولانی، گوگل معماری را ایجاد کرده است که میتواند ورودیهای حسی متنوع را به طور بومی هضم کند، بدون اینکه سادگی ریاضی را که در وهله اول باعث موفقیت ترانسفورمر شده بود، از دست بدهد.