जेमिनी ट्रांसफार्मर मॉडल कैसे काम करता है: GQA, SwiGLU और मूल मल्टीमोडैलिटी
Google के Gemini मॉडल ने मूल मल्टीमोडैलिटी, विशाल संदर्भ विंडो और प्रमुख वास्तुकला अनुकूलन पेश करके एआई क्षमताओं में नए मानक स्थापित किए हैं। GPT-3 या BERT जैसे पुराने मॉडलों के विपरीत, Gemini को पहले दिन से ही कई प्रकार के डेटा को संभालने के लिए बनाया गया है और यह अत्यधिक कुशल अटेंशन मैकेनिज्म का उपयोग करता है।
इस लेख में, हम जेमिनी ट्रांसफार्मर मॉडल के मूल संरचनात्मक विकल्पों का विश्लेषण करेंगे, यह देखेंगे कि वे पारंपरिक संरचनाओं की तुलना में कैसे हैं, और PyTorch में Grouped-Query Attention (GQA) और SwiGLU Feed-Forward नेटवर्क को लागू करेंगे।
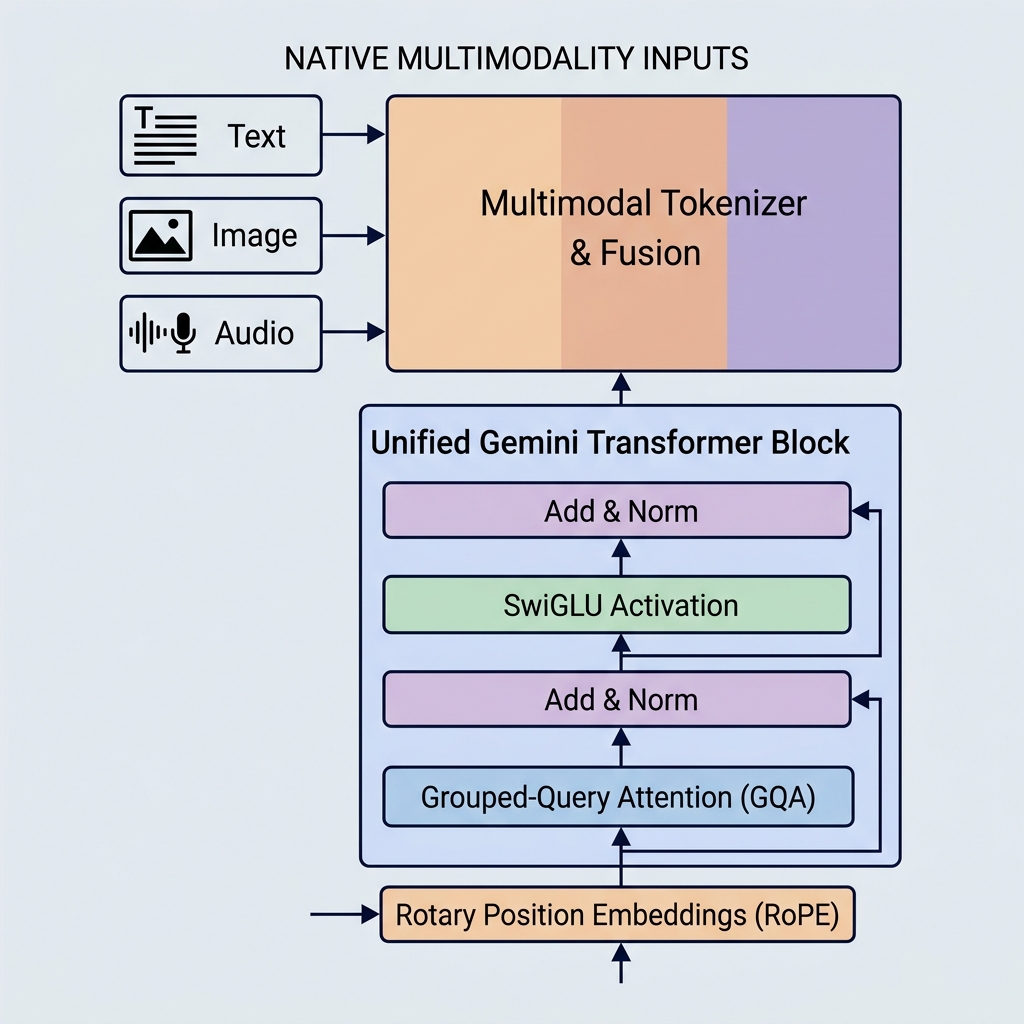
1. मूल मल्टीमोडैलिटी (एकीकृत एम्बेडिंग स्पेस)
पारंपरिक एआई सिस्टम अलग-अलग मॉडलों को एक साथ जोड़कर मल्टीमॉडल व्यवहार प्राप्त करते हैं। उदाहरण के लिए, वे मैपिंग परतों या एडेप्टर का उपयोग करके पूर्व-प्रशिक्षित टेक्स्ट मॉडल के साथ इमेज एनकोडर (जैसे CLIP) या ऑडियो प्रोसेसर (जैसे Whisper) को जोड़ सकते हैं।
Gemini को अलग तरह से बनाया गया है। यह मूल रूप से मल्टीमॉडल (natively multimodal) है, जिसका अर्थ है कि इसे शुरुआत से ही विभिन्न माध्यमों (टेक्स्ट, कोड, इमेज, ऑडियो और वीडियो) पर एक साथ प्रशिक्षित किया गया था।
- एकीकृत टोकनाइज़र: अलग-अलग प्री-प्रोसेसिंग पाइपलाइनों के बजाय, विभिन्न इनपुट्स को एक साझा, एकीकृत अव्यक्त एम्बेडing स्पेस में टोकन में परिवर्तित किया जाता है।
- क्रॉस-मॉडल रीजनिंग: चूंकि प्रतिनिधित्व स्थान साझा किया जाता है, इसलिए एक एकल डिकोडर ब्लॉक बिल्कुल उसी क्रम में एक दृश्य टोकन, एक ऑडियो टोकन और एक टेक्स्ट टोकन पर ध्यान दे सकता है। यह जेमिनी को वीडियो फ्रेम समझाने या ऑडियो को सीधे टेक्स्ट में अनुवाद करने जैसे जटिल कार्य करने की अनुमति देता है।
2. Grouped-Query Attention (GQA)
जैसे-जैसे संदर्भ विंडो का विस्तार होता है (लाखों टोकन तक), की-वैल्यू (KV) कैश का मेमोरी स्पेस मॉडल की सेवा में एक बड़ा गतिरोध बन जाता है।
इसे हल करने के लिए:
- Multi-Head Attention (MHA): प्रत्येक क्वेरी हेड ($Q$) का एक मिलान की ($K$) और वैल्यू ($V$) हेड होता है। यदि 32 हेड हैं, तो हमें KV वैक्टर के 32 सेट स्टोर करने होंगे।
- Multi-Query Attention (MQA): सभी क्वेरी हेड एक ही की और वैल्यू हेड को साझा करते हैं। हालांकि इससे मेमोरी बचती है, लेकिन यह मॉडल की क्षमता और आउटपुट गुणवत्ता को कम करता है।
- Grouped-Query Attention (GQA): क्वेरी हेड्स को समूहीकृत किया जाता है (उदाहरण के लिए, 4 हेड्स के 8 समूहों में)। प्रत्येक समूह एक की और वैल्यू हेड को साझा करता है।
$$\text{Scores} = QK^T \text{ की गणना Q हेड्स को समूहीकृत करती है ताकि एक एकल KV जोड़ी को साझा किया जा सके}$$
GQA एक मध्य मार्ग के रूप में कार्य करता है, MHA की लगभग सभी गुणवत्ता को बहाल करता है जबकि MQA के करीब अनुमान गति और मेमोरी की बचत प्रदान करता है।
3. SwiGLU एक्टिवेशन फ़ंक्शन
BERT और पुराने GPT मॉडलों में उपयोग किए जाने वाले मानक GeLU एक्टिवेशन के बजाय, जेमिनी अपने फीड-फॉरवर्ड ब्लॉकों में SwiGLU (Swish-Gated Linear Unit) का उपयोग करता है।
एक गेटेड रैखिक इकाई (GLU) एक न्यूरल नेटवर्क परत है जिसे दो रैखिक परिवर्तनों के घटक-वार उत्पाद के रूप में परिभाषित किया जाता है, जिनमें से एक को सिग्मॉइड एक्टिवेशन द्वारा गेट किया जाता है। SwiGLU सिग्मॉइड को Swish (या SiLU) एक्टिवेशन से बदल देता है:
$$\text{SwiGLU}(x) = \text{Swish}_\beta(x W) \otimes (x V)$$
जहां:
- $W$ और $V$ रैखिक प्रक्षेपण भार मैट्रिक्स हैं।
- $\otimes$ तत्व-वार गुणन का प्रतिनिधित्व करता है।
- $\text{Swish}(x) = x \cdot \sigma(\beta x)$ गेटिंग तंत्र के रूप में कार्य करता है।
यह दिखाया गया है कि SwiGLU प्रशिक्षण के दौरान तेजी से अभिसरण करता है और मानक GeLU या ReLU एक्टिवेशन की तुलना में डाउनस्ट्रीम कार्यों में उच्च सटीकता की ओर ले जाता।
4. रोटरी पोजीशन एम्बेडिंग (RoPE)
मूल ट्रांसफार्मर के विपरीत, जिसने इनपुट टोकन एम्बेडिंग में पूर्ण स्थिति एम्बेडिंग वैक्टर को जोड़ा था, जेमिनी मॉडल रूटरी पोजीशन एम्बेडिंग (RoPE) का उपयोग करते हैं।
RoPE जटिल स्थान में क्वेरी ($Q$) और की ($K$) वैक्टर को घुमाकर स्थितिजन्य जानकारी को एनकोड करता है। 2D वेक्टर के लिए, रोटेशन को निम्नानुसार परिभाषित किया गया है:
$$R_{\Theta, m}^d x_m = \begin{pmatrix} \cos m\theta & -\sin m\theta \\ \sin m\theta & \cos m\theta \end{pmatrix} \begin{pmatrix} x_{m, 1} \\ x_{m, 2} \end{pmatrix}$$
यह फॉर्मूलेशन गारंटी देता है कि स्थिति $m$ पर एक क्वेरी और स्थिति $n$ पर एक की के बीच डॉट उत्पाद केवल उनकी सापेक्ष दूरी $m - n$ पर निर्भर करता है:
$$\langle R_{\Theta, m}^d q_m, R_{\Theta, n}^d k_n \rangle = g(q, k, m - n)$$
RoPE मॉडल को स्वाभाविक रूप से लंबी अनुक्रम लंबाई तक विस्तारित करने की अनुमति देता है, जो विशाल संदर्भ विंडो को संभालने के लिए महत्वपूर्ण है।
5. जेमिनी ब्लॉक्स का PyTorch कार्यान्वयन
नीचे एक पूर्ण PyTorch मॉड्यूल दिया गया है जो दिखाता है कि Grouped-Query Attention (GQA) और एक SwiGLU Feed-Forward Network को कैसे लागू किया जाए:
import torch
import torch.nn as nn
import torch.nn.functional as F
class SwiGLUFFN(nn.Module):
def __init__(self, d_model, hidden_dim):
super().__init__()
self.w_gate = nn.Linear(d_model, hidden_dim, bias=False)
self.w_val = nn.Linear(d_model, hidden_dim, bias=False)
self.w_down = nn.Linear(hidden_dim, d_model, bias=False)
def forward(self, x):
gate = F.silu(self.w_gate(x))
val = self.w_val(x)
return self.w_down(gate * val)
class GroupedQueryAttention(nn.Module):
def __init__(self, d_model, n_q_heads, n_kv_heads, d_k):
super().__init__()
self.n_q_heads = n_q_heads
self.n_kv_heads = n_kv_heads
self.d_k = d_k
self.group_size = n_q_heads // n_kv_heads
self.q_proj = nn.Linear(d_model, n_q_heads * d_k, bias=False)
self.k_proj = nn.Linear(d_model, n_kv_heads * d_k, bias=False)
self.v_proj = nn.Linear(d_model, n_kv_heads * d_k, bias=False)
self.out_proj = nn.Linear(n_q_heads * d_k, d_model, bias=False)
def forward(self, x):
batch, seq_len, _ = x.shape
q = self.q_proj(x).view(batch, seq_len, self.n_q_heads, self.d_k).transpose(1, 2)
k = self.k_proj(x).view(batch, seq_len, self.n_kv_heads, self.d_k).transpose(1, 2)
v = self.v_proj(x).view(batch, seq_len, self.n_kv_heads, self.d_k).transpose(1, 2)
k = k.repeat_interleave(self.group_size, dim=1)
v = v.repeat_interleave(self.group_size, dim=1)
scores = torch.matmul(q, k.transpose(-2, -1)) / (self.d_k ** 0.5)
mask = torch.triu(torch.ones(seq_len, seq_len, device=x.device), diagonal=1).bool()
scores = scores.masked_fill(mask, float('-inf'))
attn_weights = F.softmax(scores, dim=-1)
context = torch.matmul(attn_weights, v)
context = context.transpose(1, 2).contiguous().view(batch, seq_len, -1)
return self.out_proj(context)
6. संरचनात्मक तुलना: BERT बनाम GPT बनाम Gemini
| विशेषता | BERT (एनकोडर) | GPT (डिकोडर) | Gemini (मल्टीमॉडल डिकोडर) |
|---|---|---|---|
| इनपुट माध्यम | केवल पाठ | केवल पाठ | पाठ, चित्र, ऑडियो, वीडियो, कोड |
| अटेंशन का प्रकार | द्विदिश अटेंशन | कारण अटेंशन (MHA) | Grouped-Query Attention (GQA) |
| पोजीशन एन्कोडिंग | सीखे हुए / पूर्ण | सीखे हुए / पूर्ण | रोटरी पोजीशन एम्बेडिंग (RoPE) |
| सक्रियण | GeLU | GeLU | SwiGLU |
| पैमाने की सीमा | लघु संदर्भ | मध्यम संदर्भ | बड़े पैमाने पर विस्तारित संदर्भ विंडो |
निष्कर्ष
Google का Gemini ट्रांसफार्मर वास्तुकला की परिपक्वता का प्रतिनिधित्व करता है। KV कैश गतिरोध को हल करने के लिए GQA, मॉडल क्षमता को अनुकूलित करने के लिए SwiGLU, और लंबे अनुक्रमों के विस्तार को सक्षम करने के लिए RoPE का चयन करके, Google ने एक ऐसी संरचना बनाई है जो गणितीय सादगी को खोए बिना विविध संवेदी इनपुट को मूल रूप से पचा सकती है जिसने ट्रांसफार्मर को पहली बार में सफल बनाया था।