Cómo funciona el modelo Transformer de Gemini: GQA, SwiGLU y multimodalidad nativa
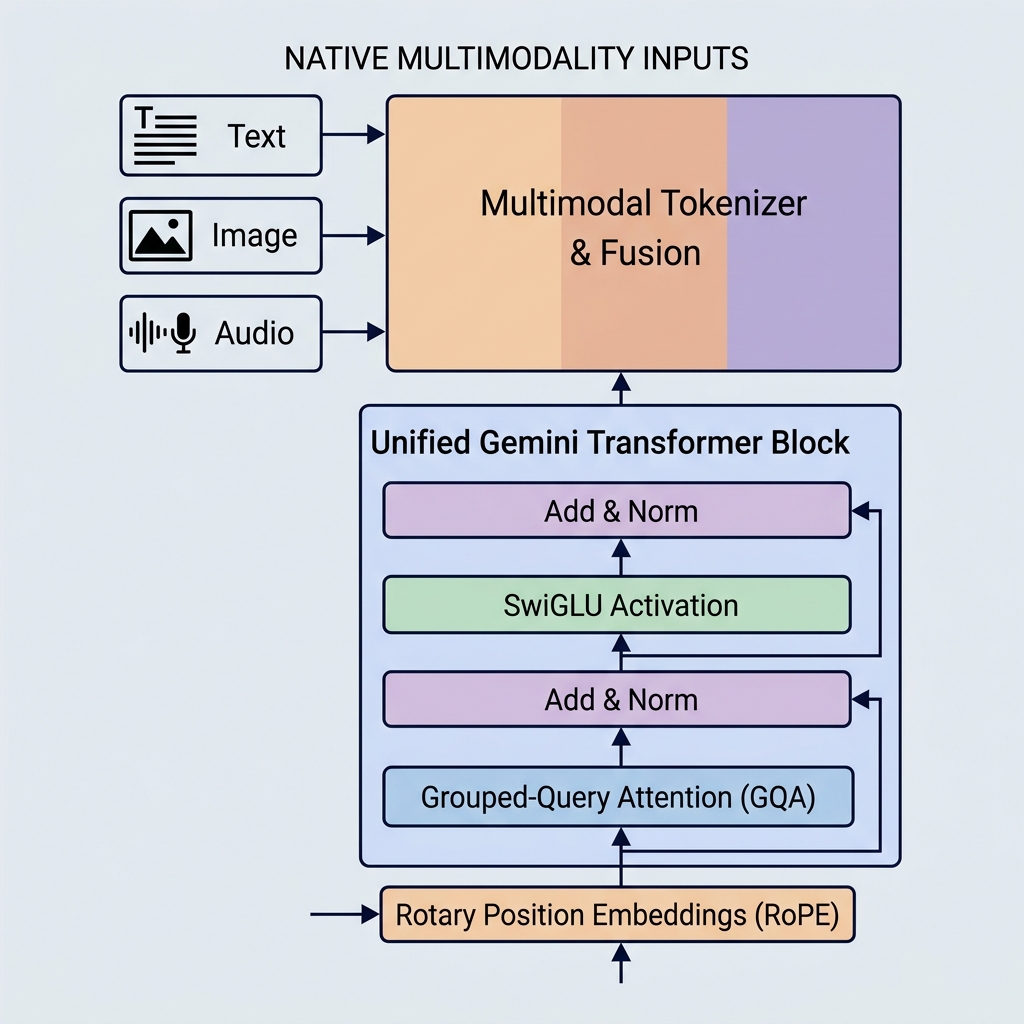
Los modelos Gemini de Google han establecido nuevos estándares en la capacidad de la IA al introducir multimodalidad nativa, ventanas de contexto masivas y optimizaciones arquitectónicas clave. A diferencia de los modelos más antiguos como GPT-3 o BERT, Gemini está diseñado para manejar múltiples tipos de datos desde el primer día y utiliza mecanismos de atención altamente eficientes.
En este artículo, analizaremos las opciones arquitectónicas principales del modelo Transformer de Gemini, exploraremos cómo se comparan con las arquitecturas tradicionales e implementaremos Grouped-Query Attention (GQA) y redes Feed-Forward SwiGLU en PyTorch.
1. Multimodalidad nativa (Espacio de embedding unificado)
Los sistemas de IA tradicionales logran un comportamiento multimodal uniendo modelos separados. Por ejemplo, pueden emparejar un codificador de imágenes (como CLIP) o un procesador de audio (como Whisper) con un modelo de texto preentrenado utilizando capas de mapeo o adaptadores.
Gemini está construido de manera diferente. Es nativamente multimodal, lo que significa que fue entrenado en diferentes modalidades (texto, código, imágenes, audio y video) simultáneamente desde el principio.
- Tokenizer unificado: En lugar de canales de procesamiento previos separados, las diferentes entradas se convierten en tokens en un espacio de embedding latente compartido y unificado.
- Razonamiento multimodal: Dado que el espacio de representación es compartido, un solo bloque decodificador puede atender a un token visual, un token de audio y un token de texto en la misma secuencia exacta. Esto le permite a Gemini realizar tareas complejas como explicar fotogramas de video o traducir audio a texto directamente.
2. Grouped-Query Attention (GQA)
A medida que las ventanas de contexto se expanden (hasta millones de tokens), la huella de memoria del caché Key-Value (KV) se convierte en un cuello de botella importante para el servidor.
Para resolver esto:
- Multi-Head Attention (MHA): Cada cabezal Query ($Q$) tiene un cabezal Key ($K$) y Value ($V$) coincidente. Si hay 32 cabezales, debemos almacenar 32 conjuntos de vectores KV.
- Multi-Query Attention (MQA): Todos los cabezales Query comparten un único cabezal Key y Value. Si bien esto ahorra memoria, degrada la capacidad del modelo y la calidad de la salida.
- Grouped-Query Attention (GQA): Los cabezales Query se agrupan (por ejemplo, en 8 grupos de 4 cabezales). Cada grupo comparte un cabezal Key y Value.
$$\text{Scores} = QK^T \text{ cálculo en GQA agrupa los cabezales Q para compartir un solo par KV}$$
GQA sirve como un punto medio, recuperando casi toda la calidad de MHA al tiempo que ofrece velocidades de inferencia y ahorros de memoria cercanos a MQA.
3. Función de activación SwiGLU
En lugar de la activación GeLU estándar utilizada en BERT y modelos GPT más antiguos, Gemini utiliza SwiGLU (Swish-Gated Linear Unit) en sus bloques feed-forward.
Una unidad lineal controlada (GLU) es una capa de red neuronal definida como el producto elemento a elemento de dos transformaciones lineales, una de las cuales está controlada por una activación sigmoidea. SwiGLU reemplaza el sigmoide con una activación Swish (o SiLU):
$$\text{SwiGLU}(x) = \text{Swish}_\beta(x W) \otimes (x V)$$
Donde:
- $W$ y $V$ son matrices de peso de proyección lineal.
- $\otimes$ representa la multiplicación elemento por elemento.
- $\text{Swish}(x) = x \cdot \sigma(\beta x)$ actúa como el mecanismo de control.
Se ha demostrado que SwiGLU converge más rápido durante el entrenamiento y conduce a una mayor precisión en las tareas posteriores en comparación con las activaciones estándar GeLU o ReLU.
4. Rotary Position Embeddings (RoPE)
A diferencia de los Transformers originales que agregaban vectores de embedding posicional absoluto a los embeddings de los tokens de entrada, los modelos Gemini emplean Rotary Position Embeddings (RoPE).
RoPE codifica la información posicional rotando los vectores Query ($Q$) y Key ($K$) en el espacio complejo. Para un vector 2D, la rotación se define como:
$$R_{\Theta, m}^d x_m = \begin{pmatrix} \cos m\theta & -\sin m\theta \\ \sin m\theta & \cos m\theta \end{pmatrix} \begin{pmatrix} x_{m, 1} \\ x_{m, 2} \end{pmatrix}$$
Esta formulación garantiza que el producto escalar entre una consulta en la posición $m$ y una clave en la posición $n$ solo dependa de su distancia relativa $m - n$:
$$\langle R_{\Theta, m}^d q_m, R_{\Theta, n}^d k_n \rangle = g(q, k, m - n)$$
RoPE permite que el modelo se extrapole naturalmente a secuencias más largas, lo cual es crítico para manejar ventanas de contexto masivas.
5. Implementación en PyTorch de los bloques de Gemini
A continuación se muestra un módulo de PyTorch completo que demuestra cómo implementar Grouped-Query Attention (GQA) y una red Feed-Forward SwiGLU:
import torch
import torch.nn as nn
import torch.nn.functional as F
class SwiGLUFFN(nn.Module):
def __init__(self, d_model, hidden_dim):
super().__init__()
self.w_gate = nn.Linear(d_model, hidden_dim, bias=False)
self.w_val = nn.Linear(d_model, hidden_dim, bias=False)
self.w_down = nn.Linear(hidden_dim, d_model, bias=False)
def forward(self, x):
gate = F.silu(self.w_gate(x))
val = self.w_val(x)
return self.w_down(gate * val)
class GroupedQueryAttention(nn.Module):
def __init__(self, d_model, n_q_heads, n_kv_heads, d_k):
super().__init__()
self.n_q_heads = n_q_heads
self.n_kv_heads = n_kv_heads
self.d_k = d_k
self.group_size = n_q_heads // n_kv_heads
self.q_proj = nn.Linear(d_model, n_q_heads * d_k, bias=False)
self.k_proj = nn.Linear(d_model, n_kv_heads * d_k, bias=False)
self.v_proj = nn.Linear(d_model, n_kv_heads * d_k, bias=False)
self.out_proj = nn.Linear(n_q_heads * d_k, d_model, bias=False)
def forward(self, x):
batch, seq_len, _ = x.shape
q = self.q_proj(x).view(batch, seq_len, self.n_q_heads, self.d_k).transpose(1, 2)
k = self.k_proj(x).view(batch, seq_len, self.n_kv_heads, self.d_k).transpose(1, 2)
v = self.v_proj(x).view(batch, seq_len, self.n_kv_heads, self.d_k).transpose(1, 2)
k = k.repeat_interleave(self.group_size, dim=1)
v = v.repeat_interleave(self.group_size, dim=1)
scores = torch.matmul(q, k.transpose(-2, -1)) / (self.d_k ** 0.5)
mask = torch.triu(torch.ones(seq_len, seq_len, device=x.device), diagonal=1).bool()
scores = scores.masked_fill(mask, float('-inf'))
attn_weights = F.softmax(scores, dim=-1)
context = torch.matmul(attn_weights, v)
context = context.transpose(1, 2).contiguous().view(batch, seq_len, -1)
return self.out_proj(context)
6. Comparación arquitectónica: BERT vs. GPT vs. Gemini
| Característica | BERT (Codificador) | GPT (Decodificador) | Gemini (Decodificador Multimodal) |
|---|---|---|---|
| Modalidades de entrada | Solo texto | Solo texto | Texto, imágenes, audio, video, código |
| Tipo de atención | Atención bidireccional | Atención causal (MHA) | Grouped-Query Attention (GQA) |
| Codificación posicional | Aprendida / Absoluta | Aprendida / Absoluta | Rotary Position Embeddings (RoPE) |
| Activación | GeLU | GeLU | SwiGLU |
| Límite de escala | Contexto corto | Contexto medio | Contexto masivamente extendido |
Conclusión
Gemini de Google representa la maduración de la arquitectura Transformer. Al seleccionar GQA para resolver el cuello de botella de la caché KV, SwiGLU para optimizar la capacidad del modelo y RoPE para permitir la extrapolación de secuencias largas, Google creó una arquitectura que puede procesar diversas entradas sensoriales de forma nativa sin perder la sencillez matemática que hizo que el Transformer fuera un éxito en primer lugar.