Wie das Gemini-Transformer-Modell funktioniert: GQA, SwiGLU und native Multimodalität
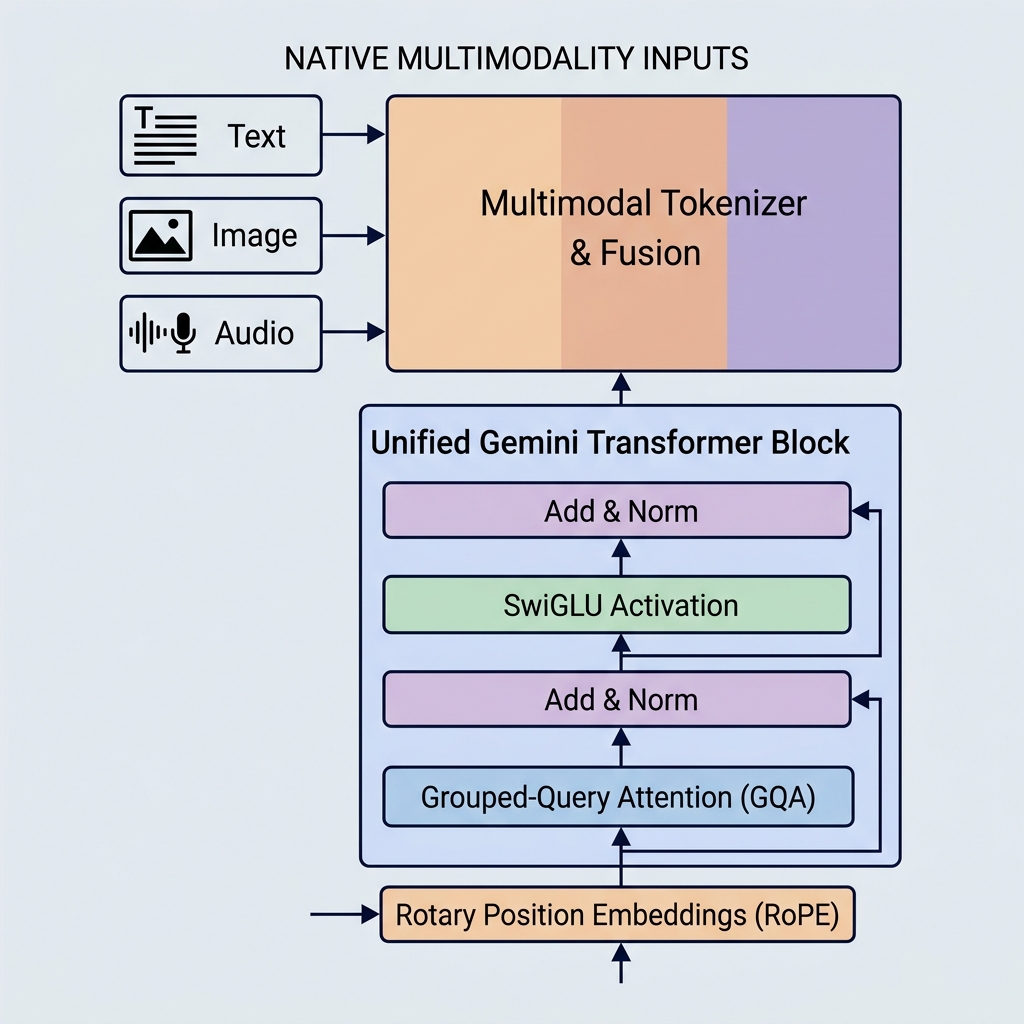
Die Gemini-Modelle von Google haben durch die Einführung nativer Multimodalität, riesiger Kontextfenster und wichtiger architektonischer Optimierungen neue Maßstäbe für KI-Fähigkeiten gesetzt. Im Gegensatz zu älteren Modellen wie GPT-3 oder BERT ist Gemini von Anfang an für die Verarbeitung mehrerer Datentypen ausgelegt und nutzt hocheffiziente Aufmerksamkeitsmechanismen.
In diesem Artikel analysieren wir die wichtigsten architektonischen Entscheidungen des Gemini-Transformer-Modells, untersuchen, wie sie sich von traditionellen Architekturen unterscheiden, und implementieren Grouped-Query Attention (GQA) und SwiGLU Feed-Forward-Netzwerke in PyTorch.
1. Native Multimodalität (Einheitlicher Einbettungsraum)
Traditionelle KI-Systeme erreichen multimodales Verhalten, indem sie separate Modelle zusammensetzen. Beispielsweise koppeln sie einen Bild-Encoder (wie CLIP) oder einen Audio-Prozessor (wie Whisper) mit einem vortrainierten Textmodell unter Verwendung von Adaptern.
Gemini ist anders aufgebaut. Es ist nativ multimodal, was bedeutet, dass es von Grund auf gleichzeitig auf verschiedenen Modalitäten (Text, Code, Bilder, Audio und Video) trainiert wurde.
- Einheitlicher Tokenizer: Anstelle separater Vorverarbeitungspipelines werden unterschiedliche Eingaben in Token in einem gemeinsamen, einheitlichen latenten Einbettungsraum umgewandelt.
- Modalitätsübergreifendes Denken: Da der Repräsentationsraum gemeinsam genutzt wird, kann ein einzelner Decoder-Block in genau derselben Sequenz auf ein visuelles Token, ein Audio-Token und ein Text-Token zugreifen. Dies ermöglicht es Gemini, komplexe Aufgaben wie das Erklären von Videoframes oder das direkte Übersetzen von Audio in Text auszuführen.
2. Grouped-Query Attention (GQA)
Mit der Erweiterung von Kontextfenstern (auf bis zu Millionen von Token) wird der Speicherbedarf des Key-Value (KV)-Caches zu einem großen Engpass bei der Bereitstellung.
Zur Lösung dieses Problems:
- Multi-Head Attention (MHA): Jeder Query-Kopf ($Q$) hat einen passenden Key ($K$)- und Value ($V$)-Kopf. Wenn es 32 Köpfe gibt, müssen wir 32 Sätze von KV-Vektoren speichern.
- Multi-Query Attention (MQA): Alle Query-Köpfe teilen sich einen einzigen Key- und Value-Kopf. Dies spart zwar Speicherplatz, verringert jedoch die Modellkapazität und die Ausgabequalität.
- Grouped-Query Attention (GQA): Query-Köpfe werden gruppiert (z. B. in 8 Gruppen mit jeweils 4 Köpfen). Jede Gruppe teilt sich einen Key- und Value-Kopf.
$$\text{Scores} = QK^T \text{ computation in GQA groups Q heads to share a single KV pair}$$
GQA dient als Mittelweg, der fast die gesamte Qualität von MHA wiederherstellt und gleichzeitig Inferenzgeschwindigkeiten und Speichereinsparungen nahe an MQA liefert.
3. SwiGLU-Aktivierungsfunktion
Anstelle der in BERT und älteren GPT-Modellen verwendeten Standard-GeLU-Aktivierung nutzt Gemini SwiGLU (Swish-Gated Linear Unit) in seinen Feed-Forward-Blöcken.
Eine Gated Linear Unit (GLU) ist eine neuronale Netzwerkschicht, die als komponentenweises Produkt zweier linearer Transformationen definiert ist, von denen eine durch eine Sigmoid-Aktivierung gesteuert wird. SwiGLU ersetzt das Sigmoid durch eine Swish- (oder SiLU)-Aktivierung:
$$\text{SwiGLU}(x) = \text{Swish}_\beta(x W) \otimes (x V)$$
Wobei:
- $W$ und $V$ lineare Projektionsgewichtsmatrizen sind.
- $\otimes$ die elementweise Multiplikation darstellt.
- $\text{Swish}(x) = x \cdot \sigma(\beta x)$ als Gating-Mechanismus fungiert.
Es wurde gezeigt, dass SwiGLU während des Trainings schneller konvergiert und im Vergleich zu Standard-GeLU- oder ReLU-Aktivierungen zu einer höheren Genauigkeit bei nachgelagerten Aufgaben führt.
4. Rotary Position Embeddings (RoPE)
Im Gegensatz zu den ursprünglichen Transformern, die absolute Positionseinbettungsvektoren zu den Eingabe-Token-Einbettungen hinzufügten, verwenden Gemini-Modelle Rotary Position Embeddings (RoPE).
RoPE kodiert Positionsinformationen durch Rotation der Query ($Q$)- und Key ($K$)-Vektoren im komplexen Raum. Für einen 2D-Vektor ist die Rotation definiert als:
$$R_{\Theta, m}^d x_m = \begin{pmatrix} \cos m\theta & -\sin m\theta \\ \sin m\theta & \cos m\theta \end{pmatrix} \begin{pmatrix} x_{m, 1} \\ x_{m, 2} \end{pmatrix}$$
Diese Formulierung garantiert, dass das Skalarprodukt zwischen einer Query an Position $m$ und einem Key an Position $n$ nur von ihrer relativen Distanz $m - n$ abhängt:
$$\langle R_{\Theta, m}^d q_m, R_{\Theta, n}^d k_n \rangle = g(q, k, m - n)$$
RoPE ermöglicht es dem Modell, sich natürlich auf längere Sequenzlängen zu extrapolieren, was für die Handhabung massiver Kontextfenster entscheidend ist.
5. PyTorch-Implementierung von Gemini-Blöcken
Unten finden Sie ein vollständiges PyTorch-Modul, das zeigt, wie Sie Grouped-Query Attention (GQA) und ein SwiGLU Feed-Forward-Netzwerk implementieren:
import torch
import torch.nn as nn
import torch.nn.functional as F
class SwiGLUFFN(nn.Module):
def __init__(self, d_model, hidden_dim):
super().__init__()
self.w_gate = nn.Linear(d_model, hidden_dim, bias=False)
self.w_val = nn.Linear(d_model, hidden_dim, bias=False)
self.w_down = nn.Linear(hidden_dim, d_model, bias=False)
def forward(self, x):
gate = F.silu(self.w_gate(x))
val = self.w_val(x)
return self.w_down(gate * val)
class GroupedQueryAttention(nn.Module):
def __init__(self, d_model, n_q_heads, n_kv_heads, d_k):
super().__init__()
self.n_q_heads = n_q_heads
self.n_kv_heads = n_kv_heads
self.d_k = d_k
self.group_size = n_q_heads // n_kv_heads
self.q_proj = nn.Linear(d_model, n_q_heads * d_k, bias=False)
self.k_proj = nn.Linear(d_model, n_kv_heads * d_k, bias=False)
self.v_proj = nn.Linear(d_model, n_kv_heads * d_k, bias=False)
self.out_proj = nn.Linear(n_q_heads * d_k, d_model, bias=False)
def forward(self, x):
batch, seq_len, _ = x.shape
q = self.q_proj(x).view(batch, seq_len, self.n_q_heads, self.d_k).transpose(1, 2)
k = self.k_proj(x).view(batch, seq_len, self.n_kv_heads, self.d_k).transpose(1, 2)
v = self.v_proj(x).view(batch, seq_len, self.n_kv_heads, self.d_k).transpose(1, 2)
k = k.repeat_interleave(self.group_size, dim=1)
v = v.repeat_interleave(self.group_size, dim=1)
scores = torch.matmul(q, k.transpose(-2, -1)) / (self.d_k ** 0.5)
mask = torch.triu(torch.ones(seq_len, seq_len, device=x.device), diagonal=1).bool()
scores = scores.masked_fill(mask, float('-inf'))
attn_weights = F.softmax(scores, dim=-1)
context = torch.matmul(attn_weights, v)
context = context.transpose(1, 2).contiguous().view(batch, seq_len, -1)
return self.out_proj(context)
6. Architektonischer Vergleich: BERT vs. GPT vs. Gemini
| Feature | BERT (Encoder) | GPT (Decoder) | Gemini (Multimodaler Decoder) |
|---|---|---|---|
| Eingabemodalitäten | Nur Text | Nur Text | Text, Bilder, Audio, Video, Code |
| Aufmerksamkeitstyp | Bidirektional | Kausal (MHA) | Grouped-Query Attention (GQA) |
| Positionskodierung | Gelernt / Absolut | Gelernt / Absolut | Rotary Position Embeddings (RoPE) |
| Aktivierung | GeLU | GeLU | SwiGLU |
| Skalierungsbeschränkung | Kurzer Kontext | Mittlerer Kontext | Extrem erweiterter Kontext |
Fazit
Googles Gemini repräsentiert die Weiterentwicklung der Transformer-Architektur. Durch die Wahl von GQA zur Behebung des KV-Cache-Engpasses, SwiGLU zur Optimierung der Modellkapazität und RoPE zur Ermöglichung der Extrapolation langer Sequenzen hat Google eine Architektur geschaffen, die verschiedene sensorische Eingaben nativ verarbeiten kann, ohne die mathematische Einfachheit zu verlieren, die den Transformer überhaupt erst so erfolgreich gemacht hat.
Entdecken Sie weitere technische Einblicke im Ghaznix-Blog →