Как работает модель трансформера Gemini: GQA, SwiGLU и нативная мультимодальность
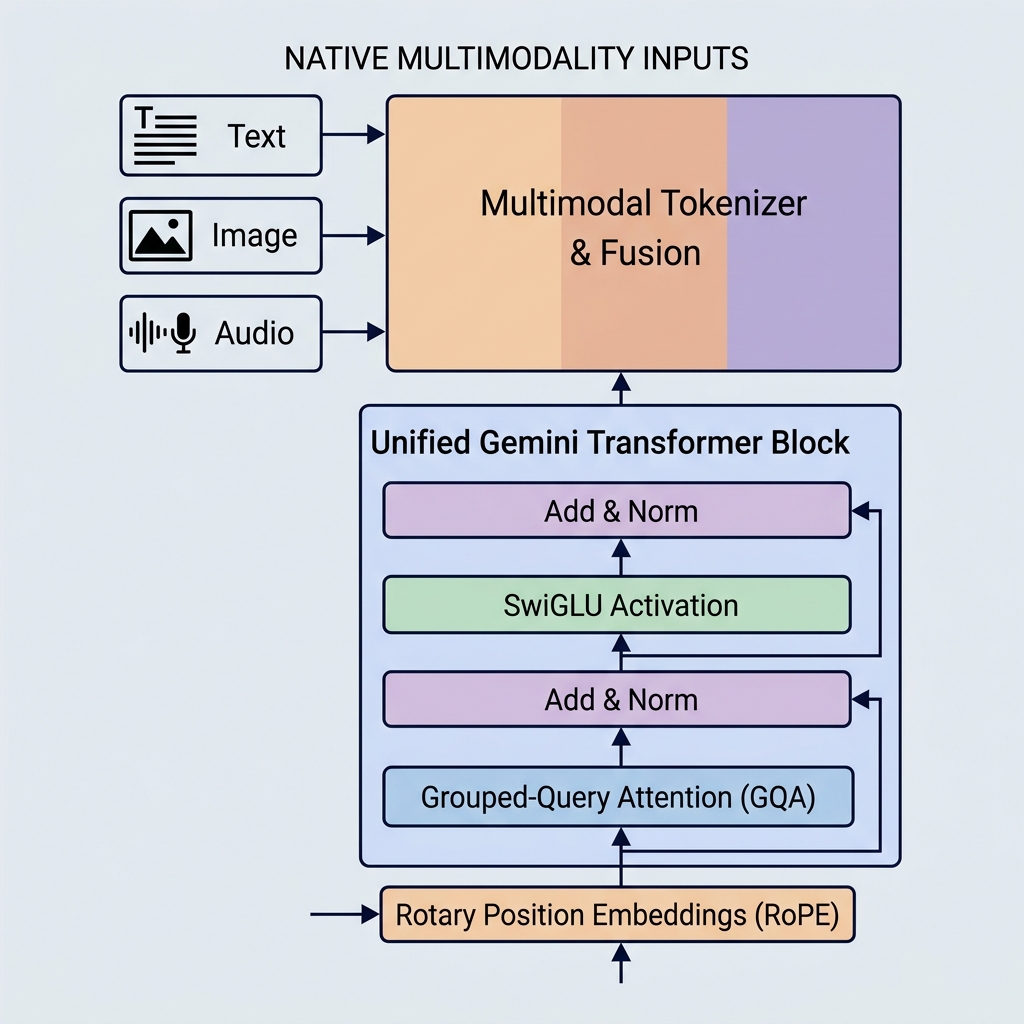
Модели Gemini от Google установили новые стандарты возможностей искусственного интеллекта, представив нативную мультимодальность, гигантские контекстные окна и ключевые архитектурные оптимизации. В отличие от более старых моделей, таких как GPT-3 или BERT, Gemini с самого первого дня разрабатывалась для работы с различными типами данных и использует высокоэффективные механизмы внимания.
В этой статье мы подробно разберем основные архитектурные решения модели трансформера Gemini, сравним их с традиционными архитектурами и реализуем Grouped-Query Attention (GQA) и сети прямого распространения SwiGLU на PyTorch.
1. Нативная мультимодальность (Единое пространство эмбеддингов)
Традиционные системы ИИ достигают мультимодального поведения путем объединения отдельных моделей. Например, они могут связать кодировщик изображений (такой как CLIP) или звуковой процессор (такой как Whisper) с предварительно обученной текстовой моделью, используя переходные слои или адаптеры.
Gemini построена иначе. Она является нативно мультимодальной, что означает, что она с самого начала одновременно обучалась на данных различных модальностей (текст, код, изображения, аудио и видео).
- Единый токенизатор: Вместо отдельных конвейеров предварительной обработки различные входные данные преобразуются в токены в общем едином латентном пространстве эмбеддингов.
- Кросс-модальные рассуждения: Поскольку пространство представлений является общим, один блок декодера может обрабатывать визуальный токен, аудиотокен и текстовый токен в одной и той же последовательности. Это позволяет Gemini выполнять сложные задачи, такие как объяснение видеокадров или перевод аудио напрямую в текст.
2. Grouped-Query Attention (GQA)
По мере расширения контекстных окон (до миллионов токенов) объем памяти, занимаемый кэшем Key-Value (KV), становится главным узким местом при развертывании.
Для решения этой проблемы:
- Multi-Head Attention (MHA): Каждая головка запросов ($Q$) имеет соответствующую головку ключей ($K$) и значений ($V$). Если головок 32, мы должны хранить 32 набора векторов KV.
- Multi-Query Attention (MQA): Все головки запросов совместно используют одну головку ключей и значений. Хотя это экономит память, это снижает пропускную способность модели и качество вывода.
- Grouped-Query Attention (GQA): Головки запросов группируются (например, в 8 групп по 4 головки). Каждая группа использует одну общую головку ключей и значений.
$$\text{Scores} = QK^T \text{ вычисление в GQA группирует головки Q для совместного использования одной пары KV}$$
GQA служит золотой серединой, восстанавливая почти все качество MHA и обеспечивая скорость вывода и экономию памяти, близкие к MQA.
3. Функция активации SwiGLU
Вместо стандартной активации GeLU, используемой в BERT и старых моделях GPT, Gemini использует SwiGLU (Swish-Gated Linear Unit) в своих блоках прямого распространения.
Gated Linear Unit (GLU) — это слой нейронной сети, определяемый как покомпонентное произведение двух линейных преобразований, одно из которых фильтруется активацией сигмоиды. SwiGLU заменяет сигмоиду активацией Swish (или SiLU):
$$\text{SwiGLU}(x) = \text{Swish}_\beta(x W) \otimes (x V)$$
Где:
- $W$ и $V$ — матрицы весов линейной проекции.
- $\otimes$ обозначает поэлементное умножение.
- $\text{Swish}(x) = x \cdot \sigma(\beta x)$ действует как механизм фильтрации.
Было показано, что SwiGLU сходится быстрее во время обучения и обеспечивает более высокую точность на последующих задачах по сравнению со стандартными активациями GeLU или ReLU.
4. Rotary Position Embeddings (RoPE)
В отличие от оригинальных трансформеров, которые добавляли абсолютные векторы позиционных эмбеддингов к эмбеддингам входных токенов, модели Gemini используют Rotary Position Embeddings (RoPE).
RoPE кодирует позиционную информацию путем вращения векторов Query ($Q$) и Key ($K$) в комплексном пространстве. Для 2D-вектора вращение определяется как:
$$R_{\Theta, m}^d x_m = \begin{pmatrix} \cos m\theta & -\sin m\theta \\ \sin m\theta & \cos m\theta \end{pmatrix} \begin{pmatrix} x_{m, 1} \\ x_{m, 2} \end{pmatrix}$$
Такая формулировка гарантирует, что скалярное произведение между запросом в позиции $m$ и ключом в позиции $n$ зависит только от их относительного расстояния $m - n$:
$$\langle R_{\Theta, m}^d q_m, R_{\Theta, n}^d k_n \rangle = g(q, k, m - n)$$
RoPE позволяет модели естественно экстраполироваться на большую длину последовательности, что критически важно для работы с гигантскими контекстными окнами.
5. Реализация блоков Gemini на PyTorch
Ниже представлен готовый модуль PyTorch, демонстрирующий реализацию Grouped-Query Attention (GQA) и сети прямого распространения SwiGLU:
import torch
import torch.nn as nn
import torch.nn.functional as F
class SwiGLUFFN(nn.Module):
def __init__(self, d_model, hidden_dim):
super().__init__()
self.w_gate = nn.Linear(d_model, hidden_dim, bias=False)
self.w_val = nn.Linear(d_model, hidden_dim, bias=False)
self.w_down = nn.Linear(hidden_dim, d_model, bias=False)
def forward(self, x):
gate = F.silu(self.w_gate(x))
val = self.w_val(x)
return self.w_down(gate * val)
class GroupedQueryAttention(nn.Module):
def __init__(self, d_model, n_q_heads, n_kv_heads, d_k):
super().__init__()
self.n_q_heads = n_q_heads
self.n_kv_heads = n_kv_heads
self.d_k = d_k
self.group_size = n_q_heads // n_kv_heads
self.q_proj = nn.Linear(d_model, n_q_heads * d_k, bias=False)
self.k_proj = nn.Linear(d_model, n_kv_heads * d_k, bias=False)
self.v_proj = nn.Linear(d_model, n_kv_heads * d_k, bias=False)
self.out_proj = nn.Linear(n_q_heads * d_k, d_model, bias=False)
def forward(self, x):
batch, seq_len, _ = x.shape
q = self.q_proj(x).view(batch, seq_len, self.n_q_heads, self.d_k).transpose(1, 2)
k = self.k_proj(x).view(batch, seq_len, self.n_kv_heads, self.d_k).transpose(1, 2)
v = self.v_proj(x).view(batch, seq_len, self.n_kv_heads, self.d_k).transpose(1, 2)
k = k.repeat_interleave(self.group_size, dim=1)
v = v.repeat_interleave(self.group_size, dim=1)
scores = torch.matmul(q, k.transpose(-2, -1)) / (self.d_k ** 0.5)
mask = torch.triu(torch.ones(seq_len, seq_len, device=x.device), diagonal=1).bool()
scores = scores.masked_fill(mask, float('-inf'))
attn_weights = F.softmax(scores, dim=-1)
context = torch.matmul(attn_weights, v)
context = context.transpose(1, 2).contiguous().view(batch, seq_len, -1)
return self.out_proj(context)
6. Сравнение архитектур: BERT vs. GPT vs. Gemini
| Параметр | BERT (Encoder) | GPT (Decoder) | Gemini (Multimodal Decoder) |
|---|---|---|---|
| Входные модальности | Только текст | Только текст | Текст, изображения, аудио, видео, код |
| Тип внимания | Двунаправленное | Последовательное (MHA) | Grouped-Query Attention (GQA) |
| Кодирование позиций | Обучаемое / Абсолютное | Обучаемое / Абсолютное | Rotary Position Embeddings (RoPE) |
| Активация | GeLU | GeLU | SwiGLU |
| Ограничение масштаба | Короткий контекст | Средний контекст | Максимально увеличенный контекст |
Заключение
Google Gemini представляет собой вершину эволюции архитектуры трансформера. Выбрав GQA для устранения узкого места кэша KV, SwiGLU для оптимизации емкости модели и RoPE для экстраполяции на длинные последовательности, Google создала архитектуру, способную нативно воспринимать различные сенсорные входы без потери математической простоты, которая изначально сделала трансформер успешным.