כיצד עובד מודל הטרנספורמר Gemini: GQA, SwiGLU ומולטי-מודליות נייטיב
מודלי ה-Gemini של גוגل הציבו מדדי ביצועים חדשים ביכולות בינה מלאכותית על ידי הצגת מולטי-מודליות נייטיב, חלונות הקשר עצומים ואופטימיזציות ארכיטקטוניות מרכזיות. בניגוד למודלים ישנים יותר כמו GPT-3 ou BERT, Gemini נבנה לטיפול בסוגי נתונים מרובים מהיום הראשון ומשתמש במנגנוני קשב (attention) יעילים במיוחד.
במאמר זה, נפרק את בחירות הארכיטקטורה המרכזיות של מודל הטרנספורמר Gemini, נבחן כיצד הן משתוות לארכיטקטורות מסורתיות, ונממש מנגנון Grouped-Query Attention (GQA) ורשתות Feed-Forward מסוג SwiGLU ב-PyTorch.
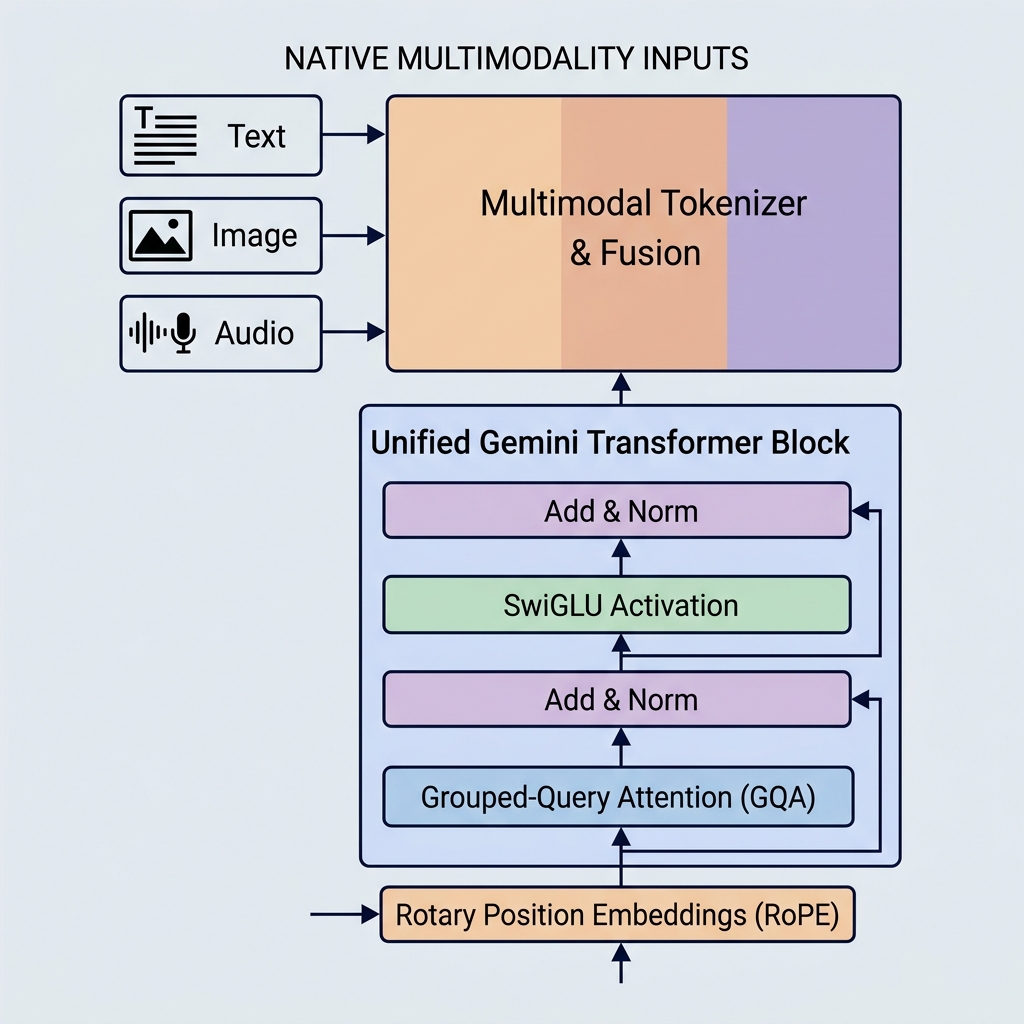
1. מולטי-מודליות נייטיב (מרחב ייצוג מאוחד)
מערכות בינה מלאכותית מסורתיות משיגות התנהגות מולטי-מודלית על ידי חיבור מודלים נפרדים יחד. לדוגמה, הן עשויות לשלב אנקודר תמונות (כמו CLIP) או מעבד שמע (כמו Whisper) עם מודל טקסט מאומן מראש באמצעות שכבות מיפוי או מתאמים.
Gemini בנוי אחרת. הוא מולטי-מודלי נייטיב (natively multimodal), כלומר הוא אומן על מודליות שונות (טקסט, קוד, תמונות, שמע ווידאו) בו-זמנית מהיסוד.
- טוקנייזר מאוחד: במקום תהליכי עיבוד מקדימים נפרדים, קלטים שונים מומרים לטוקנים במרחב ייצוג לטנטי משותף ומאוחד.
- חשיבה בין-מודלית: מכיוون שמרחב הייצוג משותף, בלוק דקודר בודד יכול להתייחס לטוקן חזותי, לטוקן שמע ולטוקן טקסט בדיוק באותו רצף. הדבר מאפשר ל-Gemini לבצע משימות מורכבות כמו הסבר על פריים של וידאו או תרגום שמע לטקست באופן ישיר.
2. Grouped-Query Attention (GQA)
ככל שחלונות ההקשר מתרחבים (עד למיליוני טוקנים), נפח הזיכרון של מטמון ה-Key-Value (KV) הופך לצוואר בקבוק מרכזי בשירות.
כדי לפתור זאת:
- Multi-Head Attention (MHA): לכל ראש Query ($Q$) יש ראש Key ($K$) וראש Value ($V$) תואמים. אם יש 32 ראשים, עלינו לאחסן 32 קבוצות של וקטורי KV.
- Multi-Query Attention (MQA): כל ראשי ה-Query משתפים ראש Key וראש Value יחיד. בעוד שזה חוסך בזיכרון, זה פוגע ביכולת המודל ובאיכות הפלט.
- Grouped-Query Attention (GQA): ראשי ה-Query מוגדרים בקבוצות (למשל, 8 קבוצות של 4 ראשים). כל קבוצה משתפת ראש Key וראש Value יחיד.
$$\text{Scores} = QK^T \text{ computation in GQA groups Q heads to share a single KV pair}$$
GQA משמש כדרך ביניים, המשיב כמעט את כל האיכות של MHA בעודו מספק מהירויות הסקה וחיסכון בזיכרון הקרובים ל-MQA.
3. פונקציית האקטיבציה SwiGLU
במקום אקטיבציית ה-GeLU הסטندרטית המשמשת ב-BERT ובמודלי GPT ישנים יותר, Gemini משתמש ב-SwiGLU (Swish-Gated Linear Unit) בבלוקי ה-feed-forward שלו.
Gated Linear Unit (GLU) היא שכבת רשת עצבית המוגדרת כמכפלה איבר-איבר של שתי טרנספורמציות ליניאריות, שאחת מהن נשלטת על ידי אקטיבציית סיגמואיד. SwiGLU מחליף את הסיגמואיד באקטיבציית Swish (או SiLU):
$$\text{SwiGLU}(x) = \text{Swish}_\beta(x W) \otimes (x V)$$
כאשר:
- $W$ ו-$V$ הן מטריצות משקל של היטל ליניארי.
- $\otimes$ מייצג כפל איבר-איבר.
- $\text{Swish}(x) = x \cdot \sigma(\beta x)$ פועל כמנגנון השער (gating).
הוכח כי SwiGLU מתכנס מהר יותר במהלך האימון ומוביל לדיוק גבוה יותר במשימות המשך בהשוואה לאקטיבציות סטנדרטיות של GeLU או ReLU.
4. Rotary Position Embeddings (RoPE)
בניגוד לטרנספורמרים המקוריים שהוסיפו וקטורי מיקום מוחלטים ל-embeddings של טוקני הקלט, מודלי Gemini משתמשים ב-Rotary Position Embeddings (RoPE).
RoPE מקודד מידע מיקומי על ידי סיבוב וקטורי ה-Query ($Q$) וה-Key ($K$) במרחב המרוכב. עבור וקטור דו-ממדי, הסיבוב מוגדר כ:
$$R_{\Theta, m}^d x_m = \begin{pmatrix} \cos m\theta & -\sin m\theta \\ \sin m\theta & \cos m\theta \end{pmatrix} \begin{pmatrix} x_{m, 1} \\ x_{m, 2} \end{pmatrix}$$
ניסוח זה מבטיח כי המכפלה הסקלרית בין query במיקום $m$ לבין key במיקום $n$ תלויה רק במרחק היחסי ביניהם $m - n$:
$$\langle R_{\Theta, m}^d q_m, R_{\Theta, n}^d k_n \rangle = g(q, k, m - n)$$
RoPE מאפשר למודל לבצע אקסטרפולציה טבעית לאורכי רצף ארוכים יותר, דבר קריטי לטיפול בחלונות הקשר עצומים.
5. מימוש ב-PyTorch של בלוקי Gemini
להלن מודול PyTorch מלא המדגים כיצד לממש Grouped-Query Attention (GQA) ורשת SwiGLU Feed-Forward:
import torch
import torch.nn as nn
import torch.nn.functional as F
class SwiGLUFFN(nn.Module):
def __init__(self, d_model, hidden_dim):
super().__init__()
self.w_gate = nn.Linear(d_model, hidden_dim, bias=False)
self.w_val = nn.Linear(d_model, hidden_dim, bias=False)
self.w_down = nn.Linear(hidden_dim, d_model, bias=False)
def forward(self, x):
gate = F.silu(self.w_gate(x))
val = self.w_val(x)
return self.w_down(gate * val)
class GroupedQueryAttention(nn.Module):
def __init__(self, d_model, n_q_heads, n_kv_heads, d_k):
super().__init__()
self.n_q_heads = n_q_heads
self.n_kv_heads = n_kv_heads
self.d_k = d_k
self.group_size = n_q_heads // n_kv_heads
self.q_proj = nn.Linear(d_model, n_q_heads * d_k, bias=False)
self.k_proj = nn.Linear(d_model, n_kv_heads * d_k, bias=False)
self.v_proj = nn.Linear(d_model, n_kv_heads * d_k, bias=False)
self.out_proj = nn.Linear(n_q_heads * d_k, d_model, bias=False)
def forward(self, x):
batch, seq_len, _ = x.shape
q = self.q_proj(x).view(batch, seq_len, self.n_q_heads, self.d_k).transpose(1, 2)
k = self.k_proj(x).view(batch, seq_len, self.n_kv_heads, self.d_k).transpose(1, 2)
v = self.v_proj(x).view(batch, seq_len, self.n_kv_heads, self.d_k).transpose(1, 2)
k = k.repeat_interleave(self.group_size, dim=1)
v = v.repeat_interleave(self.group_size, dim=1)
scores = torch.matmul(q, k.transpose(-2, -1)) / (self.d_k ** 0.5)
mask = torch.triu(torch.ones(seq_len, seq_len, device=x.device), diagonal=1).bool()
scores = scores.masked_fill(mask, float('-inf'))
attn_weights = F.softmax(scores, dim=-1)
context = torch.matmul(attn_weights, v)
context = context.transpose(1, 2).contiguous().view(batch, seq_len, -1)
return self.out_proj(context)
6. השוואה ארכיטקטונית: BERT מול GPT מול Gemini
| תכונה | BERT (אנקודר) | GPT (דקودר) | Gemini (דקودר מולטי-מודלי) |
|---|---|---|---|
| מולטי-מודליות קלט | טקست בלבד | טקסט בלבד | טקסט, תמונות, שמע, וידאו, קוד |
| סוג הקשב | קשב דו-כיווני | קשב סיבתי (MHA) | Grouped-Query Attention (GQA) |
| קידוד מיקומי | נלמד / מוחלט | נלמד / מוחלט | Rotary Position Embeddings (RoPE) |
| אקטיבציה | GeLU | GeLU | SwiGLU |
| מגבלת קנה מידה | הקשר קצר | הקשר בינוני | הקשר מורחב במיוחד |
סיכום
ה-Gemini של גוגل מייצג את הבגרות של ארכיטקטורת הטרנספורמר. על ידי בחירה ב-GQA לפתרון צוואר הבקבוק של מטמון ה-KV, ב-SwiGLU לאופטימיזציה של קיבולת המודל, וב-RoPE לאפשור אקסטרפולציה של רצפים ארוכים, גוגل יצרה ארכיטקטורה שיכולה לעבד קלטים חושיים מגוונים באופן טבעי מבلى לאבד את הפשטות המתמטית שהפכה את הטרנספורمر להצלחה מלכתחילה.