كيف يعمل نموذج ترانسفورمر Gemini: GQA وSwiGLU والوسائط المتعددة الأصلية
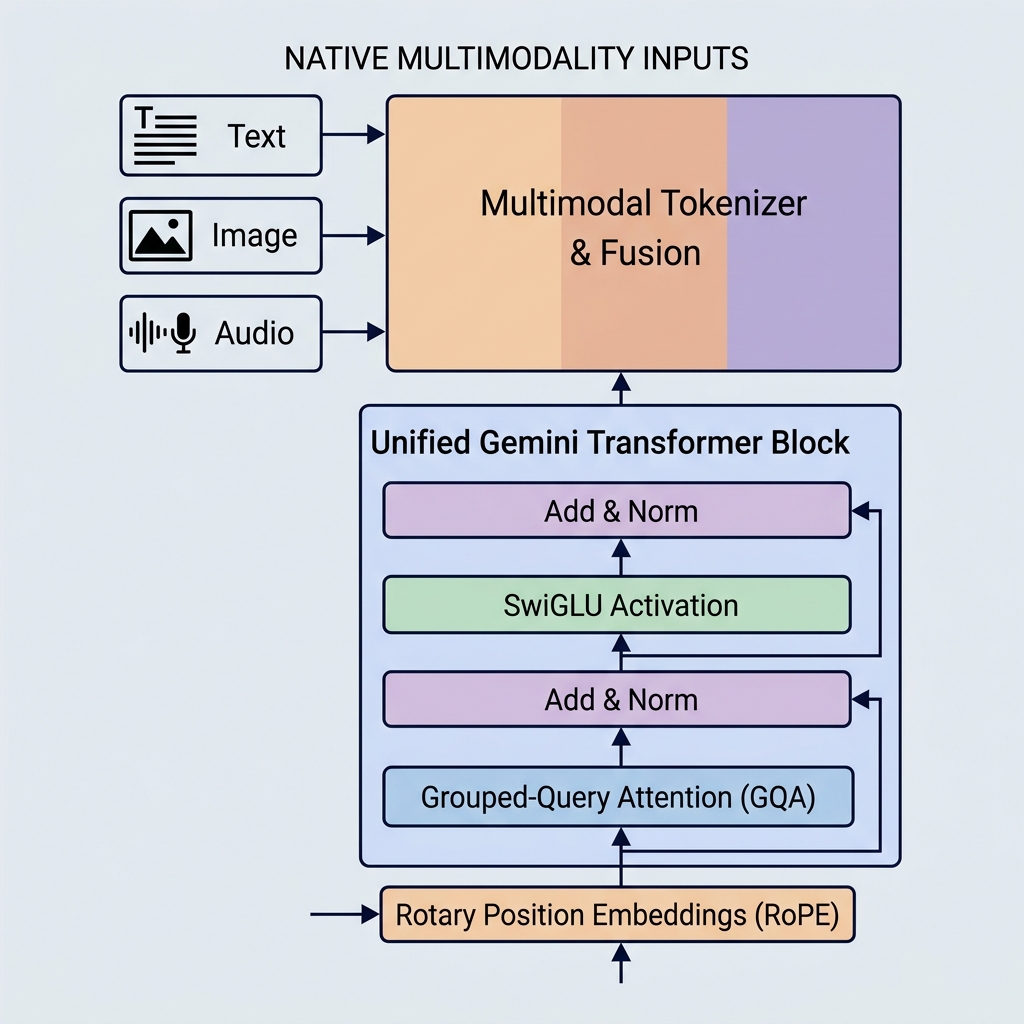
وضعت نماذج Gemini من Google معايير جديدة لقدرات الذكاء الاصطناعي من خلال تقديم الوسائط المتعددة الأصلية، ونوافذ السياق الضخمة، والتحسينات الهيكلية الرئيسية. وخلافاً للنماذج القديمة مثل GPT-3 أو BERT، فقد تم تصميم Gemini للتعامل مع أنواع متعددة من البيانات منذ اليوم الأول، ويستخدم آليات انتباه عالية الكفاءة.
في هذه المقالة، سنقوم بتفصيل الاختيارات الهيكلية الأساسية لنموذج ترانسفورمر Gemini، ونستكشف كيف تقارن بالهياكل التقليدية، ونقوم ببرمجة آلية Grouped-Query Attention (GQA) وشبكات Feed-Forward من نوع SwiGLU بلغة PyTorch.
1. الوسائط المتعددة الأصلية (مساحة التضمين الموحدة)
تحقق أنظمة الذكاء الاصطناعي التقليدية سلوكاً متعدد الوسائط عن طريق ربط نماذج منفصلة معاً. على سبيل المثال، قد يقومون بدمج ترميز الصور (مثل CLIP) أو معالج الصوت (مثل Whisper) مع نموذج نصي مدرب مسبقاً باستخدام طبقات ربط أو محولات.
تم بناء Gemini بشكل مختلف. فهو متعدد الوسائط بشكل أصلي (natively multimodal)، مما يعني أنه تم تدريبه على وسائط مختلفة (النصوص، الأكواد، الصور، الصوت، والفيديو) بشكل متزامن منذ البداية.
- مجزئ رموز موحد (Unified Tokenizer): بدلاً من خطوط معالجة مسبقة منفصلة، يتم تحويل المدخلات المختلفة إلى رموز في مساحة تضمين كامنة مشتركة وموحدة.
- التفكير عابر الوسائط: نظراً لأن مساحة التمثيل مشتركة، يمكن لكتلة مفكك ترميز واحدة أن تنتبه إلى رمز مرئي ورمز صوتي ورمز نصي في نفس التسلسل تماماً. يتيح ذلك لـ Gemini أداء مهام معقدة مثل شرح إطارات الفيديو أو ترجمة الصوت إلى نص مباشرة.
2. Grouped-Query Attention (GQA)
مع توسع نوافذ السياق (لتصل إلى ملايين الرموز)، تصبح مساحة الذاكرة التي تستهلكها ذاكرة التخزين المؤقت Key-Value (KV) عقبة رئيسية في الخدمة.
ولحل هذا:
- Multi-Head Attention (MHA): لكل رأس Query ($Q$) رأس Key ($K$) ورأس Value ($V$) مطابِق. إذا كان هناك 32 رأساً، فيجب علينا تخزين 32 مجموعة من متجهات KV.
- Multi-Query Attention (MQA): تشترك جميع رؤوس Query في رأس Key ورأس Value واحد. بينما يوفر هذا الذاكرة، فإنه يقلل من قدرة النموذج وجودة المخرجات.
- Grouped-Query Attention (GQA): يتم تجميع رؤوس Query (على سبيل المثال، إلى 8 مجموعات من 4 رؤوس). تشترك كل مجموعة في رأس Key ورأس Value واحد.
$$\text{Scores} = QK^T \text{ تقوم الحسابات في GQA بتجميع رؤوس Q لمشاركة زوج KV واحد}$$
يعمل GQA كحل وسط، حيث يستعيد جودة MHA بالكامل تقريباً مع توفير سرعات استدلال وتوفير في الذاكرة يقترب من MQA.
3. دالة التنشيط SwiGLU
بدلاً من تنشيط GeLU القياسي المستخدم في BERT ونماذج GPT الأقدم، يستخدم Gemini دالة SwiGLU (Swish-Gated Linear Unit) في كتل التغذية الأمامية.
الوحدة الخطية ذات البوابة (GLU) هي طبقة شبكة عصبية يتم تعريفها على أنها حاصل ضرب عنصر بعنصر لتحويلين خطيين، يتم التحكم في أحدهما بواسطة تنشيط سيجمويد. يستبدل SwiGLU السيجمويد بتنشيط Swish (أو SiLU):
$$\text{SwiGLU}(x) = \text{Swish}_\beta(x W) \otimes (x V)$$
حيث:
- $W$ و $V$ هما مصفوفتان لأوزان الإسقاط الخطي.
- $\otimes$ يمثل الضرب عنصر بعنصر.
- $\text{Swish}(x) = x \cdot \sigma(\beta x)$ يعمل كآلية البوابة.
وقد ثبت أن SwiGLU يتقارب بشكل أسرع أثناء التدريب ويؤدي إلى دقة أعلى في المهام اللاحقة مقارنة بتنشيطات GeLU أو ReLU القياسية.
4. Rotary Position Embeddings (RoPE)
على عكس الترانسفورمر الأصلي الذي أضاف متجهات التضمين الموضعي المطلقة إلى تضمينات الرموز المدخلة، تستخدم نماذج Gemini تقنية Rotary Position Embeddings (RoPE).
يقوم RoPE بترميز المعلومات الموضعية عن طريق تدوير متجهات Query ($Q$) و Key ($K$) في المساحة المعقدة. بالنسبة لمتجه ثنائي الأبعاد، يتم تعريف الدوران على أنه:
$$R_{\Theta, m}^d x_m = \begin{pmatrix} \cos m\theta & -\sin m\theta \\ \sin m\theta & \cos m\theta \end{pmatrix} \begin{pmatrix} x_{m, 1} \\ x_{m, 2} \end{pmatrix}$$
تضمن هذه الصياغة أن الضرب النقطي بين الاستعلام في الموضع $m$ والمفتاح في الموضع $n$ يعتمد فقط على المسافة النسبية بينهما $m - n$:
$$\langle R_{\Theta, m}^d q_m, R_{\Theta, n}^d k_n \rangle = g(q, k, m - n)$$
يسمح RoPE للنموذج بالاستقراء بشكل طبيعي لأطوال تسلسل أطول، وهو أمر بالغ الأهمية للتعامل مع نوافذ السياق الضخمة.
5. برمجة كتل Gemini بلغة PyTorch
أدناه وحدة PyTorch كاملة توضح كيفية تنفيذ Grouped-Query Attention (GQA) و شبكة SwiGLU Feed-Forward:
import torch
import torch.nn as nn
import torch.nn.functional as F
class SwiGLUFFN(nn.Module):
def __init__(self, d_model, hidden_dim):
super().__init__()
self.w_gate = nn.Linear(d_model, hidden_dim, bias=False)
self.w_val = nn.Linear(d_model, hidden_dim, bias=False)
self.w_down = nn.Linear(hidden_dim, d_model, bias=False)
def forward(self, x):
gate = F.silu(self.w_gate(x))
val = self.w_val(x)
return self.w_down(gate * val)
class GroupedQueryAttention(nn.Module):
def __init__(self, d_model, n_q_heads, n_kv_heads, d_k):
super().__init__()
self.n_q_heads = n_q_heads
self.n_kv_heads = n_kv_heads
self.d_k = d_k
self.group_size = n_q_heads // n_kv_heads
self.q_proj = nn.Linear(d_model, n_q_heads * d_k, bias=False)
self.k_proj = nn.Linear(d_model, n_kv_heads * d_k, bias=False)
self.v_proj = nn.Linear(d_model, n_kv_heads * d_k, bias=False)
self.out_proj = nn.Linear(n_q_heads * d_k, d_model, bias=False)
def forward(self, x):
batch, seq_len, _ = x.shape
q = self.q_proj(x).view(batch, seq_len, self.n_q_heads, self.d_k).transpose(1, 2)
k = self.k_proj(x).view(batch, seq_len, self.n_kv_heads, self.d_k).transpose(1, 2)
v = self.v_proj(x).view(batch, seq_len, self.n_kv_heads, self.d_k).transpose(1, 2)
k = k.repeat_interleave(self.group_size, dim=1)
v = v.repeat_interleave(self.group_size, dim=1)
scores = torch.matmul(q, k.transpose(-2, -1)) / (self.d_k ** 0.5)
mask = torch.triu(torch.ones(seq_len, seq_len, device=x.device), diagonal=1).bool()
scores = scores.masked_fill(mask, float('-inf'))
attn_weights = F.softmax(scores, dim=-1)
context = torch.matmul(attn_weights, v)
context = context.transpose(1, 2).contiguous().view(batch, seq_len, -1)
return self.out_proj(context)
6. مقارنة هيكلية: BERT مقابل GPT مقابل Gemini
| الميزة | BERT (Encoder) | GPT (Decoder) | Gemini (Multimodal Decoder) |
|---|---|---|---|
| وسائط المدخلات | نص فقط | نص فقط | نص، صور، صوت، فيديو، كود |
| نوع الانتباه | انتباه ثنائي الاتجاه | انتباه سببي (MHA) | Grouped-Query Attention (GQA) |
| ترميز الموضع | متعلَّم / مطلق | متعلَّم / مطلق | Rotary Position Embeddings (RoPE) |
| التنشيط | GeLU | GeLU | SwiGLU |
| قيود النطاق | سياق قصير | سياق متوسط | سياق ممتد بشكل كبير |
خاتمة
يمثل Gemini من Google مرحلة نضوج هيكل الترانسفورمر. من خلال اختيار GQA لحل عقبة ذاكرة التخزين المؤقت KV، و SwiGLU لتحسين قدرة النموذج، و RoPE لتمكين الاستقراء للتسلسلات الطويلة، أنشأت Google هيكلاً يمكنه معالجة مدخلات حسية متنوعة بشكل أصلي دون فقدان البساطة الرياضية التي جعلت الترانسفورمر ناجحاً في المقام الأول.