Come funciona il modello Transformer di Gemini: GQA, SwiGLU e multimodalità nativa
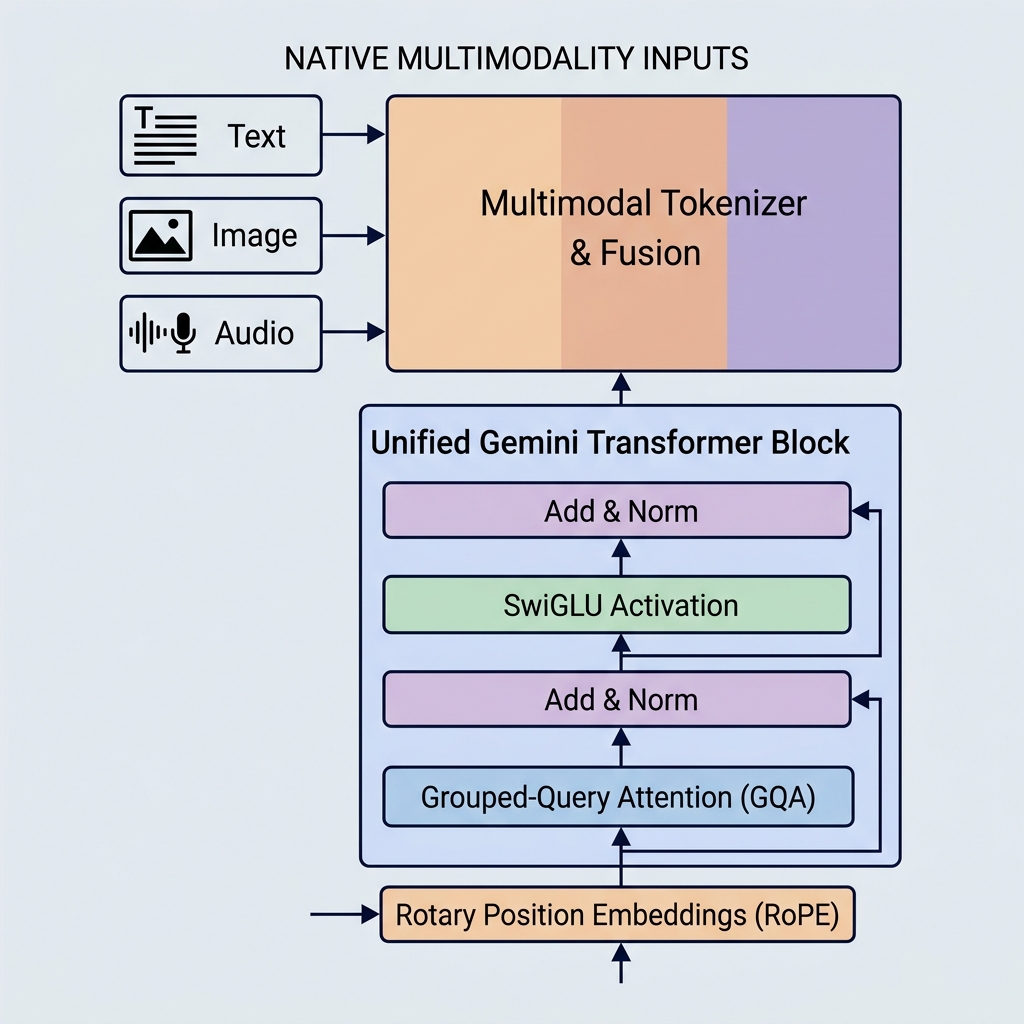
I modelli Gemini di Google hanno stabilito nuovi standard di riferimento nelle capacità dell’IA introducendo multimodalità nativa, enormi finestre di contesto e ottimizzazioni architetturali chiave. A differenza dei modelli più vecchi como GPT-3 o BERT, Gemini è costruito per gestire diversi tipi di dati fin dal primo giorno e utiliza meccanismi di attenzione altamente efficienti.
In questo articolo analizzeremo le scelte architetturali principali del modello Gemini Transformer, esploreremo come si confrontano con le architetture tradizionali e implementeremo Grouped-Query Attention (GQA) e reti Feed-Forward SwiGLU in PyTorch.
1. Multimodalità nativa (Spazio di embedding unificato)
I sistemi di IA tradizionali ottengono un comportamento multimodale assemblando modelli separati. Ad esempio, potrebbero associare un encoder di immagini (come CLIP) o un processore audio (come Whisper) a un modello di testo pre-addestrato utilizzando livelli di mappatura o adattatori.
Gemini è costruito in modo diverso. È nativamente multimodale, il che significa che è stato addestrato simultaneamente su diverse modalità (testo, codice, immagini, audio e video) fin dall’inizio.
- Tokenizer unificato: Invece di pipeline di pre-elaborazione separate, i diversi input vengono convertiti in token in uno spazio di embedding latente condiviso e unificato.
- Ragionamento cross-modale: Poiché lo spazio di rappresentazione è condiviso, un singolo blocco decoder può prestare attenzione a un token visivo, a un token audio e a un token di testo esattamente nella stessa sequenza. Ciò consente a Gemini di eseguire compiti complessi come spiegare fotogrammi video o tradurre direttamente l’audio in testo.
2. Grouped-Query Attention (GQA)
Con l’espansione delle finestre di contesto (fino a milioni di token), l’impronta di memoria della cache Key-Value (KV) diventa un importante collo di bottiglia per il servizio.
Per risolvere questo problema:
- Multi-Head Attention (MHA): Ogni testa Query ($Q$) ha una testa Key ($K$) e Value ($V$) corrispondente. Se ci sono 32 teste, dobbiamo memorizzare 32 set di vettori KV.
- Multi-Query Attention (MQA): Tutte le teste Query condividono una singola testa Key e Value. Sebbene ciò risparmi memoria, riduce la capacità del modello e la qualità dell’output.
- Grouped-Query Attention (GQA): Le teste Query vengono raggruppate (ad esempio, in 8 gruppi di 4 teste). Ciascun gruppo condivide una testa Key e Value.
$$\text{Scores} = QK^T \text{ computation in GQA groups Q heads to share a single KV pair}$$
La GQA funge da via di mezzo, recuperando quase tutta la qualità della MHA e offrendo al contempo velocità di inferenza e risparmio di memoria vicini alla MQA.
3. Funzione di attivazione SwiGLU
Invece dell’attivazione GeLU standard utilizzata in BERT e nei modelli GPT più vecchi, Gemini utilizza SwiGLU (Swish-Gated Linear Unit) nei suoi blocchi feed-forward.
Una gated linear unit (GLU) è un livello di rete neurale definito come il prodotto elemento per elemento di due trasformazioni lineari, una delle quali è controllata da un’attivazione sigmoidea. SwiGLU sostituisce il sigmoide con un’attivazione Swish (o SiLU):
$$\text{SwiGLU}(x) = \text{Swish}_\beta(x W) \otimes (x V)$$
Dove:
- $W$ e $V$ sono matrici di pesi di proiezione lineare.
- $\otimes$ rappresenta la moltiplicazione elemento per elemento.
- $\text{Swish}(x) = x \cdot \sigma(\beta x)$ funge da meccanismo di gating.
È stato dimostrato che SwiGLU converge più velocemente durante l’addestramento e porta a una maggiore precisione nei compiti a valle rispetto alle attivazioni standard GeLU o ReLU.
4. Rotary Position Embeddings (RoPE)
A differenza dei Transformer originali che aggiungevano vettori di embedding posizionale assoluto agli embedding dei token di input, i modelli Gemini utilizzano Rotary Position Embeddings (RoPE).
RoPE codifica le informazioni posizionali ruotando i vettori Query ($Q$) e Key ($K$) nello spazio complesso. Per un vettore 2D, la rotazione è definita come:
$$R_{\Theta, m}^d x_m = \begin{pmatrix} \cos m\theta & -\sin m\theta \\ \sin m\theta & \cos m\theta \end{pmatrix} \begin{pmatrix} x_{m, 1} \\ x_{m, 2} \end{pmatrix}$$
Questa formulazione garantisce che il prodotto scalare tra una query alla posizione $m$ e una chiave alla posizione $n$ dipenda solo dalla loro distanza relativa $m - n$:
$$\langle R_{\Theta, m}^d q_m, R_{\Theta, n}^d k_n \rangle = g(q, k, m - n)$$
RoPE consente al modello di estrapolare naturalmente a sequenze più lunghe, il che è fondamentale per gestire enormi finestre di contesto.
5. Implementazione PyTorch dei blocchi di Gemini
Di seguito è riportato un modulo PyTorch completo che mostra come implementare Grouped-Query Attention (GQA) e una rete Feed-Forward SwiGLU:
import torch
import torch.nn as nn
import torch.nn.functional as F
class SwiGLUFFN(nn.Module):
def __init__(self, d_model, hidden_dim):
super().__init__()
self.w_gate = nn.Linear(d_model, hidden_dim, bias=False)
self.w_val = nn.Linear(d_model, hidden_dim, bias=False)
self.w_down = nn.Linear(hidden_dim, d_model, bias=False)
def forward(self, x):
gate = F.silu(self.w_gate(x))
val = self.w_val(x)
return self.w_down(gate * val)
class GroupedQueryAttention(nn.Module):
def __init__(self, d_model, n_q_heads, n_kv_heads, d_k):
super().__init__()
self.n_q_heads = n_q_heads
self.n_kv_heads = n_kv_heads
self.d_k = d_k
self.group_size = n_q_heads // n_kv_heads
self.q_proj = nn.Linear(d_model, n_q_heads * d_k, bias=False)
self.k_proj = nn.Linear(d_model, n_kv_heads * d_k, bias=False)
self.v_proj = nn.Linear(d_model, n_kv_heads * d_k, bias=False)
self.out_proj = nn.Linear(n_q_heads * d_k, d_model, bias=False)
def forward(self, x):
batch, seq_len, _ = x.shape
q = self.q_proj(x).view(batch, seq_len, self.n_q_heads, self.d_k).transpose(1, 2)
k = self.k_proj(x).view(batch, seq_len, self.n_kv_heads, self.d_k).transpose(1, 2)
v = self.v_proj(x).view(batch, seq_len, self.n_kv_heads, self.d_k).transpose(1, 2)
k = k.repeat_interleave(self.group_size, dim=1)
v = v.repeat_interleave(self.group_size, dim=1)
scores = torch.matmul(q, k.transpose(-2, -1)) / (self.d_k ** 0.5)
mask = torch.triu(torch.ones(seq_len, seq_len, device=x.device), diagonal=1).bool()
scores = scores.masked_fill(mask, float('-inf'))
attn_weights = F.softmax(scores, dim=-1)
context = torch.matmul(attn_weights, v)
context = context.transpose(1, 2).contiguous().view(batch, seq_len, -1)
return self.out_proj(context)
6. Confronto architetturale: BERT vs. GPT vs. Gemini
| Caratteristica | BERT (Encoder) | GPT (Decoder) | Gemini (Decoder Multimodale) |
|---|---|---|---|
| Modalità di input | Solo testo | Solo testo | Testo, immagini, audio, video, codice |
| Tipo di attenzione | Attenzione bidirezionale | Attenzione causale (MHA) | Grouped-Query Attention (GQA) |
| Codifica posizionale | Appresa / Assoluta | Appresa / Assoluta | Rotary Position Embeddings (RoPE) |
| Attivazione | GeLU | GeLU | SwiGLU |
| Limite di scala | Contesto breve | Contesto medio | Contesto massicciamente esteso |
Conclusione
Gemini di Google rappresenta la maturazione dell’architettura Transformer. Scegliendo GQA per risolvere il collo di bottiglia della cache KV, SwiGLU per ottimizzare la capacità del modello e RoPE per consentire l’estrapolazione su sequenze lunghe, Google ha creato un’architettura in grado di digerire diversi input sensoriali in modo nativo senza perdere la semplicità matematica che ha reso il Transformer un successo in primo luogo.
Esplora altre prospettive tecnologiche sul Blog di Ghaznix →