Gemini Transformer 模型如何工作:GQA、SwiGLU 和原生多模态
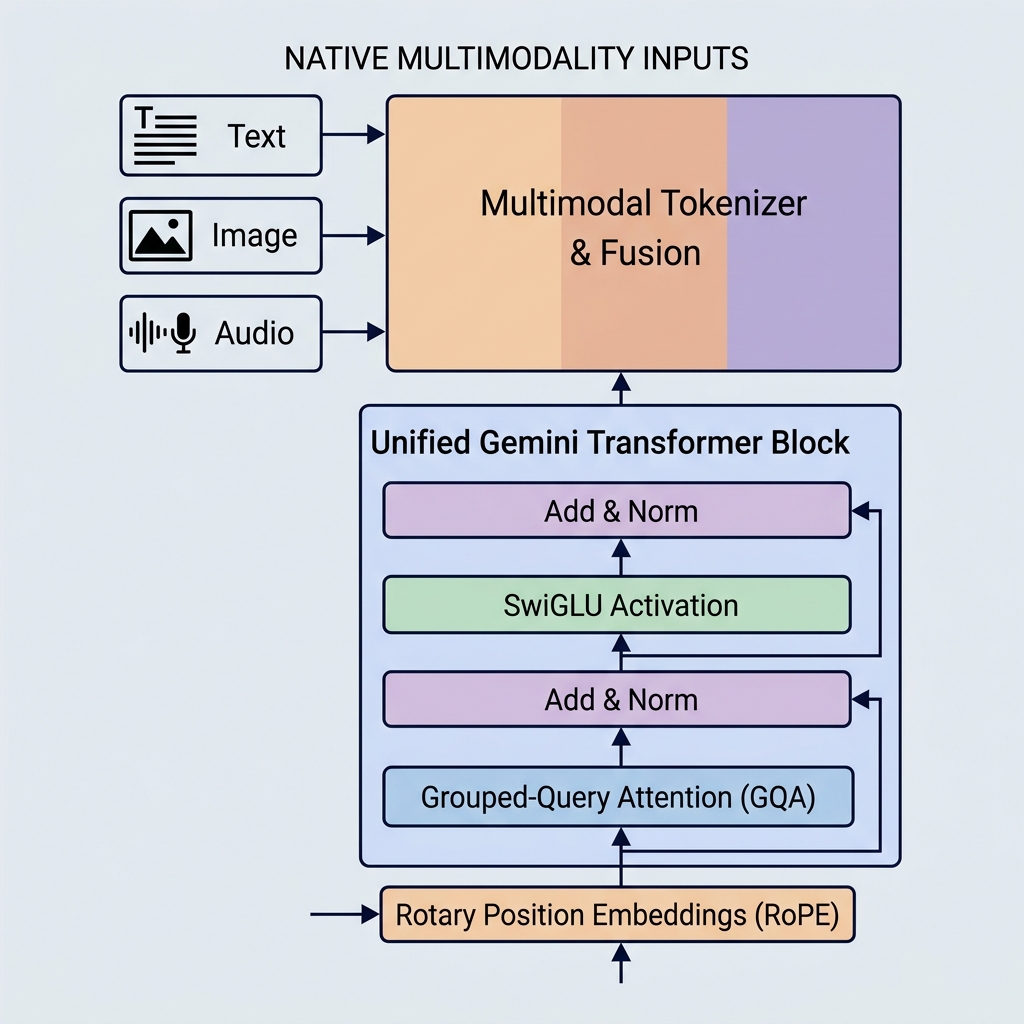
谷歌的 Gemini 模型通过引入原生多模态、超长上下文窗口以及关键的架构优化,树立了 AI 能力的新标杆。与 GPT-3 或 BERT 等旧模型不同,Gemini 从设计之初就是为了处理多种数据类型,并使用了极高效率的注意力机制。
在本文中,我们将深入解析 Gemini Transformer 核心的架构选择,探索它们与传统架构的不同之处,并使用 PyTorch 实现分组查询注意力(GQA)和 SwiGLU 前馈网络。
1. 原生多模态(统一嵌入空间)
传统的 AI 系统是通过拼接不同的模型来实现多模态行为的。例如,它们会使用映射层或适配器,将图像编码器(如 CLIP)或音频处理器(如 Whisper)与预训练的文本模型配对。
Gemini 则完全不同。它是原生多模态的,这意味着它在开发初期就同时在不同的模态(文本、代码、图像、音频和视频)上进行预训练。
- 统一的分词器(Tokenizer): 不同类型的输入不需要经过独立的预处理流水线,而是被统一转换为共享的潜在嵌入空间中的 token。
- 跨模态推理: 由于表示空间是共享的,单个解码器(decoder)块可以在同一个序列中同时处理视觉 token、音频 token 和文本 token。这使得 Gemini 能够直接执行复杂任务,如解释视频帧或直接将音频翻译为文本。
2. 分组查询注意力(Grouped-Query Attention, GQA)
随着上下文窗口的扩大(可达数百万个 token),键值(KV)缓存的内存占用成为了模型推理服务的主要瓶颈。
为了解决这个问题:
- 多头注意力(MHA): 每个查询头(Query head, $Q$)都有一个匹配的键(Key, $K$)和值(Value, $V$)头。如果有 32 个头,我们就必须存储 32 组 KV 向量。
- 多查询注意力(MQA): 所有查询头共享一个键和值头。虽然这节省了内存,但会降低模型的表达能力和输出质量。
- 分组查询注意力(GQA): 查询头被分组(例如,分为 8 组,每组包含 4 个查询头)。每组共享一个键和值头。
$$\text{Scores} = QK^T \text{ computation in GQA groups Q heads to share a single KV pair}$$
GQA 作为折中方案,在恢复了 MHA 几乎所有生成质量的同时,提供了接近 MQA 的推理速度和内存节省。
3. SwiGLU 激活函数
Gemini 在其前馈神经网络(FFN)块中使用了 SwiGLU(Swish 门控线性单元),而不是 BERT 和较旧的 GPT 模型中使用的标准 GeLU 激活函数。
门控线性单元(GLU)是一个神经网络层,定义为两个线性变换的逐元素乘积,其中 one of which is gated by a sigmoid 激活。SwiGLU 将其中的 sigmoid 替换为 Swish(或 SiLU)激活函数:
$$\text{SwiGLU}(x) = \text{Swish}_\beta(x W) \otimes (x V)$$
其中:
- $W$ 和 $V$ 是线性投影的权重矩阵。
- $\otimes$ 代表逐元素相乘。
- $\text{Swish}(x) = x \cdot \sigma(\beta x)$ 作为门控机制。
研究表明,与标准的 GeLU 或 ReLU 激活相比,SwiGLU 在训练期间收敛更快,并且能提升下游任务的准确度。
4. 旋转位置嵌入(Rotary Position Embeddings, RoPE)
与在输入 token 嵌入中加入绝对位置编码向量的原始 Transformer 不同,Gemini 模型采用了旋转位置嵌入(RoPE)。
RoPE 通过在复数空间中旋转查询($Q$)和键($K$)向量来编码位置信息。对于 2D 向量,旋转定义为:
$$R_{\Theta, m}^d x_m = \begin{pmatrix} \cos m\theta & -\sin m\theta \\ \sin m\theta & \cos m\theta \end{pmatrix} \begin{pmatrix} x_{m, 1} \\ x_{m, 2} \end{pmatrix}$$
这种形式保证了位置 $m$ 的查询和位置 $n$ 的键的点积仅取决于它们的相对距离 $m - n$:
$$\langle R_{\Theta, m}^d q_m, R_{\Theta, n}^d k_n \rangle = g(q, k, m - n)$$
RoPE 允许模型自然地外推到更长的序列长度,这对于处理超长上下文窗口至关重要。
5. Gemini 架构块的 PyTorch 实现
下面是一个完整的 PyTorch 模块,演示了如何实现**分组查询注意力(GQA)**和 SwiGLU 前馈网络:
import torch
import torch.nn as nn
import torch.nn.functional as F
class SwiGLUFFN(nn.Module):
def __init__(self, d_model, hidden_dim):
super().__init__()
self.w_gate = nn.Linear(d_model, hidden_dim, bias=False)
self.w_val = nn.Linear(d_model, hidden_dim, bias=False)
self.w_down = nn.Linear(hidden_dim, d_model, bias=False)
def forward(self, x):
gate = F.silu(self.w_gate(x))
val = self.w_val(x)
return self.w_down(gate * val)
class GroupedQueryAttention(nn.Module):
def __init__(self, d_model, n_q_heads, n_kv_heads, d_k):
super().__init__()
self.n_q_heads = n_q_heads
self.n_kv_heads = n_kv_heads
self.d_k = d_k
self.group_size = n_q_heads // n_kv_heads
self.q_proj = nn.Linear(d_model, n_q_heads * d_k, bias=False)
self.k_proj = nn.Linear(d_model, n_kv_heads * d_k, bias=False)
self.v_proj = nn.Linear(d_model, n_kv_heads * d_k, bias=False)
self.out_proj = nn.Linear(n_q_heads * d_k, d_model, bias=False)
def forward(self, x):
batch, seq_len, _ = x.shape
q = self.q_proj(x).view(batch, seq_len, self.n_q_heads, self.d_k).transpose(1, 2)
k = self.k_proj(x).view(batch, seq_len, self.n_kv_heads, self.d_k).transpose(1, 2)
v = self.v_proj(x).view(batch, seq_len, self.n_kv_heads, self.d_k).transpose(1, 2)
k = k.repeat_interleave(self.group_size, dim=1)
v = v.repeat_interleave(self.group_size, dim=1)
scores = torch.matmul(q, k.transpose(-2, -1)) / (self.d_k ** 0.5)
mask = torch.triu(torch.ones(seq_len, seq_len, device=x.device), diagonal=1).bool()
scores = scores.masked_fill(mask, float('-inf'))
attn_weights = F.softmax(scores, dim=-1)
context = torch.matmul(attn_weights, v)
context = context.transpose(1, 2).contiguous().view(batch, seq_len, -1)
return self.out_proj(context)
6. 架构对比:BERT vs. GPT vs. Gemini
| 特性 | BERT (编码器) | GPT (解码器) | Gemini (多模态解码器) |
|---|---|---|---|
| 输入模态 | 仅文本 | 仅文本 | 文本、图像、音频、视频、代码 |
| 注意力类型 | 双向注意力 | 因果注意力 (MHA) | 分组查询注意力 (GQA) |
| 位置编码 | 学习得到 / 绝对位置 | 学习得到 / 绝对位置 | 旋转位置嵌入 (RoPE) |
| 激活函数 | GeLU | GeLU | SwiGLU |
| 缩放限制 | 短上下文 | 中等上下文 | 极长上下文窗口 |
结论
谷歌的 Gemini 代表了 Transformer 架构的成熟。通过选择 GQA 来解决 KV 缓存瓶颈,使用 SwiGLU 来优化模型能力,以及使用 RoPE 来支持长序列外推,谷歌创造了一种能够原生消化多种感官输入且保留了 Transformer 数学简洁性的领先架构。