Gemini 트랜스포머 모델의 작동 원리: GQA, SwiGLU 및 네이티브 멀티모달리티
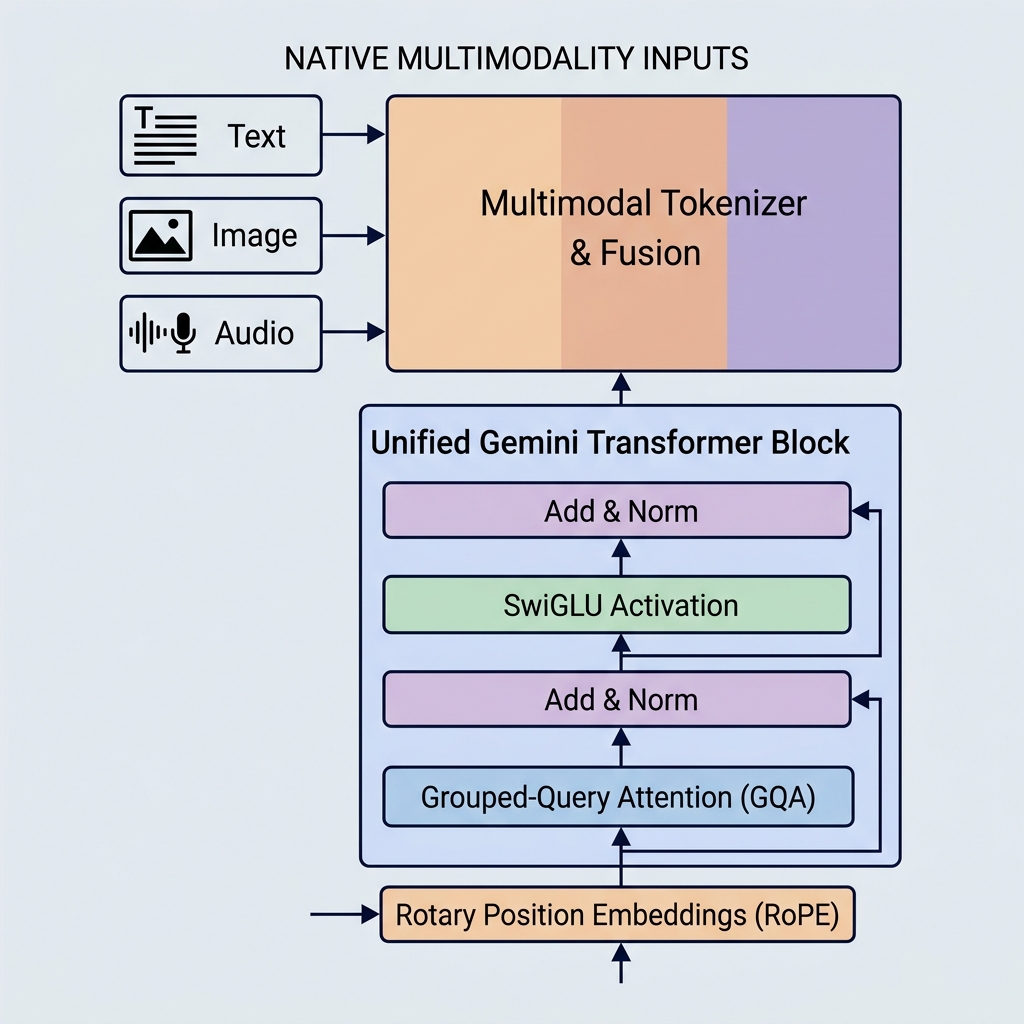
Google의 Gemini 모델은 네이티브 멀티모달리티, 거대한 컨텍스트 창, 주요 아키텍처 최적화를 도입하여 AI 기능의 새로운 기준을 세웠습니다. GPT-3나 BERT와 같은 기존 모델과 달리 Gemini는 처음부터 여러 데이터 유형을 처리하도록 설계되었으며 매우 효율적인 어텐션 메커니즘을 사용합니다.
이 글에서는 Gemini 트랜스포머 모델의 핵심 아키텍처 선택을 알아보고, 기존 아키텍처와 어떻게 비교되는지 분석하며, PyTorch로 그룹화 쿼리 어텐션(GQA) 및 SwiGLU 피드포워드 네트워크를 구현해 봅니다.
1. 네이티브 멀티모달리티 (통합 임베딩 공간)
기존 AI 시스템은 별도의 모델을 연결하여 멀티모달 동작을 수행했습니다. 예를 들어, 매핑 레이어나 어댑터를 사용하여 이미지 인코더(CLIP 등) 또는 오디오 프로세서(Whisper 등)를 사전 학습된 텍스트 모델과 연결하는 방식입니다.
Gemini는 다르게 설계되었습니다. 네이티브 멀티모달(natively multimodal) 모델로, 처음부터 여러 모달리티(텍스트, 코드, 이미지, 오디오, 비디오)를 동시에 학습했습니다.
- 통합 토크나이저: 별도의 전처리 파이프라인 대신, 서로 다른 입력이 하나의 공유된 통합 잠재 임베딩 공간의 토큰으로 변환됩니다.
- 크로스 모달 추론: 표현 공간이 공유되기 때문에 단일 디코더 블록이 동일한 시퀀스 내에서 시각 토큰, 오디오 토큰, 텍스트 토큰에 동시에 주의를 기울일 수 있습니다. 이를 통해 Gemini는 비디오 프레임을 설명하거나 오디오를 텍스트로 직접 번역하는 것과 같은 복잡한 작업을 수행할 수 있습니다.
2. 그룹화 쿼리 어텐션 (Grouped-Query Attention, GQA)
컨텍스트 창이 늘어남에 따라(수백만 토큰까지) 키-값(KV) 캐시의 메모리 점유율이 서빙의 주요 병목 현상이 됩니다.
이를 해결하기 위해:
- 다중 헤드 어텐션 (MHA): 모든 쿼리 헤드($Q$)에 일치하는 키($K$) 및 값($V$) 헤드가 있습니다. 헤드가 32개라면 32개의 KV 벡터 세트를 저장해야 합니다.
- 다중 쿼리 어텐션 (MQA): 모든 쿼리 헤드가 하나의 키 및 값 헤드를 공유합니다. 메모리는 절약되지만 모델의 용량과 출력 품질이 저하됩니다.
- 그룹화 쿼리 어텐션 (GQA): 쿼리 헤드가 그룹화됩니다(예: 4개 헤드씩 8개 그룹). 각 그룹은 하나의 키 및 값 헤드를 공유합니다.
$$\text{Scores} = QK^T \text{ computation in GQA groups Q heads to share a single KV pair}$$
GQA는 절충안 역할을 하여 MHA의 품질을 거의 대부분 회복하면서도 MQA에 가까운 추론 속도와 메모리 절감 효과를 제공합니다.
3. SwiGLU 활성화 함수
BERT 및 이전 GPT 모델에서 사용되는 표준 GeLU 활성화 대신 Gemini는 피드포워드 블록에서 SwiGLU(Swish-Gated Linear Unit)를 사용합니다.
게이트형 선형 유닛(GLU)은 두 선형 변환의 원소별 곱으로 정의되는 신경망 레이어로, 그 중 하나는 시그모이드 활성화에 의해 게이트됩니다. SwiGLU는 시그모이드를 Swish(또는 SiLU) 활성화로 대체합니다.
$$\text{SwiGLU}(x) = \text{Swish}_\beta(x W) \otimes (x V)$$
여기서:
- $W$와 $V$는 선형 투영 가중치 행렬입니다.
- $\otimes$는 원소별 곱셈을 나타냅니다.
- $\text{Swish}(x) = x \cdot \sigma(\beta x)$는 게이팅 메커니즘으로 작동합니다.
SwiGLU는 표준 GeLU 또는 ReLU 활성화에 비해 학습 시 더 빠르게 수렴하고 다운스트림 태스크의 정확도를 높이는 것으로 나타났습니다.
4. 회전 위치 임베딩 (Rotary Position Embeddings, RoPE)
입력 토큰 임베딩에 절대적인 위치 임베딩 벡터를 더했던 기존 트랜스포머와 달리 Gemini 모델은 **회전 위치 임베딩(RoPE)**을 사용합니다.
RoPE는 복소수 공간에서 쿼리($Q$) 및 키($K$) 벡터를 회전시켜 위치 정보를 인코딩합니다. 2차원 벡터의 경우 회전은 다음과 같이 정의됩니다.
$$R_{\Theta, m}^d x_m = \begin{pmatrix} \cos m\theta & -\sin m\theta \\ \sin m\theta & \cos m\theta \end{pmatrix} \begin{pmatrix} x_{m, 1} \\ x_{m, 2} \end{pmatrix}$$
이 공식은 위치 $m$의 쿼리와 위치 $n$의 키 사이의 내적이 상대적 거리인 $m - n$에만 의존함을 보장합니다.
$$\langle R_{\Theta, m}^d q_m, R_{\Theta, n}^d k_n \rangle = g(q, k, m - n)$$
RoPE를 사용하면 모델이 더 긴 시퀀스 길이로 자연스럽게 외삽할 수 있어 거대한 컨텍스트 창을 처리하는 데 매우 중요합니다.
5. Gemini 블록의 PyTorch 구현
다음은 그룹화 쿼리 어텐션(GQA) 및 SwiGLU 피드포워드 네트워크를 구현하는 방법을 보여주는 전체 PyTorch 모듈입니다.
import torch
import torch.nn as nn
import torch.nn.functional as F
class SwiGLUFFN(nn.Module):
def __init__(self, d_model, hidden_dim):
super().__init__()
self.w_gate = nn.Linear(d_model, hidden_dim, bias=False)
self.w_val = nn.Linear(d_model, hidden_dim, bias=False)
self.w_down = nn.Linear(hidden_dim, d_model, bias=False)
def forward(self, x):
gate = F.silu(self.w_gate(x))
val = self.w_val(x)
return self.w_down(gate * val)
class GroupedQueryAttention(nn.Module):
def __init__(self, d_model, n_q_heads, n_kv_heads, d_k):
super().__init__()
self.n_q_heads = n_q_heads
self.n_kv_heads = n_kv_heads
self.d_k = d_k
self.group_size = n_q_heads // n_kv_heads
self.q_proj = nn.Linear(d_model, n_q_heads * d_k, bias=False)
self.k_proj = nn.Linear(d_model, n_kv_heads * d_k, bias=False)
self.v_proj = nn.Linear(d_model, n_kv_heads * d_k, bias=False)
self.out_proj = nn.Linear(n_q_heads * d_k, d_model, bias=False)
def forward(self, x):
batch, seq_len, _ = x.shape
q = self.q_proj(x).view(batch, seq_len, self.n_q_heads, self.d_k).transpose(1, 2)
k = self.k_proj(x).view(batch, seq_len, self.n_kv_heads, self.d_k).transpose(1, 2)
v = self.v_proj(x).view(batch, seq_len, self.n_kv_heads, self.d_k).transpose(1, 2)
k = k.repeat_interleave(self.group_size, dim=1)
v = v.repeat_interleave(self.group_size, dim=1)
scores = torch.matmul(q, k.transpose(-2, -1)) / (self.d_k ** 0.5)
mask = torch.triu(torch.ones(seq_len, seq_len, device=x.device), diagonal=1).bool()
scores = scores.masked_fill(mask, float('-inf'))
attn_weights = F.softmax(scores, dim=-1)
context = torch.matmul(attn_weights, v)
context = context.transpose(1, 2).contiguous().view(batch, seq_len, -1)
return self.out_proj(context)
6. 아키텍처 비교: BERT vs. GPT vs. Gemini
| 특징 | BERT (인코더) | GPT (디코더) | Gemini (멀티모달 디코더) |
|---|---|---|---|
| 입력 모달리티 | 텍스트만 | 텍스트만 | 텍스트, 이미지, 오디오, 비디오, 코드 |
| 어텐션 타입 | 양방향 어텐션 | 인과 어텐션 (MHA) | 그룹화 쿼리 어텐션 (GQA) |
| 위치 인코딩 | 학습형 / 절대 | 학습형 / 절대 | 회전 위치 임베딩 (RoPE) |
| 활성화 함수 | GeLU | GeLU | SwiGLU |
| 스케일 제약 | 짧은 컨텍스트 | 중간 컨텍스트 | 대규모로 확장된 컨텍스트 |
결론
Google의 Gemini는 트랜스포머 아키텍처의 성숙을 보여줍니다. KV 캐시 병목 현상을 해결하기 위해 GQA를, 모델 용량을 최적화하기 위해 SwiGLU를, 긴 시퀀스 외삽을 위해 RoPE를 선택함으로써 Google은 트랜스포머를 성공으로 이끈 수학적 단순함을 잃지 않으면서도 다양한 감각 입력을 네이티브로 처리할 수 있는 아키텍처를 창조했습니다.