BERTの理解:Transformersによる双方向エンコーダ表現
2018年、Googleの研究者らは、「BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding」(Devlinら)という画期的な論文を発表しました。この研究は、自然言語処理(NLP)の分野を根本から変えました。BERT以前のモデルは、テキストを左から右、または右から左へと順次処理していました。BERTは、両方向からの文脈を同時に考慮する言語表現を学習する手法を導入しました。
現在でも、BERTとその派生モデル(RoBERTa、DistilBERT、ALBERTなど)は、検索エンジン、感情分析、質問応答システム、情報抽出の基盤であり続けています。この記事では、BERTのアーキテクチャ、仕組み、および学習方法について詳しく解説します。
1. BERTとは何か?
BERTは Bidirectional Encoder Representations from Transformers(Transformersによる双方向のエンコーダ表現)の略です。この名前を分解してみましょう。
- 双方向(Bidirectional): テキストを左から右(GPTなど)または右から左に読み込む従来の言語モデルとは異なり、BERTは単語のシーケンス全体を一度に読み込みます。これにより、単語の左右両方の周囲すべての環境に基づいて、その単語の文脈を学習できます。
- エンコーダ表現(Encoder Representations): BERTは、オリジナルのTransformerアーキテクチャの**エンコーダ(Encoder)**部分を使用します。入力シーケンスを受け取り、各トークンに対して密なベクトル表現(埋め込み/embedding)を出力します。
- Transformers: 基盤となるエンジンはTransformerのアテンション(注意)ネットワークであり、長距離の依存関係のモデリングと並列計算を可能にします。
双方向性の力
単方向モデルでは、トークンはそれ以前のトークンにしかアテンションを向けることができません。例えば、次の文を考えてみましょう。
「彼は銀行(bank)にお金を預けることに決めた。」
単方向モデルが「bank」を処理する場合、それより前にある単語しか見ません。しかし、文脈を完全に理解するには、左右両方の文脈を見ることが極めて重要です。双方向LSTMは、左から右と右から左のモデルを個別に学習して出力を結合することでこれを試みましたが、BERTはすべてのレイヤーで最初から単一の深い双方向モデルを共同で学習します。
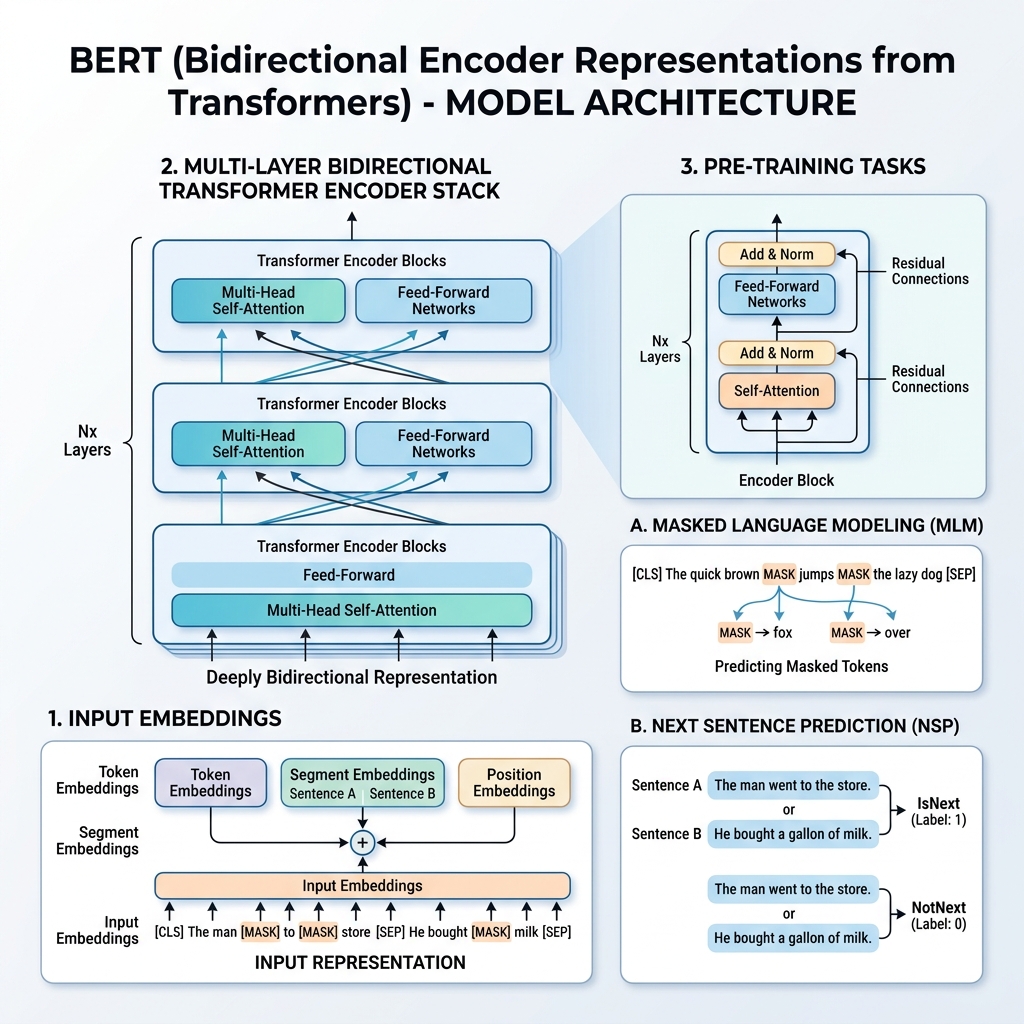
2. BERTの入力表現
様々な下流タスクでの学習を可能にするため、BERTの入力表現は、単一のトークンシーケンス内で、単一の文と文のペア(例:<質問, 回答>)の両方を表現できます。
任意のトークンについて、その入力表現は次の3つの埋め込みを合算して構築されます。
- トークン埋め込み(Token Embeddings): テキストは WordPiece ボキャブラリ(約30,000トークン)を使用してトークン化されます。特殊トークンが追加されます。
[CLS]:すべてのシーケンスの先頭に挿入されます。その最終隠れ状態は分類タスクに使用されます。[SEP]:文を区切るため、またはシーケンスの末尾に使用されます。
- セグメント埋め込み(Segment Embeddings): トークンが文Aと文Bのどちらに属しているかを示す、学習された埋め込み。
- 位置埋め込み(Position Embeddings): シーケンス内のトークンの位置をモデルに認識させるために追加される、学習された位置ベクトル(最大512トークン)。
$$\text{入力表現} = \text{トークン埋め込み} + \text{セグメント埋め込み} + \text{位置埋め込み}$$
3. 事前学習プロセス
BERTは、**マスク化言語モデル(MLM)と隣接文予測(NSP)**という2つの自己教師ありタスクを同時に使用して、大規模なコーパス(WikipediaおよびBooksCorpus)で事前学習されます。
タスク1:マスク化言語モデル(MLM)
標準的な言語モデリングでは、次の単語を予測する際に、ターゲット単語が自分自身を「見る」のを防ぐため、モデルを左から右のアーキテクチャに制限します。深い双方向表現を学習するために、BERTは入力トークンの一定割合をランダムにマスクし、それらを予測します。
具体的には:
- 入力トークンの 15% がランダムに選択されます。
- 選択されたトークンのうち:
- 80% は
[MASK]トークンに置き換えられます。 - 10% はランダムな単語に置き換えられます。
- 10% は変更されずにそのまま保持されます。
- 80% は
このアプローチにより、微調整(fine-tuning)中にモデルが [MASK] トークンだけに依存するのを防ぎ(微調整中には [MASK] は現れないため)、文脈内のすべての単語に対して表現ベクトルを構築することを強制します。
タスク2:隣接文予測(NSP)
質問応答や自然言語推論など、多くの下流タスクは2つの文の間の関係を理解することに依存しています。文の関係性を学習させるために、BERTは二値分類タスクで事前学習されます。
事前学習用に文$A$と文$B$を選択する際:
- 50% の確率で、文$B$は文$A$の後に続く実際の次の文です(
IsNextとラベル付けされます)。 - 50% の確率で、文$B$はコーパスからランダムに選択された文です(
NotNextとラベル付けされます)。
[CLS] トークンの最終隠れベクトルが分類レイヤーに渡され、ラベルが予測されます。
4. BERTの微調整(Fine-Tuning)
BERTの最大の強みの1つは、その柔軟性です。事前学習は非常にコストがかかりますが、**微調整(ファインチューニング)**は非常に安価で高速です。最終出力レイヤーを入れ替えるだけで、BERTは様々な下流タスクに適用できます。
- 単一文分類タスク:(例:感情分析)。
[CLS]トークンの出力を使用します。 - 文ペア分類タスク:(例:自然言語推論)。
[CLS]トークンの出力を使用します。 - 質問応答タスク:(例:SQuAD)。ドキュメント内の回答の開始トークンと終了トークンの位置を予測します。
- 単一文のトークンタギングタスク:(例:固有表現抽出 - NER)。各トークンの出力表現を使用します。
5. Python / Hugging Face 実装例
以下は、事前学習済みのBERTモデルをロードし、Hugging Face Transformers と PyTorch を使用して文脈に応じた単語埋め込みを抽出する簡単なPythonの例です。
import torch
from transformers import BertTokenizer, BertModel
# 1. トークナイザとモデルの初期化
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertModel.from_pretrained('bert-base-uncased')
# 2. 2つの異なる文脈で "bank" という単語を含むテキストを定義
text_1 = "He deposited money in the bank."
text_2 = "The river bank was muddy."
# 3. 入力をトークン化
inputs_1 = tokenizer(text_1, return_tensors="pt")
inputs_2 = tokenizer(text_2, return_tensors="pt")
# 4. BERTの順伝播
with torch.no_grad():
outputs_1 = model(**inputs_1)
outputs_2 = model(**inputs_2)
# 5. トークン埋め込みの抽出
# last_hidden_state の形状: [batch_size, sequence_length, hidden_size]
embeddings_1 = outputs_1.last_hidden_state
embeddings_2 = outputs_2.last_hidden_state
# トークンとそのインデックスを確認
tokens_1 = tokenizer.convert_ids_to_tokens(inputs_1["input_ids"][0])
tokens_2 = tokenizer.convert_ids_to_tokens(inputs_2["input_ids"][0])
# 単語 'bank' のインデックスを取得
bank_idx_1 = tokens_1.index("bank")
bank_idx_2 = tokens_2.index("bank")
# 'bank' の埋め込みベクトルを取得
bank_emb_1 = embeddings_1[0, bank_idx_1]
bank_emb_2 = embeddings_2[0, bank_idx_2]
# コサイン類似度を計算
cosine_sim = torch.nn.functional.cosine_similarity(bank_emb_1, bank_emb_2, dim=0)
print("Tokens 1:", tokens_1)
print("Tokens 2:", tokens_2)
print(f"異なる文脈における 'bank' の埋め込み間のコサイン類似度: {cosine_sim.item():.4f}")
6. BERTモデルの構成
GoogleはBERTの2つの主要な構成を公開しました。
| ハイパーパラメータ | BERT-Base | BERT-Large |
|---|---|---|
| レイヤー数 ($L$) | 12 | 24 |
| 隠れ層サイズ ($H$) | 768 | 1024 |
| アテンションヘッド数 ($A$) | 12 | 16 |
| 総パラメータ数 | 1億1000万 | 3億4000万 |
結論
BERTは、大量のラベルなしテキストで学習された深い双方向表現が、複雑な構文的・意味的構造を捉えられることを証明しました。これは、NLPにおける転移学習の新しいパラダイムを確立し、自動回帰デコーダ専用モデル(GPTなど)が登場するまでAI分野を支配した「事前学習と微調整」のワークフローを築きました。