درک مدل BERT: نمایشهای رمزگذار دوطرفه از ترنسفورمرها
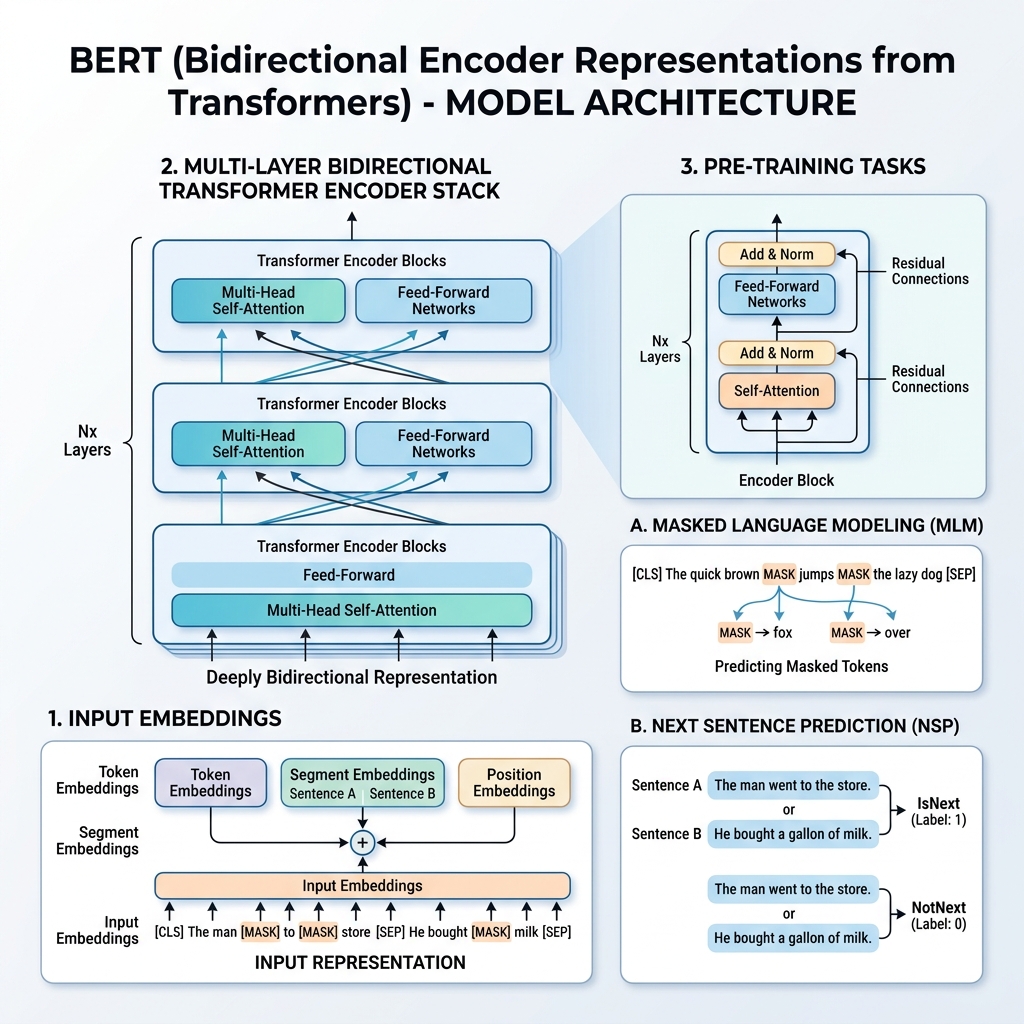
در سال ۲۰۱۸، محققان گوگل مقاله برجستهای با عنوان “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding” (Devlin et al.) منتشر کردند. این تحقیق به طور اساسی حوزه پردازش زبان طبیعی (NLP) را متحول کرد. پیش از BERT، مدلها متن را به صورت متوالی از چپ به راست یا راست به چپ پردازش میکردند. مدل BERT روشی را برای آموزش نمایشهای زبانی معرفی کرد که همزمان به بافتار از هر دو جهت نگاه میکند.
امروز، BERT و مشتقات آن (مانند RoBERTa و DistilBERT و ALBERT) به عنوان پایههای اصلی برای موتورهای جستجو، تحلیل احساسات، سیستمهای پاسخ به سوالات و استخراج اطلاعات باقی ماندهاند. این مقاله معماری BERT، نحوه کارکرد و نحوه آموزش آن را توضیح میدهد.
۱. مدل BERT چیست؟
واژه BERT مخفف عبارت Bidirectional Encoder Representations from Transformers (نمایشهای رمزگذار دوطرفه از ترنسفورمرها) است. بیایید این نام را تجزیه کنیم:
- دوطرفه (Bidirectional): برخلاف مدلهای زبانی سنتی که متن را از چپ به راست (مانند GPT) یا راست به چپ میخوانند، BERT کل توالی کلمات را به طور همزمان میخواند. این ویژگی به آن اجازه میدهد تا بافتار یک کلمه را بر اساس کل محیط اطراف آن (هم چپ و هم راست) یاد بگیرد.
- نمایشهای رمزگذار (Encoder Representations): مدل BERT از بخش رمزگذار (Encoder) معماری ترنسفورمر اصلی استفاده میکند. این مدل یک توالی ورودی را دریافت کرده و یک نمایش برداری متراکم (embedding) برای هر توکن خروجی میدهد.
- ترنسفورمرها (Transformers): موتور محرک زیرین، شبکه توجه (Attention) ترنسفورمر است که مدلسازی وابستگیهای طولانیمدت و محاسبات موازی را امکانپذیر میسازد.
قدرت پردازش دوطرفه
در مدلهای یکطرفه، یک توکن فقط میتواند به توکنهای قبلی توجه کند. به عنوان مثال، در جمله زیر:
"او تصمیم گرفت پول خود را در بانک سپردهگذاری کند."
اگر یک مدل یکطرفه کلمه "بانک" را پردازش کند، فقط به کلمات قبل از آن نگاه میکند. اما برای درک کامل بافتار، نگاه کردن به بافتار چپ و راست به طور همزمان حیاتی است. در حالی که مدلهای LSTM دوطرفه با آموزش مدلهای جداگانه چپ به راست و راست به چپ و اتصال خروجیها تلاش کردند این کار را انجام دهند، BERT یک مدل واحد و عمیقاً دوطرفه را به طور مشترک در تمام لایهها آموزش میدهد.
۲. نمایش ورودی BERT
برای امکانپذیر ساختن آموزش روی چندین کاربری پاییندستی، نمایش ورودی BERT میتواند هم یک تکجمله و هم یک جفتجمله (مانند <سوال، پاسخ>) را در یک توالی توکن واحد نشان دهد.
برای هر توکن داده شده، نمایش ورودی آن از جمع سه جاسازی (embedding) ساخته میشود:
- جاسازیهای توکن (Token Embeddings): متن با استفاده از واژگان WordPiece (حدود ۳۰,۰۰۰ توکن) توکنگذاری میشود. توکنهای خاصی اضافه میشوند:
[CLS]: در ابتدای هر توالی قرار میگیرد. حالت پنهان نهایی آن برای کارهای طبقهبندی استفاده میشود.[SEP]: برای جدا کردن جملهها یا در انتهای یک توالی استفاده میشود.
- جاسازیهای بخش (Segment Embeddings): یک جاسازی یادگرفتهشده که نشان میدهد آیا یک توکن به جمله A تعلق دارد یا جمله B.
- جاسازیهای موقعیت (Position Embeddings): بردارهای موقعیتی یادگرفتهشده که برای آگاهی مدل از موقعیت توکن در توالی اضافه میشوند (تا ۵۱۲ توکن).
$$\text{نمایش ورودی} = \text{جاسازیهای توکن} + \text{جاسازیهای بخش} + \text{جاسازیهای موقعیت}$$
۳. فرآیند پیشآموزش (Pre-training)
مدل BERT بر روی یک پیکره عظیم (ویکیپدیا و BooksCorpus) با استفاده از دو کار بدون نظارت به طور همزمان پیشآموزش داده میشود: مدل زبانی ماسکشده (MLM) و پیشبینی جمله بعدی (NSP).
کار ۱: مدل زبانی ماسکشده (MLM)
در مدلسازی استاندارد زبان، پیشبینی کلمه بعدی مدلها را به معماریهای چپ به راست محدود میکند تا از “دیدن” کلمه هدف توسط خودش جلوگیری شود. برای آموزش یک نمایش دوطرفه عمیق، BERT به طور تصادفی درصدی از توکنهای ورودی را ماسک (پوشانده) کرده و آنها را پیشبینی میکند.
به طور خاص:
۱. ۱۵٪ از توکنهای ورودی به طور تصادفی انتخاب میشوند.
۲. از میان توکنهای انتخاب شده:
* ۸۰٪ با توکن [MASK] جایگزین میشوند.
* ۱۰٪ با یک کلمه تصادفی جایگزین میشوند.
* ۱۰٪ بدون تغییر باقی میمانند.
این فرمول مانع از آن میشود که مدل در طول تنظیم دقیق فقط روی توکن [MASK] تمرکز کند (زیرا توکن ماسک هرگز در طول تنظیم دقیق ظاهر نمیشود) و آن را مجبور میکند تا بردارهای نمایش قوی برای هر کلمه در بافتار بسازد.
کار ۲: پیشبینی جمله بعدی (NSP)
بسیاری از کارهای پاییندستی (مانند پاسخ به سوالات و استنتاج زبان طبیعی) به درک رابطه بین دو جمله بستگی دارند. برای آموزش مدل روی روابط جملات، BERT روی یک کار طبقهبندی باینری پیشآموزش داده میشود:
هنگام انتخاب جملات $A$ و $B$ برای پیشآموزش:
- در ۵۰٪ مواقع، $B$ جمله بعدی واقعی است که بعد از $A$ میآید (با برچسب
IsNext). - در ۵۰٪ مواقع، $B$ یک جمله تصادفی از پیکره است (با برچسب
NotNext).
بردار پنهان نهایی توکن [CLS] به یک لایه طبقهبندی ارسال میشود تا برچسب را پیشبینی کند.
۴. تنظیم دقیق (Fine-Tuning) مدل BERT
یکی از بزرگترین نقاط قوت BERT انعطافپذیری آن است. پیشآموزش گران است، اما تنظیم دقیق بسیار ارزان و سریع است. با تعویض لایه خروجی نهایی، BERT میتواند روی بسیاری از کارهای پاییندستی مختلف اعمال شود:
- طبقهبندی تکجمله: (مانند تحلیل احساسات). استفاده از خروجی توکن
[CLS]. - طبقهبندی جفتجمله: (مانند استنتاج زبان طبیعی). استفاده از خروجی توکن
[CLS]. - پاسخ به سوالات: (مانند SQuAD). پیشبینی توکنهای شروع و پایان پاسخ در سند.
- برچسبگذاری تکجمله: (مانند تشخیص موجودیتهای نامگذاریشده - NER). استفاده از نمایش خروجی هر توکن به طور جداگانه.
۵. پیادهسازی در Python / Hugging Face
در زیر یک مثال ساده پایتون آورده شده است که نشان میدهد چگونه یک مدل پیشآموزشدیده BERT را بارگذاری کرده و جاسازیهای کلمات بافتاری را با استفاده از Hugging Face Transformers و PyTorch استخراج کنیم:
import torch
from transformers import BertTokenizer, BertModel
# ۱. راهاندازی توکنساز و مدل
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertModel.from_pretrained('bert-base-uncased')
# ۲. تعریف متنی که شامل کلمه "bank" در دو بافتار متفاوت است
text_1 = "He deposited money in the bank."
text_2 = "The river bank was muddy."
# ۳. توکنگذاری ورودیها
inputs_1 = tokenizer(text_1, return_tensors="pt")
inputs_2 = tokenizer(text_2, return_tensors="pt")
# ۴. عبور مستقیم از BERT
with torch.no_grad():
outputs_1 = model(**inputs_1)
outputs_2 = model(**inputs_2)
# ۵. استخراج جاسازیهای توکن
# ابعاد last_hidden_state به صورت [batch_size, sequence_length, hidden_size] است
embeddings_1 = outputs_1.last_hidden_state
embeddings_2 = outputs_2.last_hidden_state
# بررسی توکنها و شاخصهای آنها
tokens_1 = tokenizer.convert_ids_to_tokens(inputs_1["input_ids"][0])
tokens_2 = tokenizer.convert_ids_to_tokens(inputs_2["input_ids"][0])
# پیدا کردن شاخص کلمه 'bank'
bank_idx_1 = tokens_1.index("bank")
bank_idx_2 = tokens_2.index("bank")
# دریافت بردار جاسازی برای کلمه 'bank'
bank_emb_1 = embeddings_1[0, bank_idx_1]
bank_emb_2 = embeddings_2[0, bank_idx_2]
# محاسبه شباهت کسینوسی
cosine_sim = torch.nn.functional.cosine_similarity(bank_emb_1, bank_emb_2, dim=0)
print("Tokens 1:", tokens_1)
print("Tokens 2:", tokens_2)
print(f"Cosine similarity between both contextual embeddings of 'bank': {cosine_sim.item():.4f}")
۶. پیکربندیهای مدل BERT
گوگل دو پیکربندی اصلی از BERT را منتشر کرد:
| ابرپارامتر | BERT-Base | BERT-Large |
|---|---|---|
| تعداد لایهها ($L$) | 12 | 24 |
| ابعاد پنهان ($H$) | 768 | 1024 |
| هدهای توجه ($A$) | 12 | 16 |
| کل پارامترها | ۱۱۰ میلیون | ۳۴۰ میلیون |
نتیجهگیری
مدل BERT ثابت کرد که نمایشهای دوطرفه عمیق که روی متنهای بدون برچسب بزرگ آموزش دیدهاند، میتوانند ساختارهای نحوی و معنایی پیچیده را ثبت کنند. این مدل یک پارادایم جدید برای یادگیری انتقالی در پردازش زبان طبیعی ایجاد کرد و جریان کار پیشآموزش و سپس تنظیم دقیق را تثبیت کرد که تا پیش از ظهور مدلهای مبتنی بر رمزگشا (مانند GPT) بر هوش مصنوعی حاکم بود.