Comprendere BERT: Rappresentazioni dell'Encoder Bidirezionale dai Transformer
Nel 2018, i ricercatori di Google hanno pubblicato un articolo fondamentale intitolato “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding” (Devlin et al.). Questa ricerca ha cambiato radicalmente il campo del Natural Language Processing (NLP). Prima di BERT, i modelli elaboravano il testo sequenzialmente da sinistra a destra o da destra a sinistra. BERT ha introdotto un metodo per addestrare rappresentazioni linguistiche che guardano contemporaneamente al contesto da entrambe le direzioni.
Oggi, BERT e i suoi discendenti (come RoBERTa, DistilBERT e ALBERT) rimangono fondamentali per i motori di ricerca, l’analisi del sentiment, i sistemi di risposta alle domande e l’estrazione di informazioni. Questo articolo demistifica l’architettura BERT, come funziona e come viene addestrata.
1. Cos’è BERT?
BERT è l’acronimo di Bidirectional Encoder Representations from Transformers. Analizziamo questo nome:
- Bidirezionale (Bidirectional): A differenza dei modelli linguistici tradizionali che leggono il testo da sinistra a destra (come GPT) o da destra a sinistra, BERT legge l’intera sequenza di parole contemporaneamente. Ciò gli consente di apprendere il contesto di una parola in base a tutto ciò che la circonda (sia a sinistra che a destra).
- Rappresentazioni dell’Encoder (Encoder Representations): BERT utilizza la parte Encoder dell’architettura Transformer originale. Prende una sequenza di input e restituisce una rappresentazione vettoriale densa (embedding) per ogni token.
- Transformer (Transformers): Il motore sottostante è la rete di attenzione del Transformer, che consente la modellazione di dipendenze a lungo raggio e il calcolo parallelo.
Il potere della bidirezionalità
Nei modelli unidirezionali, un token può prestare attenzione solo ai token precedenti. Ad esempio, nella frase:
"Ha deciso di depositare il suo denaro in banca."
Se un modello unidirezionale elabora la parola “banca”, guarda solo le parole precedenti. Ma per comprendere appieno il contesto, è fondamentale guardare sia il contesto sinistro che quello destro. Mentre le LSTM bidirezionali hanno tentato questo approccio addestrando modelli separati da sinistra a destra e da destra a sinistra e concatenando gli output, BERT addestra un singolo modello profondamente bidirezionale in modo congiunto in tutti i livelli.
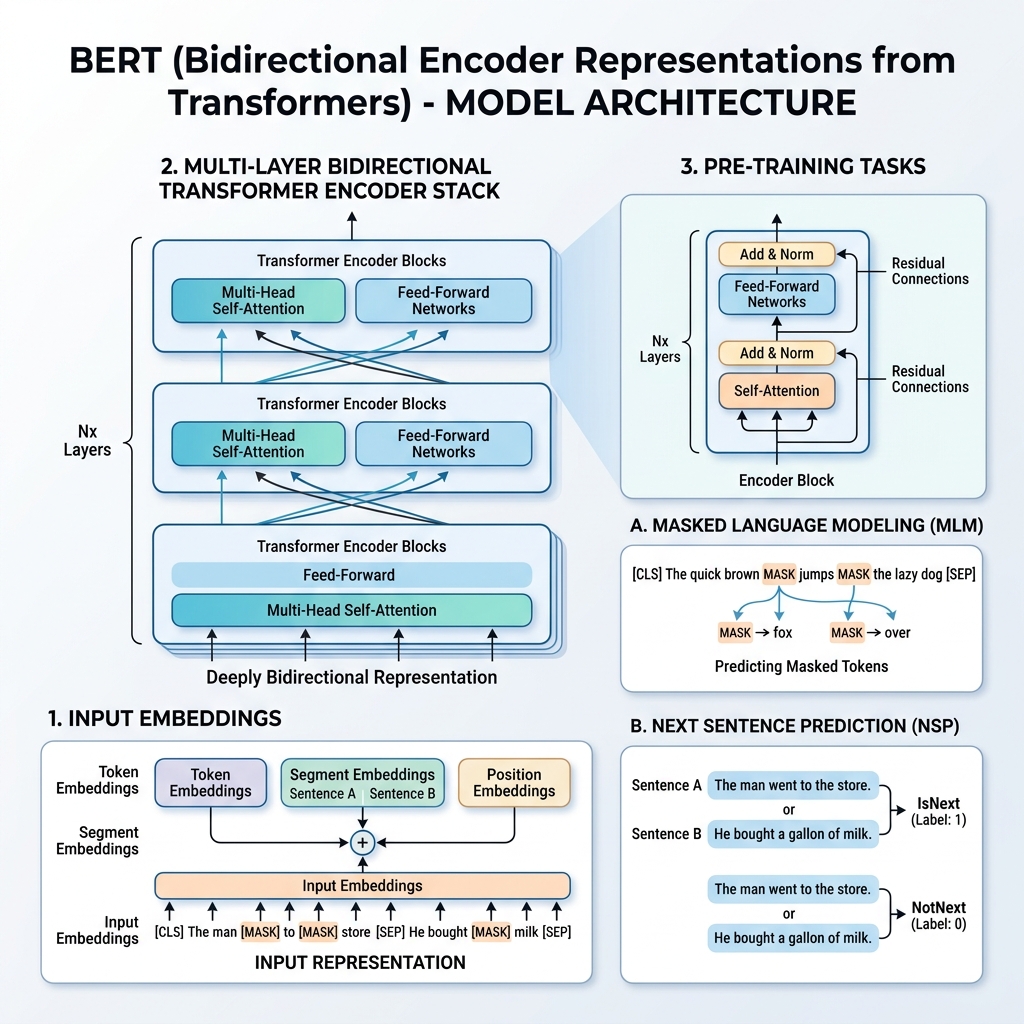
2. Rappresentazione dell’input di BERT
Per consentire l’addestramento su più attività a valle, la rappresentazione dell’input di BERT può rappresentare sia una singola frase che una coppia di frasi (ad esempio, <Domanda, Risposta>) in una singola sequenza di token.
Per ogni dato token, la sua rappresentazione di input viene costruita sommando tre embedding:
- Token Embeddings: Il testo viene tokenizzato utilizzando il vocabolario WordPiece (circa 30.000 token). Vengono aggiunti token speciali:
[CLS]: Inserito all’inizio di ogni sequenza. Il suo stato nascosto finale viene utilizzato per compiti di classificazione.[SEP]: Utilizzato per separare le frasi o alla fine di una sequenza.
- Segment Embeddings: Un embedding appreso che indica se un token appartiene alla frase A o alla frase B.
- Position Embeddings: Vettori posizionali appresi aggiunti per dare al modello consapevolezza della posizione del token nella sequenza (fino a 512 token).
$$\text{Rappresentazione dell’Input} = \text{Token Embeddings} + \text{Segment Embeddings} + \text{Position Embeddings}$$
3. Il processo di pre-addestramento
BERT viene pre-addestrato su un enorme corpus (Wikipedia e BooksCorpus) utilizzando contemporaneamente due attività non supervisionate: Masked Language Model (MLM) e Next Sentence Prediction (NSP).
Attività 1: Masked Language Model (MLM)
Nel modello linguistico standard, la previsione della parola successiva limita i modelli ad architetture da sinistra a destra per impedire alla parola target di “vedere” se stessa. Per addestrare una rappresentazione bidirezionale profonda, BERT maschera casualmente una percentuale di token di input e li predice.
In particolare:
- Il 15% dei token di input viene scelto casualmente.
- Di quei token scelti:
- L’80% viene sostituito con il token
[MASK]. - Il 10% viene sostituito con una parola casuale.
- Il 10% viene mantenuto invariato.
- L’80% viene sostituito con il token
Questa ricetta impedisce al modello di concentrarsi solo sul token [MASK] durante il fine-tuning (poiché [MASK] non appare mai durante il fine-tuning) e lo costringe a creare vettori di rappresentazione per ogni parola nel contesto.
Attività 2: Next Sentence Prediction (NSP)
Molti compiti a valle (come Question Answering e Natural Language Inference) dipendono dalla comprensione della relazione tra due frasi. Per addestrare il modello sulle relazioni tra frasi, BERT viene pre-addestrato su un compito di classificazione binaria:
Quando si scelgono le frasi $A$ e $B$ per il pre-addestramento:
- Il 50% delle volte, $B$ è l’effettiva frase successiva a $A$ (etichettata come
IsNext). - Il 50% delle volte, $B$ è una frase casuale del corpus (etichettata come
NotNext).
Il vettore nascosto finale del token [CLS] viene passato a un livello di classificazione per predire l’etichetta.
4. Fine-Tuning di BERT
Uno dei maggiori punti di forza di BERT è la sua flessibilità. Il pre-addestramento è costoso, ma il fine-tuning è incredibilmente economico e veloce. Sostituendo il livello di output finale, BERT può essere applicato a molti compiti a valle diversi:
- Classificazione di una singola frase: (es. analisi del sentiment). Utilizzare l’output del token
[CLS]. - Classificazione di coppie di frasi: (es. inferenza del linguaggio naturale). Utilizzare l’output del token
[CLS]. - Risposta alle domande: (es. SQuAD). Predire i token di inizio e fine dell’intervallo nel documento.
- Tagging di una singola frase: (es. Named Entity Recognition). Utilizzare la rappresentazione di output di ogni singolo token.
5. Implementazione Python/Hugging Face
Di seguito è riportato un semplice esempio in Python che mostra come caricare un modello BERT pre-addestrato ed estrarre embedding contestuali di parole utilizzando Hugging Face Transformers e PyTorch:
import torch
from transformers import BertTokenizer, BertModel
# 1. Inizializzare tokenizzatore e modello
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertModel.from_pretrained('bert-base-uncased')
# 2. Definire il testo contenente la parola "bank" in due contesti
text_1 = "He deposited money in the bank."
text_2 = "The river bank was muddy."
# 3. Tokenizzare gli input
inputs_1 = tokenizer(text_1, return_tensors="pt")
inputs_2 = tokenizer(text_2, return_tensors="pt")
# 4. Passaggio in avanti attraverso BERT
with torch.no_grad():
outputs_1 = model(**inputs_1)
outputs_2 = model(**inputs_2)
# 5. Estrarre gli embedding dei token
# shape di last_hidden_state: [batch_size, sequence_length, hidden_size]
embeddings_1 = outputs_1.last_hidden_state
embeddings_2 = outputs_2.last_hidden_state
# Ispezioniamo i token e i loro indici
tokens_1 = tokenizer.convert_ids_to_tokens(inputs_1["input_ids"][0])
tokens_2 = tokenizer.convert_ids_to_tokens(inputs_2["input_ids"][0])
# Trovare l'indice della parola 'bank'
bank_idx_1 = tokens_1.index("bank")
bank_idx_2 = tokens_2.index("bank")
# Ottenere i vettori di embedding per la parola 'bank'
bank_emb_1 = embeddings_1[0, bank_idx_1]
bank_emb_2 = embeddings_2[0, bank_idx_2]
# Calcolare la similarità del coseno
cosine_sim = torch.nn.functional.cosine_similarity(bank_emb_1, bank_emb_2, dim=0)
print("Tokens 1:", tokens_1)
print("Tokens 2:", tokens_2)
print(f"Similarità del coseno tra gli embedding contestuali di 'bank': {cosine_sim.item():.4f}")
6. Configurazioni del modello BERT
Google ha rilasciato due configurazioni principali di BERT:
| Iperparametro | BERT-Base | BERT-Large |
|---|---|---|
| Numero di Livelli ($L$) | 12 | 24 |
| Dimensione Nascosta ($H$) | 768 | 1024 |
| Teste di Attenzione ($A$) | 12 | 16 |
| Parametri Totali | 110 Milioni | 340 Milioni |
Conclusione
BERT ha dimostrato che le rappresentazioni bidirezionali profonde addestrate su grandi quantità di testo non etichettato possono catturare strutture sintattiche e semantiche complesse. Ha stabilito un nuovo paradigma per il transfer learning in NLP, definendo il flusso di lavoro di pre-addestramento e poi fine-tuning che ha dominato l’intelligenza artificiale fino all’ascesa dei modelli autoregressivi basati solo su decoder (come GPT).
Esplora altre prospettive tecnologiche sul Blog di Ghaznix →