BERT 이해하기: 트랜스포머 기반 양방향 인코더 표현
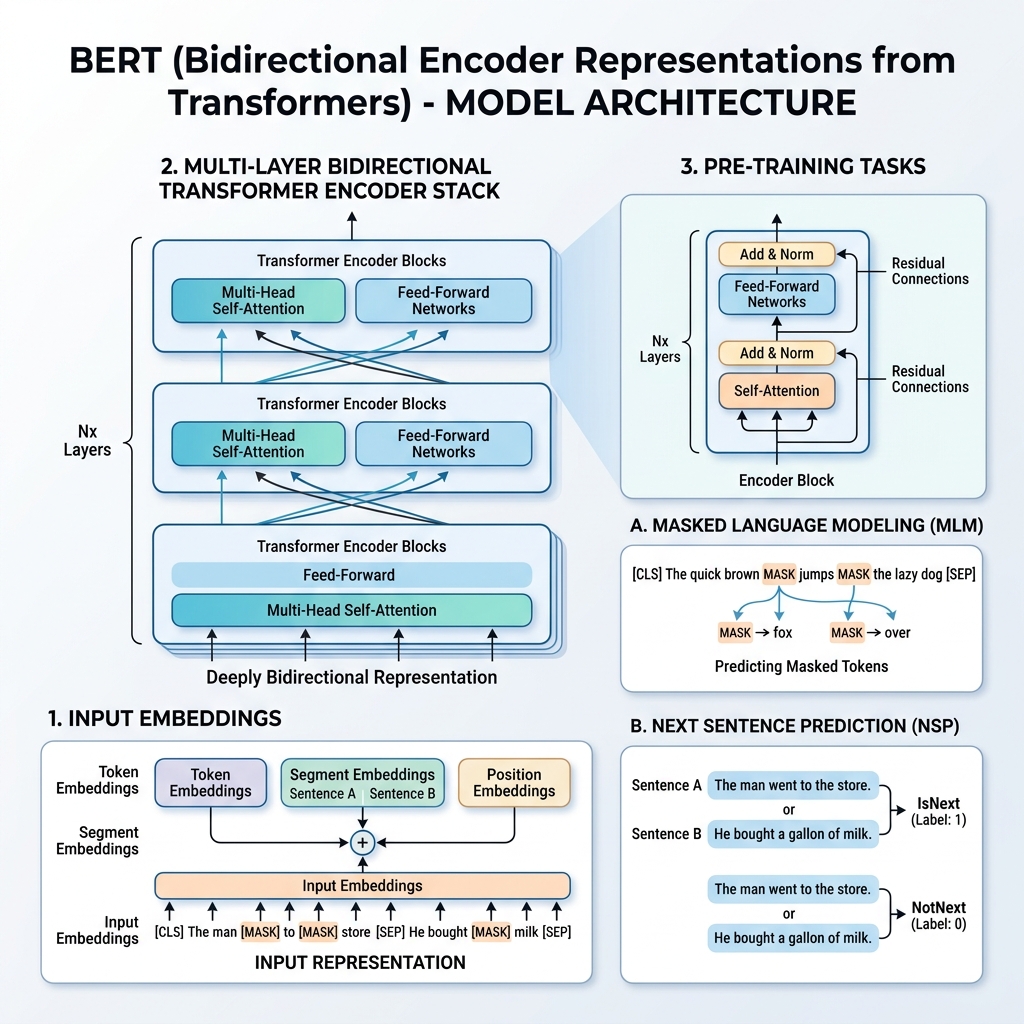
2018년, Google 연구원들은 “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding” (Devlin et al.)이라는 획기적인 논문을 발표했습니다. 이 연구는 자연어 처리(NLP) 분야를 근본적으로 변화시켰습니다. BERT 이전의 모델들은 텍스트를 왼쪽에서 오른쪽으로 또는 오른쪽에서 왼쪽으로 순차적으로 처리했습니다. BERT는 동시에 양방향의 문맥을 분석하여 언어 표현을 학습하는 새로운 방법을 도입했습니다.
오늘날 BERT와 그 파생 모델들(RoBERTa, DistilBERT, ALBERT 등)은 검색 엔진, 감성 분석, 질의응답 시스템, 정보 추출 분야에서 핵심적인 역할을 하고 있습니다. 이 글에서는 BERT 아키텍처와 그 작동 원리 및 학습 과정을 설명합니다.
1. BERT란 무엇인가?
BERT는 Bidirectional Encoder Representations from Transformers (트랜스포머 기반 양방향 인코더 표현)의 약자입니다. 이름을 구성 요소별로 살펴보겠습니다.
- 양방향성 (Bidirectional): 왼쪽에서 오른쪽으로(GPT처럼) 또는 오른쪽에서 왼쪽으로 텍스트를 읽는 기존 모델과 달리, BERT는 전체 단어 시퀀스를 한 번에 읽습니다. 이를 통해 특정 단어의 문맥을 그 주변 전체(왼쪽과 오른쪽 모두)를 기준으로 학습할 수 있습니다.
- 인코더 표현 (Encoder Representations): BERT는 오리지널 트랜스포머 아키텍처의 인코더(Encoder) 부분을 사용합니다. 입력 시퀀스를 받아 각 토큰에 대해 고차원 벡터 표현(임베딩)을 생성합니다.
- 트랜스포머 (Transformers): 내부 핵심 엔진은 트랜스포머 어텐션 네트워크로, 장기 의존성 모델링과 병렬 연산을 가능하게 만듭니다.
양방향성의 중요성
단방향 모델에서는 토큰이 이전의 토큰들만 참조할 수 있습니다. 예를 들어, 아래 문장에서:
"그는 은행(bank)에 돈을 예금하기로 결정했다."
단방향 모델이 "bank"를 처리할 때는 단어의 앞부분만 봅니다. 하지만 단어의 정확한 문맥을 파악하기 위해서는 왼쪽과 오른쪽의 문맥을 동시에 파악하는 것이 필수적입니다. 기존 양방향 LSTM은 왼쪽에서 오른쪽, 오른쪽에서 왼쪽의 별도 모델을 개별 학습한 뒤 결합하는 방식을 시도했지만, BERT는 모든 레이어에서 결합된 하나의 깊은 양방향 모델을 공동으로 학습합니다.
2. BERT의 입력 표현
여러 다운스트림 태스크에서 학습을 가능하게 하기 위해, BERT의 입력 표현은 단일 토큰 시퀀스 내에서 단일 문장뿐만 아니라 문장 쌍(예: <질문, 답변>)도 나타낼 수 있습니다.
입력 토큰 표현은 다음 세 가지 임베딩을 더하여 구성됩니다.
- 토큰 임베딩 (Token Embeddings): 텍스트는 WordPiece 어휘 사전(약 30,000개 토큰)을 사용하여 토큰화됩니다. 특별한 토큰들이 추가됩니다.
[CLS]: 모든 시퀀스의 시작 부분에 삽입됩니다. 이 토큰의 최종 은닉 상태는 분류 태스크에 사용됩니다.[SEP]: 두 문장을 구분하거나 시퀀스의 끝을 나타낼 때 사용됩니다.
- 세그먼트 임베딩 (Segment Embeddings): 특정 토큰이 문장 A와 문장 B 중 어디에 속하는지 나타내는 학습된 임베딩입니다.
- 위치 임베딩 (Position Embeddings): 시퀀스 내에서 토큰의 위치 정보를 모델에 알려주기 위해 추가되는 학습된 위치 벡터입니다 (최대 512 토큰).
$$\text{입력 표현} = \text{토큰 임베딩} + \text{세그먼트 임베딩} + \text{위치 임베딩}$$
3. 사전 학습 과정 (Pre-training)
BERT는 대규모 말뭉치(Wikipedia 및 BooksCorpus)를 사용하여 **마스크드 언어 모델(MLM)**과 **다음 문장 예측(NSP)**이라는 두 가지 비지도 학습 태스크를 동시에 처리하며 사전 학습됩니다.
태스크 1: 마스크드 언어 모델 (MLM)
일반적인 언어 모델링에서는 다음 단어를 예측할 때 타겟 단어가 자기 자신을 보는 것을 막기 위해 모델을 단방향 아키텍처로 제한합니다. 깊은 양방향 표현을 학습하기 위해 BERT는 입력 토큰의 일부를 무작위로 마스킹하고 이를 예측합니다.
구체적으로:
- 입력 토큰 중 **15%**를 무작위로 선택합니다.
- 선택된 토큰 중:
- **80%**는
[MASK]토큰으로 대체됩니다. - **10%**는 무작위로 선택된 다른 단어로 대체됩니다.
- **10%**는 원래 단어 그대로 유지됩니다.
- **80%**는
이 방식은 미세 조정(fine-tuning) 과정에서 모델이 [MASK] 토큰에만 의존하지 않도록 방지하고(미세 조정 시기에는 [MASK]가 나타나지 않으므로), 문맥상 모든 단어에 대한 완성도 높은 표현 벡터를 구축하도록 강제합니다.
태스크 2: 다음 문장 예측 (NSP)
질의응답(QA)이나 자연어 추론(NLI)과 같은 많은 다운스트림 태스크는 두 문장 간의 관계를 이해하는 것이 매우 중요합니다. 문장 간의 관계를 학습시키기 위해 BERT는 이진 분류 태스크를 사용하여 사전 학습됩니다.
사전 학습을 위한 문장 $A$와 $B$를 선택할 때:
- **50%**의 확률로 $B$는 $A$ 바로 다음에 오는 실제 문장입니다 (
IsNext로 라벨링됨). - **50%**의 확률로 $B$는 말뭉치에서 무작위로 추출된 무관한 문장입니다 (
NotNext로 라벨링됨).
[CLS] 토큰의 최종 은닉 벡터는 분류 레이어로 전달되어 라벨을 예측하게 됩니다.
4. BERT 미세 조정 (Fine-Tuning)
BERT의 가장 큰 강점 중 하나는 유연성입니다. 사전 학습은 엄청난 자원이 소모되지만, 미세 조정은 아주 빠르고 적은 자원으로 가능합니다. 출력 레이어만 변경하여 다양한 태스크에 적용할 수 있습니다.
- 단일 문장 분류: (예: 감성 분석).
[CLS]토큰 출력을 사용합니다. - 문장 쌍 분류: (예: 자연어 추론).
[CLS]토큰 출력을 사용합니다. - 질의응답: (예: SQuAD). 본문 문서 내에서 정답 단어의 시작과 끝 토큰 위치를 예측합니다.
- 단일 문장 토큰 태깅: (예: 개체명 인식 - NER). 개별 토큰의 출력 표현을 사용합니다.
5. Python / Hugging Face 구현 예제
아래는 Hugging Face Transformers와 PyTorch를 사용하여 사전 학습된 BERT 모델을 로드하고 문맥에 따른 단어 임베딩을 추출하는 간단한 Python 예제입니다.
import torch
from transformers import BertTokenizer, BertModel
# 1. 토크나이저 및 모델 초기화
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertModel.from_pretrained('bert-base-uncased')
# 2. "bank" 단어가 다른 문맥으로 사용된 두 문장 정의
text_1 = "He deposited money in the bank."
text_2 = "The river bank was muddy."
# 3. 입력값 토큰화
inputs_1 = tokenizer(text_1, return_tensors="pt")
inputs_2 = tokenizer(text_2, return_tensors="pt")
# 4. BERT 연산 수행 (기억장치 절약)
with torch.no_grad():
outputs_1 = model(**inputs_1)
outputs_2 = model(**inputs_2)
# 5. 토큰 임베딩 추출
# last_hidden_state 크기: [batch_size, sequence_length, hidden_size]
embeddings_1 = outputs_1.last_hidden_state
embeddings_2 = outputs_2.last_hidden_state
# 토큰과 해당 인덱스 확인
tokens_1 = tokenizer.convert_ids_to_tokens(inputs_1["input_ids"][0])
tokens_2 = tokenizer.convert_ids_to_tokens(inputs_2["input_ids"][0])
# 두 문장에서 'bank' 단어의 인덱스 찾기
bank_idx_1 = tokens_1.index("bank")
bank_idx_2 = tokens_2.index("bank")
# 'bank' 단어의 임베딩 벡터 추출
bank_emb_1 = embeddings_1[0, bank_idx_1]
bank_emb_2 = embeddings_2[0, bank_idx_2]
# 코사인 유사도 연산
cosine_sim = torch.nn.functional.cosine_similarity(bank_emb_1, bank_emb_2, dim=0)
print("Tokens 1:", tokens_1)
print("Tokens 2:", tokens_2)
print(f"두 문맥 속 'bank' 임베딩 사이의 코사인 유사도: {cosine_sim.item():.4f}")
6. BERT 모델 설정
Google은 두 가지 메인 크기의 BERT 모델을 릴리스했습니다.
| 하이퍼파라미터 | BERT-Base | BERT-Large |
|---|---|---|
| 레이어 개수 ($L$) | 12 | 24 |
| 은닉 차원 크기 ($H$) | 768 | 1024 |
| 어텐션 헤드 개수 ($A$) | 12 | 16 |
| 총 파라미터 개수 | 1억 1천만 | 3억 4천만 |
결론
BERT는 레이블이 없는 대규모 텍스트 데이터에서 양방향으로 공동 학습을 진행할 때 얼마나 복잡한 문법적, 의미적 구조를 잘 인지할 수 있는지 입ญ해냈습니다. 이는 NLP 진영에서 전이 학습(Transfer Learning)의 새로운 패러다임을 확립했으며, GPT 같은 디코더 기반 자동회귀 모델이 대중화되기 전까지 AI 연구 흐름을 이끌었습니다.