BERT को समझना: ट्रांसफॉर्मर से द्विदिश एन코डर प्रतिनिधित्व (Bidirectional Encoder Representations)
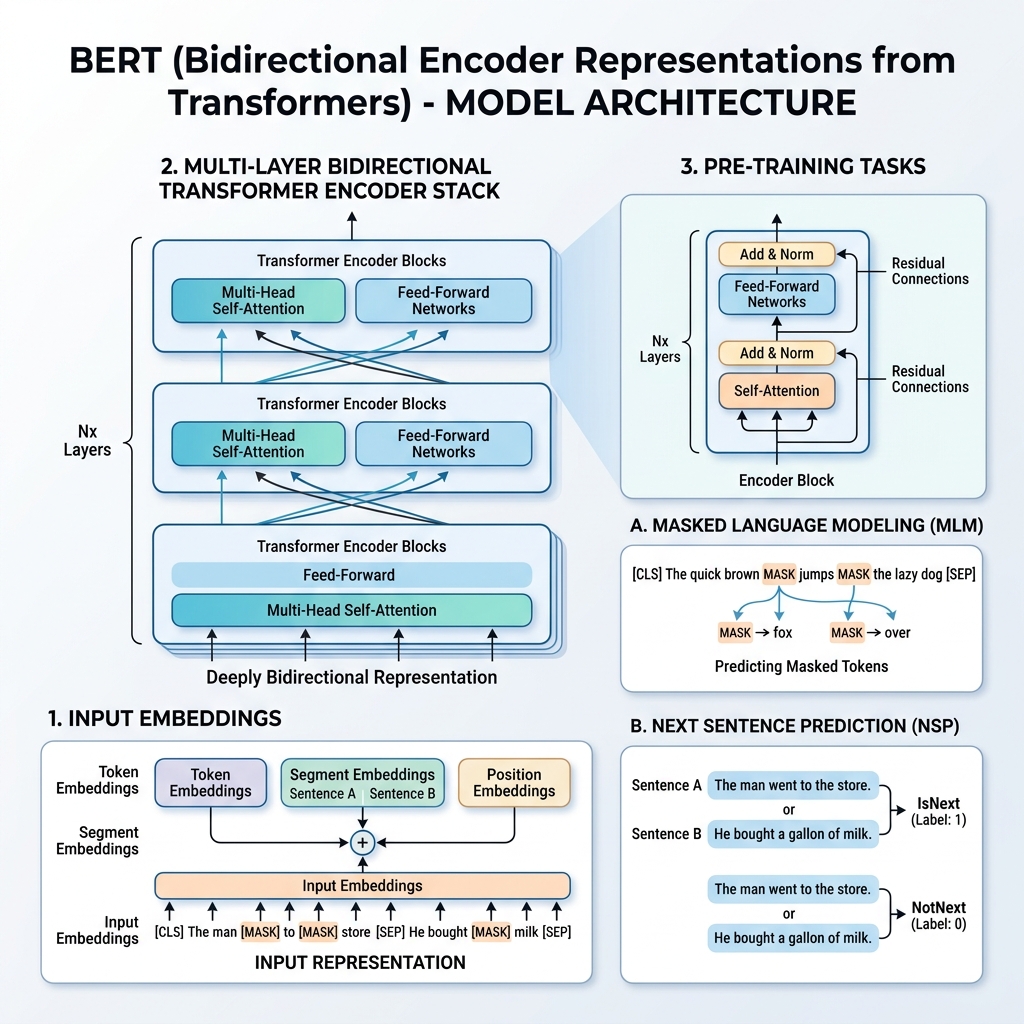
2018 में, Google के शोधकर्ताओं ने “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding” (Devlin et al.) नामक एक अत्यंत महत्वपूर्ण शोध पत्र प्रकाशित किया। इस शोध ने नेचुरल लैंग्वेज प्रोसेसिंग (NLP) के क्षेत्र को पूरी तरह से बदल दिया। BERT से पहले, मॉडल आमतौर पर पाठ को बाएं-से-दाएं या दाएं-से-बाएं क्रमिक रूप से संसाधित करते थे। BERT ने भाषा प्रतिनिधित्व को प्रशिक्षित करने की एक ऐसी विधि पेश की जो एक ही समय में दोनों दिशाओं से संदर्भ को देखती है।
आज, BERT और इसके विभिन्न रूप (जैसे RoBERTa, DistilBERT, और ALBERT) सर्च इंजन, भावना विश्लेषण, प्रश्न-उत्तर प्रणाली और जानकारी निकालने के लिए बुनियादी बने हुए हैं। यह लेख BERT आर्किटेक्चर, इसके काम करने के तरीके और इसे प्रशिक्षित करने की प्रक्रिया को विस्तार से समझाता है।
1. BERT क्या है?
BERT का पूर्ण रूप Bidirectional Encoder Representations from Transformers है। आइए इस नाम को विस्तार से समझें:
- द्विदिश (Bidirectional): पारंपरिक भाषा मॉडलों के विपरीत जो पाठ को बाएं-से-दाएं (जैसे GPT) या दाएं-से-बाएं पढ़ते हैं, BERT शब्दों के पूरे अनुक्रम को एक साथ पढ़ता है। यह इसे किसी शब्द के संदर्भ को उसके आसपास के पूरे वातावरण (बाएं और दाएं दोनों) के आधार पर सीखने की अनुमति देता है।
- एनकोडर प्रतिनिधित्व (Encoder Representations): BERT मूल ट्रांसफॉर्मर आर्किटेक्चर के Encoder (एनकोडर) भाग का उपयोग करता है। यह एक इनपुट अनुक्रम लेता है और प्रत्येक टोकन के लिए एक सघन वेक्टर प्रतिनिधित्व (embedding) प्रदान करता है।
- ट्रांसफॉर्मर (Transformers): इसका अंतर्निहित इंजन ट्रांसफॉर्मर अटेंशन (ध्यान) नेटवर्क है, जो लंबी दूरी की निर्भरताओं के मॉडलिंग और समानांतर गणना को सक्षम बनाता है।
द्विदिशता की शक्ति
एकदिशीय मॉडलों में, कोई टोकन केवल पिछले टोकन पर ही ध्यान दे सकता है। उदाहरण के लिए, इस वाक्य में:
"उसने बैंक में पैसे जमा करने का फैसला किया।"
यदि कोई एकदिशीय मॉडल "बैंक" शब्द को संसाधित करता है, तो वह केवल उससे पहले आने वाले शब्दों को देखता है। लेकिन संदर्भ को पूरी तरह से समझने के लिए, बाएं और दाएं दोनों संदर्भों को देखना महत्वपूर्ण है। जबकि द्विदिश LSTMs ने बाएं-से-दाएं और दाएं-से-बाएं अलग-अलग मॉडलों को प्रशिक्षित करके और उनके आउटपुट को जोड़कर ऐसा करने का प्रयास किया, BERT सभी परतों में संयुक्त रूप से एक एकल, गहरे द्विदिश मॉडल को प्रशिक्षित करता है।
2. BERT का इनपुट प्रतिनिधित्व
विभिन्न कार्यों पर प्रशिक्षण को सक्षम करने के लिए, BERT का इनपुट प्रतिनिधित्व एक ही टोकन अनुक्रम में एकल वाक्य और वाक्य जोड़ी (जैसे <प्रश्न, उत्तर>) दोनों को प्रस्तुत कर सकता है।
किसी भी टोकन के लिए, इसका इनपुट प्रतिनिधित्व तीन प्रकार की एम्बेडिंग को जोड़कर बनाया जाता है:
- टोकन एम्बेडिंग (Token Embeddings): पाठ को WordPiece शब्दावली (लगभग 30,000 टोकन) का उपयोग करके टोकन में विभाजित किया जाता है। विशेष टोकन जोड़े जाते हैं:
[CLS]: प्रत्येक अनुक्रम की शुरुआत में डाला जाता है। इसकी अंतिम छिपी हुई स्थिति का उपयोग वर्गीकरण कार्यों के लिए किया जाता है।[SEP]: वाक्यों को अलग करने के लिए या अनुक्रम के अंत में उपयोग किया जाता है।
- खंड एम्बेडिंग (Segment Embeddings): एक सीखी गई एम्बेडिंग जो यह दर्शाती है कि कोई टोकन वाक्य A का हिस्सा है या वाक्य B का।
- स्थिति एम्बेडिंग (Position Embeddings): सीखी गई स्थिति वेक्टर जो मॉडल को अनुक्रम में टोकन की स्थिति से अवगत कराने के लिए जोड़ी जाती है (512 टोकन तक)।
$$\text{इनपुट प्रतिनिधित्व} = \text{टोकन एम्बेडिंग} + \text{खंड एम्बेडिंग} + \text{स्थिति एम्बेडिंग}$$
3. प्री-ट्रेनिंग प्रक्रिया
BERT को एक विशाल कॉर्पस (Wikipedia और BooksCorpus) पर एक साथ दो अनुपयोगी कार्यों का उपयोग करके पहले से प्रशिक्षित किया जाता है: मास्क्ड लैंग्वेज मॉडल (MLM) और नेक्स्ट सेंटेंस प्रेडिक्शन (NSP)।
कार्य 1: मास्क्ड लैंग्वेज मॉडल (MLM)
मानक भाषा मॉडलिंग में, अगले शब्द की भविष्यवाणी करना मॉडलों को बाएं-से-दाएं आर्किटेक्चर तक सीमित करता है ताकि लक्षित शब्द खुद को “देखने” से बच सके। एक गहरा द्विदिश प्रतिनिधित्व प्रशिक्षित करने के लिए, BERT इनपुट टोकन के एक निश्चित प्रतिशत को यादृच्छिक रूप से मास्क (छिपा) देता है और उनकी भविष्यवाणी करता है।
विशेष रूप से:
- इनपुट टोकन में से यादृच्छिक रूप से 15% का चयन किया जाता है।
- चयनित टोकन में से:
- 80% को
[MASK]टोकन से बदल दिया जाता है। - 10% को किसी यादृच्छिक शब्द से बदल दिया जाता है।
- 10% को बिना किसी बदलाव के रखा जाता है।
- 80% को
यह विधि मॉडल को फाइन-ट्यूनिंग के दौरान केवल [MASK] टोकन पर ध्यान केंद्रित करने से रोकती है (क्योंकि फाइन-ट्यूनिंग के दौरान [MASK] कभी नहीं दिखाई देता) और इसे संदर्भ में प्रत्येक शब्द के लिए प्रतिनिधित्व वेक्टर बनाने के लिए मजबूर करती है।
कार्य 2: नेक्स्ट सेंटेंस प्रेडिक्शन (NSP)
कई कार्य (जैसे प्रश्न उत्तर और प्राकृतिक भाषा अनुमान) दो वाक्यों के बीच संबंध को समझने पर निर्भर करते हैं। वाक्यों के संबंधों पर मॉडल को प्रशिक्षित करने के लिए, BERT को बाइनरी वर्गीकरण कार्य पर पहले से प्रशिक्षित किया जाता है:
प्री-ट्रेनिंग के लिए वाक्य $A$ और $B$ चुनते समय:
- 50% बार, $B$ वास्तव में अगला वाक्य होता है जो $A$ के बाद आता है (जिसे
IsNextके रूप में लेबल किया जाता है)। - 50% बार, $B$ कॉर्पस से एक यादृच्छिक वाक्य होता है (जिसे
NotNextके रूप में लेबल किया जाता है)।
लेबल की भविष्यवाणी करने के लिए [CLS] टोकन का अंतिम छिपा हुआ वेक्टर वर्गीकरण परत को भेजा जाता है।
4. BERT फाइन-ट्यूनिंग (Fine-Tuning)
BERT की सबसे बड़ी शक्तियों में से एक इसका लचीलापन है। प्री-ट्रेनिंग बहुत महंगी है, लेकिन फाइन-ट्यूनिंग बेहद सस्ती और तेज़ है। अंतिम आउटपुट परत को बदलकर, BERT को कई अलग-अलग कार्यों पर लागू किया जा सकता है:
- एकल वाक्य वर्गीकरण: (जैसे भावना विश्लेषण)।
[CLS]टोकन आउटपुट का उपयोग करें। - वाक्य जोड़ी वर्गीकरण: (जैसे प्राकृतिक भाषा अनुमान)।
[CLS]टोकन आउटपुट का उपयोग करें। - प्रश्न उत्तर: (जैसे SQuAD)। दस्तावेज़ में उत्तर के आरंभ और अंत के टोकन की भविष्यवाणी करें।
- एकल वाक्य टैगिंग: (जैसे नामित इकाई पहचान - NER)। प्रत्येक व्यक्तिगत टोकन के आउटपुट प्रतिनिधित्व का उपयोग करें।
5. Python/Hugging Face कार्यान्वयन
नीचे एक सरल पायथन कोड दिया गया है जो दिखाता है कि पहले से प्रशिक्षित BERT मॉडल को कैसे लोड किया जाए और Hugging Face Transformers और PyTorch का उपयोग करके संदर्भ-संवेदी शब्दों के एम्बेडिंग को कैसे निकाला जाए:
import torch
from transformers import BertTokenizer, BertModel
# 1. टोकनाइज़र और मॉडल को इनिशियलाइज़ करें
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertModel.from_pretrained('bert-base-uncased')
# 2. पाठ को परिभाषित करें जिसमें "bank" शब्द दो अलग संदर्भों में हो
text_1 = "He deposited money in the bank."
text_2 = "The river bank was muddy."
# 3. इनपुट को टोकनाइज़ करें
inputs_1 = tokenizer(text_1, return_tensors="pt")
inputs_2 = tokenizer(text_2, return_tensors="pt")
# 4. BERT के माध्यम से फॉरवर्ड पास चलाएं
with torch.no_grad():
outputs_1 = model(**inputs_1)
outputs_2 = model(**inputs_2)
# 5. टोकन एम्बेडिंग निकालें
# last_hidden_state का आयाम: [batch_size, sequence_length, hidden_size]
embeddings_1 = outputs_1.last_hidden_state
embeddings_2 = outputs_2.last_hidden_state
# टोकन और उनके इंडेक्स देखें
tokens_1 = tokenizer.convert_ids_to_tokens(inputs_1["input_ids"][0])
tokens_2 = tokenizer.convert_ids_to_tokens(inputs_2["input_ids"][0])
# 'bank' शब्द का इंडेक्स खोजें
bank_idx_1 = tokens_1.index("bank")
bank_idx_2 = tokens_2.index("bank")
# 'bank' के लिए एम्बेडिंग वेक्टर प्राप्त करें
bank_emb_1 = embeddings_1[0, bank_idx_1]
bank_emb_2 = embeddings_2[0, bank_idx_2]
# कोसाइन समानता की गणना करें
cosine_sim = torch.nn.functional.cosine_similarity(bank_emb_1, bank_emb_2, dim=0)
print("Tokens 1:", tokens_1)
print("Tokens 2:", tokens_2)
print(f"'bank' के दोनों संदर्भों की एम्बेडिंग के बीच कोसाइन समानता: {cosine_sim.item():.4f}")
6. BERT मॉडल विन्यास
Google ने BERT के दो मुख्य विन्यास जारी किए:
| हाइपरपैरामीटर | BERT-Base | BERT-Large |
|---|---|---|
| परतों की संख्या ($L$) | 12 | 24 |
| छिपा हुआ आकार ($H$) | 768 | 1024 |
| अटेंशन हेड्स ($A$) | 12 | 16 |
| कुल पैरामीटर | 110 मिलियन | 340 मिलियन |
निष्कर्ष
BERT ने यह साबित कर दिया कि बड़े बिना लेबल वाले पाठ पर प्रशिक्षित गहरे द्विदिश प्रतिनिधित्व जटिल वाक्य-रचनात्मक और अर्थ-संबंधी संरचनाओं को पकड़ सकते हैं। इसने NLP में ट्रांसफर लर्निंग के लिए एक नया प्रतिमान स्थापित किया, जिसने प्री-ट्रेनिंग और फिर फाइन-ट्यूनिंग वर्कफ़्लो को स्थापित किया जो आज के एआई विकास की नींव है।