BERT verstehen: Bidirektionale Encoder-Repräsentationen aus Transformern
Im Jahr 2018 veröffentlichten Google-Forscher ein bahnbrechendes Paper mit dem Titel „BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding“ (Devlin et al.). Diese Arbeit hat das Feld der natürlichen Sprachverarbeitung (NLP) grundlegend verändert. Vor BERT verarbeiteten Modelle Text sequentiell von links nach rechts oder von rechts nach links. BERT führte eine Methode ein, um Sprachdarstellungen zu trainieren, die den Kontext aus beiden Richtungen gleichzeitig betrachten.
Heute sind BERT und seine Nachfolger (wie RoBERTa, DistilBERT und ALBERT) nach wie vor grundlegend für Suchmaschinen, Sentimentanalysen, Frage-Antwort-Systeme und die Informationsextraktion. Dieser Artikel entmystifiziert die BERT-Architektur, ihre Funktionsweise und wie sie trainiert wird.
1. Was ist BERT?
BERT steht für Bidirectional Encoder Representations from Transformers. Lassen Sie uns diesen Namen aufschlüsseln:
- Bidirektional (Bidirectional): Im Gegensatz zu herkömmlichen Sprachmodellen, die Text von links nach rechts (wie GPT) oder von rechts nach links lesen, liest BERT die gesamte Wortsequenz auf einmal. Dadurch kann es den Kontext eines Wortes basierend auf seiner gesamten Umgebung (sowohl links als auch rechts) lernen.
- Encoder-Repräsentationen (Encoder Representations): BERT verwendet den Encoder-Teil der ursprünglichen Transformer-Architektur. Er nimmt eine Eingabesequenz und gibt eine dichte Vektorrepräsentation (Embedding) für jeden Token aus.
- Transformer (Transformers): Die zugrunde liegende Engine ist das Transformer-Attention-Netzwerk, das die Modellierung von weitreichenden Abhängigkeiten und parallelen Berechnungen ermöglicht.
Die Stärke der Bidirektionalität
In unidirektionalen Modellen kann sich ein Token nur auf vorherige Token beziehen. Zum Beispiel im Satz:
„Er beschloss, sein Geld auf der Bank einzuzahlen.“
Wenn ein unidirektionales Modell „Bank“ verarbeitet, schaut es sich nur die Wörter davor an. Um den Kontext jedoch vollständig zu verstehen, ist die Betrachtung des linken und rechten Kontextes entscheidend. Während bidirektionale LSTMs dies versuchten, indem sie separate Links-nach-rechts- und Rechts-nach-links-Modelle trainierten und deren Ausgaben verketteten, trainiert BERT ein einzelnes, tief bidirektionales Modell gemeinsam über alle Schichten hinweg.
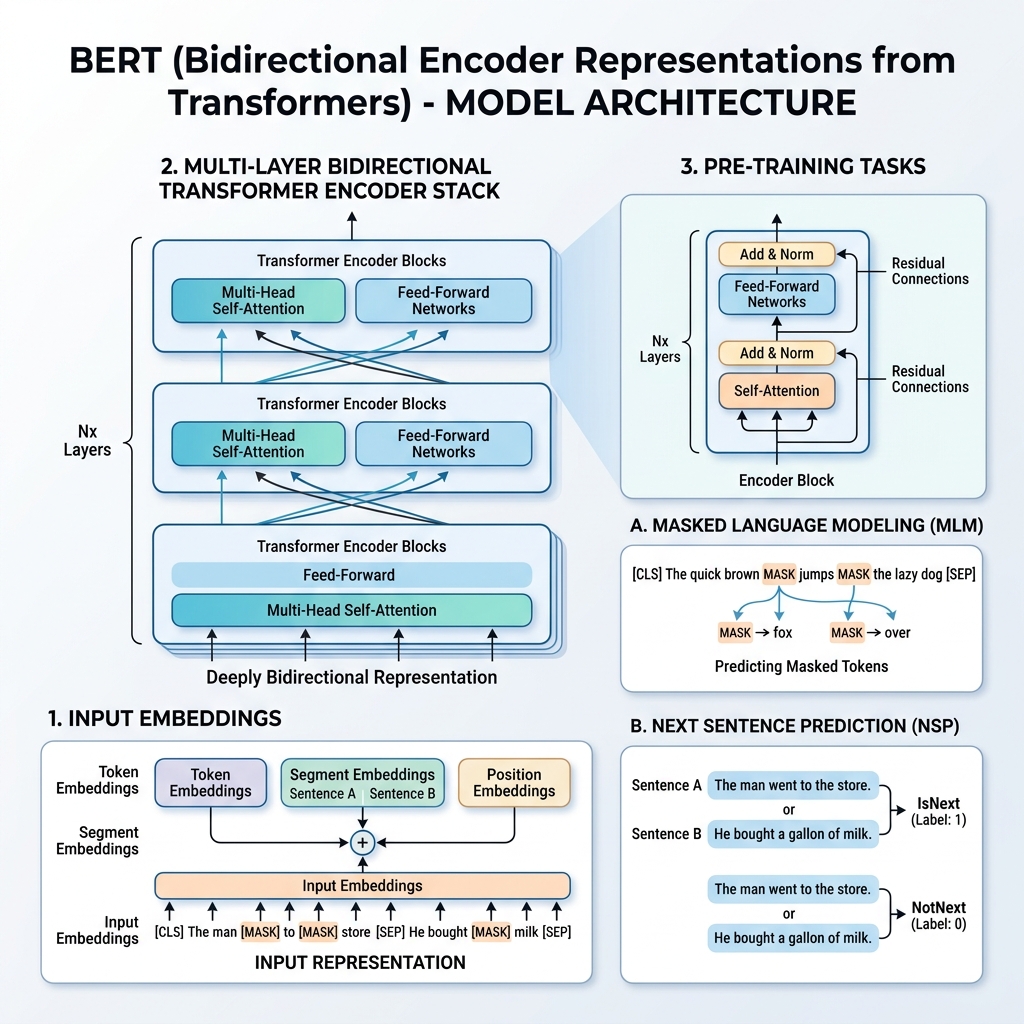
2. BERTs Eingabedarstellung
Um das Training für verschiedene nachgelagerte Aufgaben zu ermöglichen, kann die Eingabedarstellung von BERT sowohl einen einzelnen Satz als auch ein Satzpaar (z. B. <Frage, Antwort>) in einer einzigen Token-Sequenz darstellen.
Für jeden gegebenen Token wird seine Eingabedarstellung durch Addieren von drei Einbettungen (Embeddings) konstruiert:
- Token-Einbettungen (Token Embeddings): Der Text wird mit dem WordPiece-Vokabular (ca. 30.000 Token) tokenisiert. Spezielle Token werden hinzugefügt:
[CLS]: Wird am Anfang jeder Sequenz eingefügt. Sein finaler verborgener Zustand wird für Klassifizierungsaufgaben verwendet.[SEP]: Wird verwendet, um Sätze zu trennen oder am Ende einer Sequenz.
- Segment-Einbettungen (Segment Embeddings): Eine gelernte Einbettung, die angibt, ob ein Token zu Satz A oder Satz B gehört.
- Positions-Einbettungen (Position Embeddings): Gelernte Positionsvektoren, die hinzugefügt werden, um dem Modell die Position des Tokens in der Sequenz bewusst zu machen (bis zu 512 Token).
$$\text{Eingabedarstellung} = \text{Token-Einbettungen} + \text{Segment-Einbettungen} + \text{Positions-Einbettungen}$$
3. Der Pre-training-Prozess
BERT wird auf einem riesigen Korpus (Wikipedia und BooksCorpus) mithilfe von zwei unüberwachten Aufgaben gleichzeitig vorab trainiert: Masked Language Model (MLM) und Next Sentence Prediction (NSP).
Aufgabe 1: Masked Language Model (MLM)
Bei der Standard-Sprachmodellierung schränkt die Vorhersage des nächsten Wortes Modelle auf Links-nach-rechts-Architekturen ein, um zu verhindern, dass das Zielwort sich selbst „sieht“. Um eine tiefe bidirektionale Darstellung zu trainieren, maskiert BERT zufällig einen Prozentsatz der Eingabetoken und sagt diese voraus.
Konkret:
- 15 % der Eingabetoken werden zufällig ausgewählt.
- Von diesen ausgewählten Token:
- 80 % werden durch das
[MASK]-Token ersetzt. - 10 % werden durch ein zufälliges Wort ersetzt.
- 10 % bleiben unverändert.
- 80 % werden durch das
Dieses Verfahren verhindert, dass sich das Modell während des Fine-Tunings nur auf das [MASK]-Token konzentriert (da [MASK] beim Fine-Tuning nie vorkommt), und zwingt es, Repräsentationsvektoren für jedes Wort im Kontext aufzubauen.
Aufgabe 2: Next Sentence Prediction (NSP)
Viele nachgelagerte Aufgaben (wie Frage-Antwort-Systeme und Natural Language Inference) hängen vom Verständnis der Beziehung zwischen zwei Sätzen ab. Um das Modell auf Satzbeziehungen zu trainieren, wird BERT auf eine binäre Klassifizierungsaufgabe vorab trainiert:
Bei der Auswahl der Sätze $A$ und $B$ für das Pre-training gilt:
- In 50 % der Fälle ist $B$ der tatsächlich auf $A$ folgende Satz (gekennzeichnet als
IsNext). - In 50 % der Fälle ist $B$ ein zufälliger Satz aus dem Korpus (gekennzeichnet als
NotNext).
Der finale verborgene Vektor des [CLS]-Tokens wird an eine Klassifizierungsschicht übergeben, um das Label vorherzusagen.
4. Fine-Tuning von BERT
Eine der größten Stärken von BERT ist seine Flexibilität. Das Pre-training ist teuer, aber das Fine-Tuning ist unglaublich günstig und schnell. Durch Austausch der letzten Ausgabeschicht kann BERT auf viele verschiedene Aufgaben angewendet werden:
- Klassifizierung einzelner Sätze: (z. B. Sentimentanalyse). Verwendung des
[CLS]-Token-Ausgangs. - Klassifizierung von Satzpaaren: (z. B. logische Folgerung). Verwendung des
[CLS]-Token-Ausgangs. - Frage-Antwort-Systeme: (z. B. SQuAD). Vorhersage der Start- und End-Token-Positionen im Dokument.
- Tagging einzelner Sätze: (z. B. Named Entity Recognition). Verwendung der Ausgaberepräsentation jedes einzelnen Tokens.
5. Python/Hugging Face-Implementierung
Hier ist ein einfaches Python-Beispiel, das zeigt, wie man ein vortrainiertes BERT-Modell lädt und kontextuelle Wort-Embeddings mit Hugging Face Transformers und PyTorch extrahiert:
import torch
from transformers import BertTokenizer, BertModel
# 1. Tokenizer und Modell initialisieren
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertModel.from_pretrained('bert-base-uncased')
# 2. Text mit dem Wort "bank" in zwei Kontexten definieren
text_1 = "He deposited money in the bank."
text_2 = "The river bank was muddy."
# 3. Eingaben tokenisieren
inputs_1 = tokenizer(text_1, return_tensors="pt")
inputs_2 = tokenizer(text_2, return_tensors="pt")
# 4. Vorwärtspass durch BERT
with torch.no_grad():
outputs_1 = model(**inputs_1)
outputs_2 = model(**inputs_2)
# 5. Token-Embeddings extrahieren
# last_hidden_state Shape: [batch_size, sequence_length, hidden_size]
embeddings_1 = outputs_1.last_hidden_state
embeddings_2 = outputs_2.last_hidden_state
# Token und ihre Indizes untersuchen
tokens_1 = tokenizer.convert_ids_to_tokens(inputs_1["input_ids"][0])
tokens_2 = tokenizer.convert_ids_to_tokens(inputs_2["input_ids"][0])
# Index des Wortes 'bank' finden
bank_idx_1 = tokens_1.index("bank")
bank_idx_2 = tokens_2.index("bank")
# Einbettungsvektoren für das Wort 'bank' abrufen
bank_emb_1 = embeddings_1[0, bank_idx_1]
bank_emb_2 = embeddings_2[0, bank_idx_2]
# Kosinus-Ähnlichkeit berechnen
cosine_sim = torch.nn.functional.cosine_similarity(bank_emb_1, bank_emb_2, dim=0)
print("Tokens 1:", tokens_1)
print("Tokens 2:", tokens_2)
print(f"Kosinus-Ähnlichkeit zwischen den kontextuellen Einbettungen von 'bank': {cosine_sim.item():.4f}")
6. BERT-Modellkonfigurationen
Google hat zwei Hauptkonfigurationen von BERT veröffentlicht:
| Hyperparameter | BERT-Base | BERT-Large |
|---|---|---|
| Anzahl der Schichten ($L$) | 12 | 24 |
| Verborgene Dimension ($H$) | 768 | 1024 |
| Attention-Heads ($A$) | 12 | 16 |
| Parameter insgesamt | 110 Millionen | 340 Millionen |
Fazit
BERT hat bewiesen, dass tiefe bidirektionale Repräsentationen, die auf großen unbeschrifteten Texten trainiert wurden, komplexe syntaktische und semantische Strukturen erfassen können. Es setzte ein neues Paradigma für Transfer-Learning im NLP und etablierte den Pre-train-then-Fine-tune-Workflow, der die KI bis zum Aufkommen autoregressiver Decoder-only-Modelle (wie GPT) dominierte.
Entdecken Sie weitere technische Einblicke im Ghaznix-Blog →