Comprensión de BERT: Representaciones de Encoder Bidireccionales a partir de Transformers
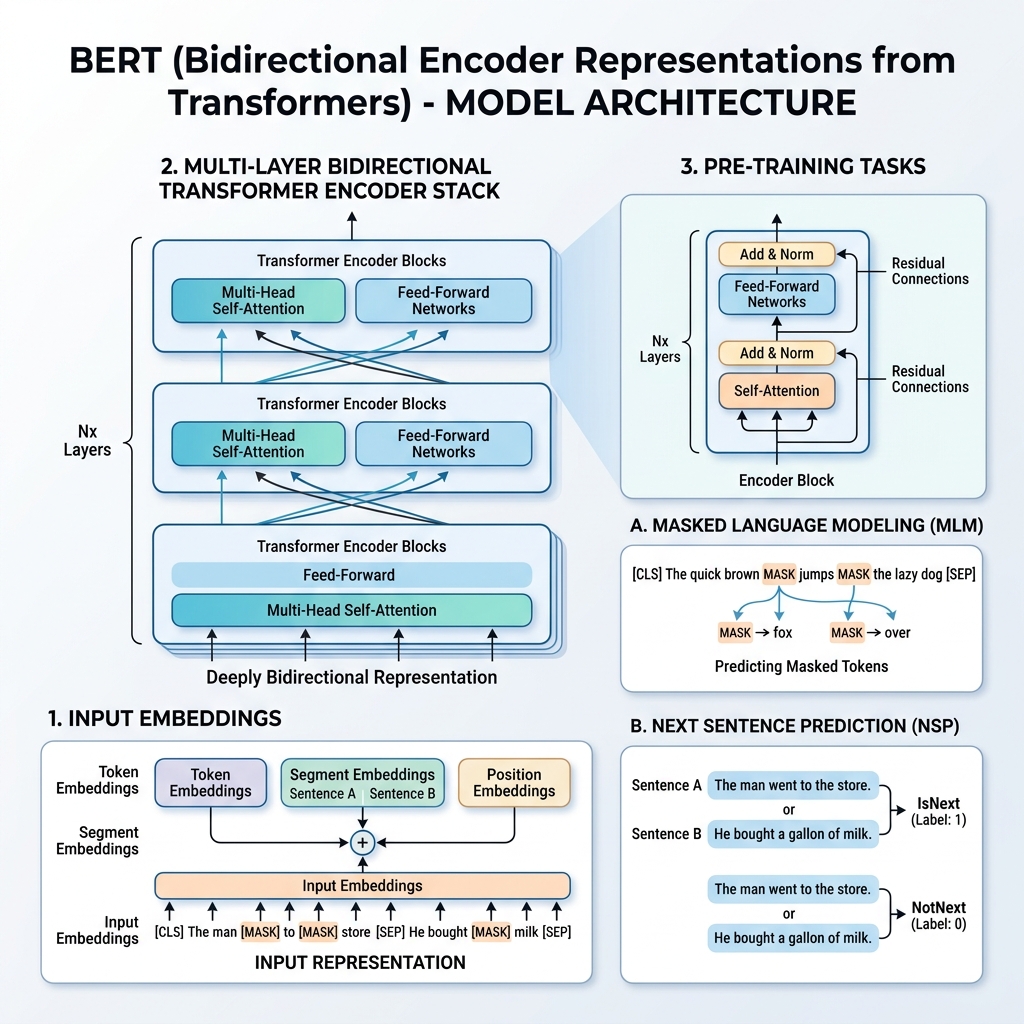
En 2018, los investigadores de Google publicaron un artículo fundamental titulado “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding” (Devlin et al.). Esta investigación transformó fundamentalmente el campo del Procesamiento del Lenguaje Natural (NLP). Antes de BERT, los modelos procesaban el texto de forma secuencial de izquierda a derecha o de derecha a izquierda. BERT introdujo un método para entrenar representaciones de lenguaje que consideran el contexto desde ambas direcciones simultáneamente.
Hoy en día, BERT y sus descendientes (como RoBERTa, DistilBERT y ALBERT) siguen siendo fundamentales para motores de búsqueda, análisis de sentimiento, sistemas de respuesta a preguntas y extracción de información. Este artículo desmitifica la arquitectura de BERT, cómo funciona y cómo se entrena.
1. ¿Qué es BERT?
BERT significa Bidirectional Encoder Representations from Transformers (Representaciones de Encoder Bidireccionales a partir de Transformers). Desglosemos este nombre:
- Bidireccional (Bidirectional): A diferencia de los modelos de lenguaje tradicionales que leen el texto de izquierda a derecha (como GPT) o de derecha a izquierda, BERT lee la secuencia completa de palabras a la vez. Esto le permite aprender el contexto de una palabra en función de todo su entorno (tanto a la izquierda como a la derecha).
- Representaciones de Encoder (Encoder Representations): BERT utiliza la parte del Encoder (Codificador) de la arquitectura Transformer original. Toma una secuencia de entrada y produce una representación vectorial densa (embedding) para cada token.
- Transformers: El motor subyacente es la red de atención del Transformer, que permite modelar dependencias de largo alcance y realizar cómputos en paralelo.
El poder de la bidireccionalidad
En los modelos unidireccionales, un token solo puede prestar atención a los tokens anteriores. Por ejemplo, en la oración:
"Decidió depositar su dinero en el banco."
Si un modelo unidireccional procesa "banco", solo mira las palabras anteriores. Pero para comprender completamente el contexto, es crucial mirar tanto el contexto izquierdo como el derecho. Mientras que las LSTM bidireccionales intentaron esto entrenando modelos separados de izquierda a derecha y de derecha a izquierda y concatenando las salidas, BERT entrena un único modelo profundamente bidireccional de forma conjunta en todas las capas.
2. Representación de entrada de BERT
Para permitir el entrenamiento en múltiples tareas posteriores, la representación de entrada de BERT puede representar tanto una sola oración como un par de oraciones (por ejemplo, <Pregunta, Respuesta>) en una sola secuencia de tokens.
Para cualquier token dado, su representación de entrada se construye sumando tres embeddings:
- Token Embeddings: El texto se tokeniza utilizando el vocabulario WordPiece (aproximadamente 30,000 tokens). Se añaden tokens especiales:
[CLS]: Insertado al principio de cada secuencia. Su estado oculto final se utiliza para tareas de clasificación.[SEP]: Utilizado para separar oraciones o al final de una secuencia.
- Segment Embeddings: Un embedding aprendido que indica si un token pertenece a la Oración A o a la Oración B.
- Position Embeddings: Vectores posicionales aprendidos que se añaden para dar al modelo conciencia de la posición del token en la secuencia (hasta 512 tokens).
$$\text{Representación de Entrada} = \text{Token Embeddings} + \text{Segment Embeddings} + \text{Position Embeddings}$$
3. El proceso de preentrenamiento
BERT se preentrena en un corpus masivo (Wikipedia y BooksCorpus) utilizando simultáneamente dos tareas no supervisadas: Masked Language Model (MLM) (Modelo de Lenguaje Enmascarado) y Next Sentence Prediction (NSP) (Predicción de la Siguiente Oración).
Tarea 1: Masked Language Model (MLM)
En el modelado de lenguaje estándar, predecir la siguiente palabra restringe los modelos a arquitecturas de izquierda a derecha para evitar que la palabra objetivo se “vea” a sí misma. Para entrenar una representación bidireccional profunda, BERT enmascara aleatoriamente un porcentaje de los tokens de entrada y los predice.
Específicamente:
- Se elige al azar el 15% de los tokens de entrada.
- De los tokens elegidos:
- El 80% se reemplaza con el token
[MASK]. - El 10% se reemplaza con una palabra aleatoria.
- El 10% se mantiene sin cambios.
- El 80% se reemplaza con el token
Esta receta evita que el modelo se concentre solo en el token [MASK] durante el ajuste fino (ya que [MASK] nunca aparece durante el ajuste fino) y lo obliga a construir vectores de representación para cada palabra en el contexto.
Tarea 2: Next Sentence Prediction (NSP)
Muchos problemas posteriores (como la respuesta a preguntas y la inferencia de lenguaje natural) dependen de comprender la relación entre dos oraciones. Para entrenar el modelo en relaciones de oraciones, BERT se preentrena en una tarea de clasificación binaria:
Al elegir las oraciones $A$ y $B$ para el preentrenamiento:
- El 50% de las veces, $B$ es la siguiente oración real que sigue a $A$ (etiquetada como
IsNext). - El 50% de las veces, $B$ es una oración aleatoria del corpus (etiquetada como
NotNext).
El vector oculto final del token [CLS] se pasa a una capa de clasificación para predecir la etiqueta.
4. Ajuste fino (Fine-Tuning) de BERT
Una de las mayores fortalezas de BERT es su flexibilidad. El preentrenamiento es costoso, pero el ajuste fino es increíblemente económico y rápido. Al reemplazar la capa de salida final, BERT se puede aplicar a muchas tareas posteriores diferentes:
- Clasificación de una sola oración: (por ejemplo, análisis de sentimiento). Use la salida del token
[CLS]. - Clasificación de pares de oraciones: (por ejemplo, inferencia de lenguaje natural). Use la salida del token
[CLS]. - Respuesta a preguntas: (por ejemplo, SQuAD). Prediga los tokens de inicio y fin del fragmento de respuesta en el documento.
- Etiquetado de una sola oración: (por ejemplo, Reconocimiento de Entidades Nombradas). Use la representación de salida de cada token individual.
5. Implementación en Python/Hugging Face
A continuación, se muestra un ejemplo simple en Python que demuestra cómo cargar un modelo BERT preentrenado y extraer embeddings de palabras contextuales utilizando Hugging Face Transformers y PyTorch:
import torch
from transformers import BertTokenizer, BertModel
# 1. Inicializar tokenizador y modelo
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertModel.from_pretrained('bert-base-uncased')
# 2. Definir texto que contiene la palabra "bank" en dos contextos
text_1 = "He deposited money in the bank."
text_2 = "The river bank was muddy."
# 3. Tokenizar entradas
inputs_1 = tokenizer(text_1, return_tensors="pt")
inputs_2 = tokenizer(text_2, return_tensors="pt")
# 4. Pase hacia adelante a través de BERT
with torch.no_grad():
outputs_1 = model(**inputs_1)
outputs_2 = model(**inputs_2)
# 5. Extraer embeddings de tokens
# dimensión de last_hidden_state: [batch_size, sequence_length, hidden_size]
embeddings_1 = outputs_1.last_hidden_state
embeddings_2 = outputs_2.last_hidden_state
# Inspeccionemos los tokens y sus índices
tokens_1 = tokenizer.convert_ids_to_tokens(inputs_1["input_ids"][0])
tokens_2 = tokenizer.convert_ids_to_tokens(inputs_2["input_ids"][0])
# Encontrar el índice de la palabra 'bank'
bank_idx_1 = tokens_1.index("bank")
bank_idx_2 = tokens_2.index("bank")
# Obtener vectores de embedding para la palabra 'bank'
bank_emb_1 = embeddings_1[0, bank_idx_1]
bank_emb_2 = embeddings_2[0, bank_idx_2]
# Calcular similitud de coseno
cosine_sim = torch.nn.functional.cosine_similarity(bank_emb_1, bank_emb_2, dim=0)
print("Tokens 1:", tokens_1)
print("Tokens 2:", tokens_2)
print(f"Similitud de coseno entre ambos embeddings contextuales de 'bank': {cosine_sim.item():.4f}")
6. Configuraciones del modelo BERT
Google lanzó dos configuraciones principales de BERT:
| Hiperparámetro | BERT-Base | BERT-Large |
|---|---|---|
| Número de Capas ($L$) | 12 | 24 |
| Tamaño Oculto ($H$) | 768 | 1024 |
| Cabezales de Atención ($A$) | 12 | 16 |
| Parámetros Totales | 110 Millones | 340 Millones |
Conclusión
BERT demostró que las representaciones bidireccionales profundas entrenadas en grandes cantidades de texto sin etiquetar pueden capturar estructuras sintácticas y semánticas complejas. Estableció un nuevo paradigma para el aprendizaje por transferencia en NLP, definiendo el flujo de trabajo de preentrenamiento y luego ajuste fino que dominó la IA hasta el surgimiento de los modelos autorregresivos basados solo en decoder (como GPT).