ماڈل کو سمجھنا: ٹرانسفارمرز سے دوطرفہ انکوڈر نمائندگی BERT
2018 میں، گوگل کے محققین نے ایک تاریخی مقالہ شائع کیا جس کا عنوان تھا “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding” (Devlin et al.)۔ اس تحقیق نے نیچرل لینگویج پروسیسنگ (NLP) کے شعبے کو بنیادی طور پر بدل دیا۔ BERT سے پہلے، ماڈل متن کو بائیں سے دائیں یا دائیں سے بائیں ترتیب وار پروسیس کرتے تھے۔ BERT نے زبان کی ایسی نمائندگیوں کو تربیت دینے کا طریقہ متعارف کرایا جو ایک ہی وقت میں دونوں سمتوں سے سیاق و سباق کو دیکھتی ہیں۔
آج، BERT اور اس کی نسلیں (جیسے RoBERTa، DistilBERT، اور ALBERT) سرچ انجنوں، جذبات کے تجزیہ، سوال و جواب کے نظام، اور معلومات کے اخراج کے لیے بنیادی حیثیت رکھتے ہیں۔ یہ مضمون BERT کی ساخت، اس کے کام کرنے کے طریقے اور اس کی تربیت کی وضاحت کرتا ہے۔
1. بی آر ٹی (BERT) کیا ہے؟
BERT کا مطلب ہے Bidirectional Encoder Representations from Transformers۔ آئیے اس نام کو سمجھتے ہیں:
- دوطرفہ (Bidirectional): روایتی زبان کے ماڈلز کے برعکس جو بائیں سے دائیں (جیسے GPT) یا دائیں سے بائیں متن پڑھتے ہیں، BERT ایک ہی وقت میں الفاظ کی پوری ترتیب کو پڑھتا ہے۔ یہ اسے ایک لفظ کے سیاق و سباق کو اس کے پورے ماحول (بائیں اور دائیں دونوں) کی بنیاد پر سیکھنے کی اجازت دیتا ہے۔
- انکوڈر نمائندگی (Encoder Representations): BERT اصل ٹرانسفارمر فن تعمیر کے انکوڈر (Encoder) والے حصے کو استعمال کرتا ہے۔ یہ ان پٹ کی ترتیب لیتا ہے اور ہر ٹوکن کے لیے ایک ویکٹر نمائندگی (embedding) فراہم کرتا ہے۔
- ٹرانسفارمرز (Transformers): اس کا بنیادی انجن ٹرانسفارمر اٹینشن نیٹ ورک ہے، جو طویل فاصلے کے روابط کو ماڈل کرنے اور متوازی کمپیوٹنگ کے قابل بناتا ہے۔
دوطرفہ پروسیسنگ کی طاقت
ایک طرفہ ماڈلز میں، ایک ٹوکن صرف پچھلے ٹوکنز پر توجہ مرکوز کر سکتا ہے۔ مثال کے طور پر، اس جملے میں:
"اس نے بینک میں رقم جمع کرانے کا فیصلہ کیا۔"
اگر ایک طرفہ ماڈل لفظ "بینک" پر کارروائی کرتا ہے، تو وہ صرف اس سے پہلے آنے والے الفاظ کو دیکھتا ہے۔ لیکن سیاق و سباق کو مکمل طور پر سمجھنے کے لیے، بائیں اور دائیں دونوں اطراف کا سیاق و سباق دیکھنا بہت ضروری ہے۔ اگرچہ دوطرفہ LSTMs نے بائیں سے دائیں اور دائیں سے بائیں الگ الگ ماڈلز کی تربیت دے کر اور ان کے نتائج کو جوڑ کر ایسا کرنے کی کوشش کی، لیکن BERT تمام تہوں میں مشترکہ طور پر ایک ہی گہرا دوطرفہ ماڈل تربیت دیتا ہے۔
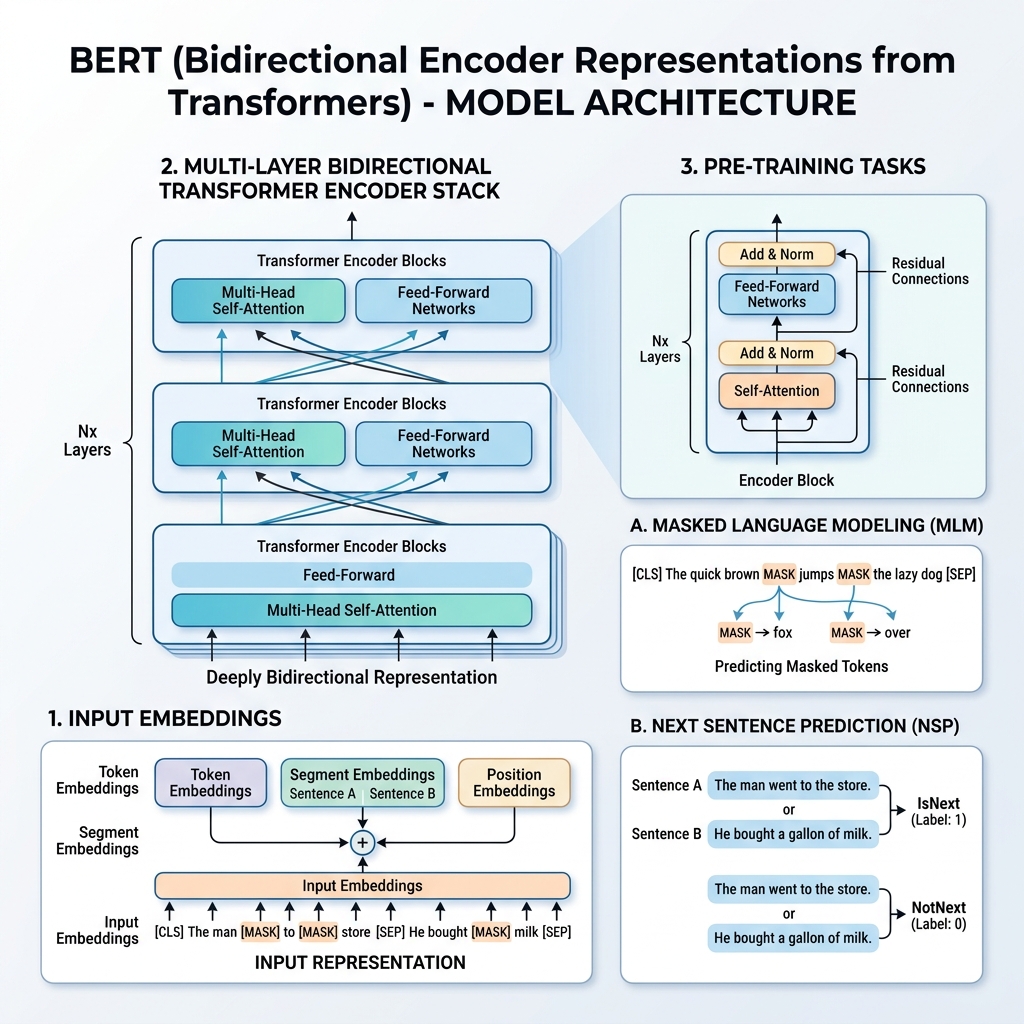
2. ان پٹ کی نمائندگی
مختلف کاموں پر تربیت کے قابل بنانے کے لیے، BERT کی ان پٹ نمائندگی ایک ہی جملے اور جملوں کے جوڑے (جیسے <سوال، جواب>) دونوں کو ایک ہی ٹوکن کی ترتیب میں ظاہر کر سکتی ہے۔
کسی بھی ٹوکن کے لیے، اس کی ان پٹ نمائندگی تین قسم کے ایمبیڈنگز کو جمع کر کے بنائی جاتی ہے:
- ٹوکن ایمبیڈنگز (Token Embeddings): متن کو WordPiece الفاظ کی فہرست (تقریباً 30,000 ٹوکنز) کا استعمال کرتے ہوئے ٹوکنز میں تقسیم کیا جاتا ہے۔ خصوصی ٹوکنز شامل کیے جاتے ہیں:
[CLS]: ہر ترتیب کے شروع میں داخل کیا جاتا ہے۔ اس کی آخری پوشیدہ حالت کو درجہ بندی کے کاموں کے لیے استعمال کیا جاتا ہے۔[SEP]: جملوں کو الگ کرنے کے لیے یا ترتیب کے آخر میں استعمال ہوتا ہے۔
- سگمنٹ ایمبیڈنگز (Segment Embeddings): ایک سیکھی ہوئی ایمبیڈنگ جو یہ بتاتی ہے کہ آیا ٹوکن جملہ A سے تعلق رکھتا ہے یا جملہ B سے۔
- پوزیشن ایمبیڈنگز (Position Embeddings): سیکھے ہوئے پوزیشنی ویکٹرز جو ماڈل کو ترتیب میں ٹوکن کی پوزیشن سے باخبر رکھنے کے لیے شامل کیے جاتے ہیں (512 ٹوکنز تک)۔
$$\text{ان پٹ نمائندگی} = \text{ٹوکن ایمبیڈنگز} + \text{سگمنٹ ایمبیڈنگز} + \text{پوزیشن ایمبیڈنگز}$$
3. پری ٹریننگ کا عمل
BERT کو ایک بڑے متن کے ذخیرے (Wikipedia اور BooksCorpus) پر بیک وقت دو غیر زیر نگرانی کاموں کا استعمال کرتے ہوئے پہلے سے تربیت دی جاتی ہے: ماسکے ہوئے زبان کا ماڈل (MLM) اور اگلے جملے کی پیش گوئی (NSP)۔
پہلا کام: ماسکڈ لینگویج ماڈل (MLM)
معیاری زبان کے ماڈلنگ میں، اگلے لفظ کی پیش گوئی کرنا ماڈلز کو بائیں سے دائیں تک محدود کرتا ہے تاکہ ہدف کے لفظ کو خود کو “دیکھنے” سے روکا جا سکے۔ گہری دوطرفہ نمائندگی کی تربیت کے لیے، BERT تصادفی طور پر ان پٹ ٹوکنز کے کچھ فیصد کو ماسک (پوشیدہ) کر دیتا ہے اور ان کی پیش گوئی کرتا ہے۔
خاص طور پر:
- ان پٹ ٹوکنز میں سے تصادفی طور پر 15% کا انتخاب کیا جاتا ہے۔
- ان منتخب ٹوکنز میں سے:
- 80% کو
[MASK]ٹوکن سے بدل دیا جاتا ہے۔ - 10% کو کسی بھی دوسرے تصادفی لفظ سے بدل دیا جاتا ہے۔
- 10% کو بغیر کسی تبدیلی کے رکھا جاتا ہے۔
- 80% کو
یہ طریقہ ماڈل کو فائن ٹیوننگ کے دوران صرف [MASK] ٹوکن پر توجہ مرکوز کرنے سے روکتا ہے (کیونکہ فائن ٹیوننگ کے دوران [MASK] کبھی ظاہر نہیں ہوتا) اور اسے سیاق و سباق میں ہر لفظ کے لیے نمائندگی کے ویکٹر بنانے پر مجبور کرتا ہے۔
دوسرا کام: اگلے جملے کی پیش گوئی (NSP)
بہت سے کام (جیسے سوال و جواب اور قدرتی زبان کا استدلال) دو جملوں کے درمیان تعلق کو سمجھنے پر منحصر ہوتے ہیں۔ جملوں کے تعلقات پر ماڈل کی تربیت کے لیے، BERT کو بائنری درجہ بندی کے کام پر پہلے سے تربیت دی جاتی ہے:
پری ٹریننگ کے لیے جملے $A$ اور $B$ کا انتخاب کرتے وقت:
- 50% وقت، $B$ واقعی اگلا جملہ ہوتا ہے جو $A$ کے بعد آتا ہے (جس کا لیبل
IsNextہوتا ہے)۔ - 50% وقت، $B$ کارپس سے ایک تصادفی جملہ ہوتا ہے (جس کا لیبل
NotNextہوتا ہے)۔
لیبل کی پیش گوئی کرنے کے لیے [CLS] ٹوکن کا آخری پوشیدہ ویکٹر درجہ بندی کی تہہ کو منتقل کیا جاتا ہے۔
4. فائن ٹیوننگ (Fine-Tuning)
BERT کی سب سے بڑی طاقتوں میں سے ایک اس کی لچک ہے۔ پہلے سے تربیت دینا مہنگا ہے، لیکن فائن ٹیوننگ انتہائی سستی اور تیز ہے۔ فائنل آؤٹ پٹ لیئر کو تبدیل کر کے، BERT کو بہت سے مختلف کاموں پر لاگو کیا جا سکتا ہے:
- واحد جملے کی درجہ بندی: (جیسے جذبات کا تجزیہ)۔
[CLS]ٹوکن آؤٹ پٹ استعمال کریں۔ - جملوں کے جوڑے کی درجہ بندی: (جیسے قدرتی زبان کا استدلال)۔
[CLS]ٹوکن آؤٹ پٹ استعمال کریں۔ - سوال و جواب: (جیسے SQuAD)۔ دستاویز میں جواب کے شروع اور آخر کے ٹوکنز کی پیش گوئی کریں۔
- جملے کے ٹوکنز کی ٹیگنگ: (جیسے نامزد ہستی کی شناخت)۔ ہر انفرادی ٹوکن کی آؤٹ پٹ نمائندگی استعمال کریں۔
5. پائتھن / ہگنگ فیس کا نفاذ
نیچے ایک آسان پائتھن کوڈ دیا گیا ہے جو یہ ظاہر کرتا ہے کہ پہلے سے تربیت یافتہ BERT ماڈل کو کیسے لوڈ کیا جائے اور Hugging Face Transformers اور PyTorch کا استعمال کرتے ہوئے سیاق و سباق کے مطابق الفاظ کی ایمبیڈنگ کیسے نکالی جائے:
import torch
from transformers import BertTokenizer, BertModel
# 1. ٹوکننائزر اور ماڈل شروع کریں
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertModel.from_pretrained('bert-base-uncased')
# 2. متن کی تعریف کریں جس میں لفظ "bank" دو الگ سیاق و سباق میں ہو
text_1 = "He deposited money in the bank."
text_2 = "The river bank was muddy."
# 3. ان پٹس کو ٹوکننائز کریں
inputs_1 = tokenizer(text_1, return_tensors="pt")
inputs_2 = tokenizer(text_2, return_tensors="pt")
# 4. BERT کے ذریعے فارورڈ پاس چلائیں
with torch.no_grad():
outputs_1 = model(**inputs_1)
outputs_2 = model(**inputs_2)
# 5. ٹوکن ایمبیڈنگز نکالیں
# last_hidden_state کا سائز: [batch_size, sequence_length, hidden_size]
embeddings_1 = outputs_1.last_hidden_state
embeddings_2 = outputs_2.last_hidden_state
# ٹوکنز اور ان کے انڈیکس دیکھیں
tokens_1 = tokenizer.convert_ids_to_tokens(inputs_1["input_ids"][0])
tokens_2 = tokenizer.convert_ids_to_tokens(inputs_2["input_ids"][0])
# لفظ 'bank' کا انڈیکس تلاش کریں
bank_idx_1 = tokens_1.index("bank")
bank_idx_2 = tokens_2.index("bank")
# لفظ 'bank' کے لیے ایمبیڈنگ ویکٹر حاصل کریں
bank_emb_1 = embeddings_1[0, bank_idx_1]
bank_emb_2 = embeddings_2[0, bank_idx_2]
# کوسائن مماثلت کا حساب لگائیں
cosine_sim = torch.nn.functional.cosine_similarity(bank_emb_1, bank_emb_2, dim=0)
print("Tokens 1:", tokens_1)
print("Tokens 2:", tokens_2)
print(f"لفظ 'bank' کے دونوں سیاق و سباق کی ایمبیڈنگز کے درمیان کوسائن مماثلت: {cosine_sim.item():.4f}")
6. ماڈل کی کنفیگریشنز
گوگل نے BERT کی دو اہم کنفیگریشنز جاری کیں:
| پیرامیٹر | BERT-Base | BERT-Large |
|---|---|---|
| تہوں کی تعداد ($L$) | 12 | 24 |
| پوشیدہ سائز ($H$) | 768 | 1024 |
| توجہ کے ہیڈز ($A$) | 12 | 16 |
| کل پیرامیٹرز | 110 ملین | 340 ملین |
نتیجہ
BERT نے ثابت کیا کہ بغیر لیبل والے بڑے متن پر تربیت یافتہ گہری دوطرفہ نمائندگی پیچیدہ نحوی اور معنوی ساخت کو پکڑ سکتی ہے۔ اس نے NLP میں ٹرانسفر لرننگ کے لیے ایک نیا نمونہ قائم کیا، جس نے پری ٹریننگ اور فائن ٹیوننگ کے طریقہ کار کو قائم کیا جو طویل عرصے تک غالب رہا۔