深入理解 BERT 模型:双向 Transformer 编码器表示
2018 年,Google 研究人员发表了一篇具有里程碑意义的论文,题为 “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding”(Devlin 等人)。这项研究彻底改变了自然语言处理(NLP)领域。在 BERT 之前,模型大多是自左向右或自右向左单向处理文本。BERT 引入了一种方法,可以同时从两个方向来训练语言表示。
今天,BERT 及其衍生模型(如 RoBERTa、DistilBERT 和 ALBERT)仍然是搜索引擎、情感分析、问答系统和信息提取的基石。本文将带您揭开 BERT 架构的神秘面纱,解析其工作原理和训练方式。
1. 什么是 BERT?
BERT 的全称是 Bidirectional Encoder Representations from Transformers(基于 Transformers 的双向编码器表示)。让我们拆解一下这个名字:
- 双向(Bidirectional): 与从左到右(如 GPT)或从右到左读取文本的传统语言模型不同,BERT 一次性读取整个单词序列。这使它能够根据某个单词的整个上下文(左右两侧)来学习该单词的语义。
- 编码器表示(Encoder Representations): BERT 使用了原始 Transformer 架构中的**编码器(Encoder)**部分。它接收输入序列,并为每个 token 输出一个密集的向量表示(嵌入/embedding)。
- Transformers: 其底层引擎是 Transformer 注意力网络,它能够对长距离依赖关系进行建模并支持并行计算。
双向表示的强大之处
在单向模型中,一个 token 只能关注之前的 token。例如在句子中:
“他决定把钱存进银行(bank)。”
如果单向模型处理到 "bank",它只看它前面的词。但是,要完整理解上下文,同时查看左侧和右侧的上下文至关重要。虽然双向 LSTM 曾尝试通过分别训练自左向右和自右向左的模型并拼接输出,但 BERT 则是通过在所有层中联合训练一个单一的、深层双向模型来实现这一点的。
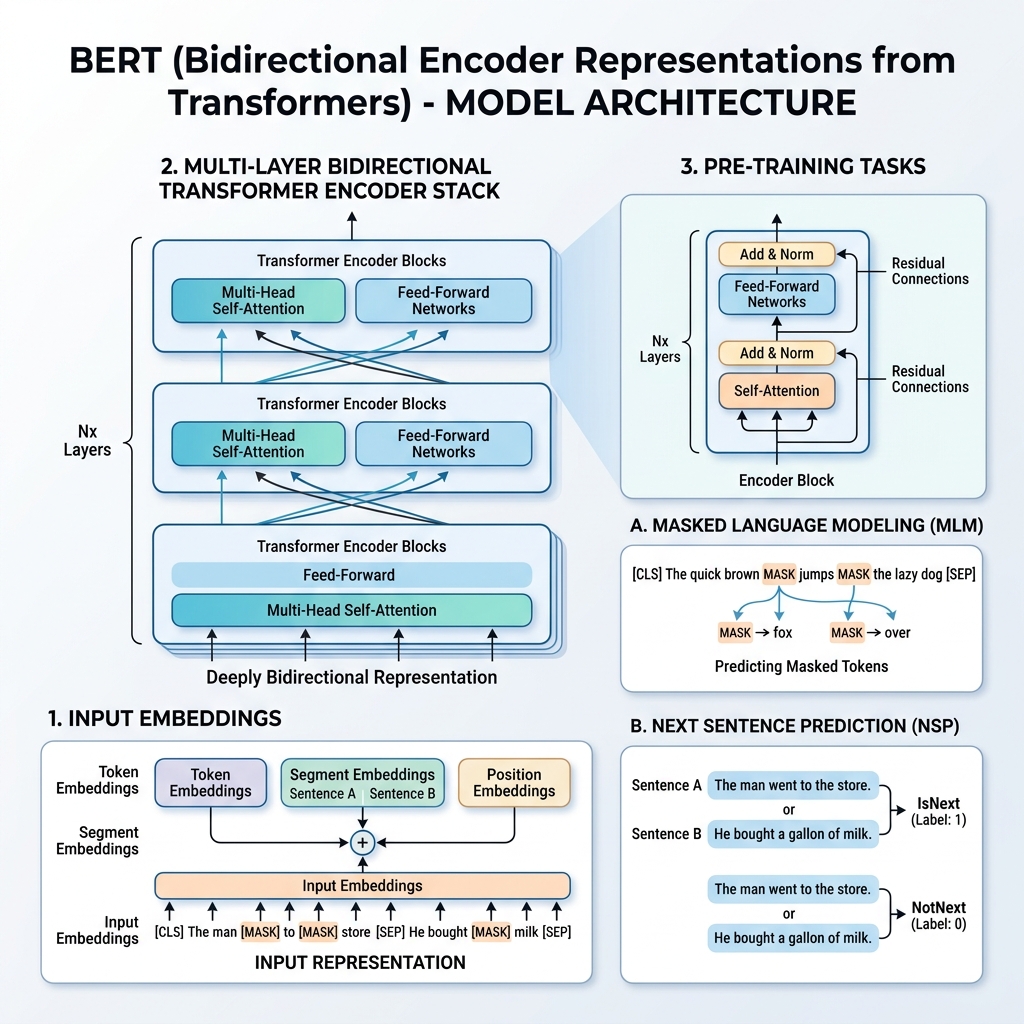
2. BERT 的输入表示
为了支持在多种下游任务上进行训练,BERT 的输入表示可以在单个 token 序列中同时表示单个句子和句子对(例如 <问题, 答案>)。
对于任何给定的 token,其输入表示是通过将三种嵌入相加来构建的:
- Token 嵌入(Token Embeddings): 文本使用 WordPiece 词汇表(约 30,000 个 token)进行分词。其中加入了特殊 token:
[CLS]:插入在每个序列的开头。其最终的隐状态用于分类任务。[SEP]:用于分隔句子或放在序列末尾。
- 段嵌入(Segment Embeddings): 一个学到的嵌入,指示该 token 属于句子 A 还是句子 B。
- 位置嵌入(Position Embeddings): 学到的位置向量,加到输入中以使模型感知 token 在序列中的位置(最高支持 512 个 token)。
$$\text{输入表示} = \text{Token 嵌入} + \text{段嵌入} + \text{位置嵌入}$$
3. 预训练过程
BERT 在海量语料库(维基百科和 BooksCorpus)上,通过同时执行两个无监督任务来进行预训练:掩码语言模型(MLM)和下一句预测(NSP)。
任务 1:掩码语言模型(MLM)
在标准的语言建模中,预测下一个词的设定限制了模型只能使用自左向右的架构,以防止目标词“看到”自身。为了训练深层双向表示,BERT 随机掩码输入 token 的一定比例,并对其进行预测。
具体来说:
- 随机选择输入 token 的 15%。
- 在选中的 token 中:
- 80% 被替换为
[MASK]token。 - 10% 被替换为一个随机词。
- 10% 保持不变。
- 80% 被替换为
这种设计可以防止模型在微调期间仅依赖 [MASK] token(因为微调期间不会出现 [MASK]),并强迫它为上下文中的每个词构建坚实的表示向量。
任务 2:下一句预测(NSP)
许多下游任务(如问答和自然语言推理)依赖于理解两个句子之间的关系。为了训练模型理解句子关系,BERT 在二分类任务上进行了预训练:
在为预训练选择句子 $A$ 和 $B$ 时:
- 50% 的情况下,$B$ 是紧跟在 $A$ 之后的下一句(标记为
IsNext)。 - 50% 的情况下,$B$ 是来自语料库的随机句子(标记为
NotNext)。
最终 [CLS] token 对应的隐向量会被传递给分类层以预测标签。
4. 微调 BERT
BERT 的一大核心优势在于其灵活性。预训练的成本非常高昂,但**微调(Fine-tuning)**却极其快速且成本低廉。通过替换最终的输出层,BERT 可以应用于许多不同的下游任务:
- 单句分类:(例如情感分析)。使用
[CLS]token 的输出。 - 句子对分类:(例如自然语言推理)。使用
[CLS]token 的输出。 - 问答任务:(例如 SQuAD)。预测文档中答案起始和结束的 token 跨度。
- 单句序列标注:(例如命名实体识别/NER)。使用每个 token 对应的输出表示。
5. Python / Hugging Face 代码实现
下面是一个简单的 Python 示例,演示如何使用 Hugging Face Transformers 和 PyTorch 加载预训练的 BERT 模型并提取上下文词嵌入:
import torch
from transformers import BertTokenizer, BertModel
# 1. 初始化分词器和模型
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertModel.from_pretrained('bert-base-uncased')
# 2. 定义包含 "bank" 一词在两种上下文中的文本
text_1 = "He deposited money in the bank."
text_2 = "The river bank was muddy."
# 3. 编码输入
inputs_1 = tokenizer(text_1, return_tensors="pt")
inputs_2 = tokenizer(text_2, return_tensors="pt")
# 4. BERT 前向传播
with torch.no_grad():
outputs_1 = model(**inputs_1)
outputs_2 = model(**inputs_2)
# 5. 提取 token 嵌入
# last_hidden_state 维度: [batch_size, sequence_length, hidden_size]
embeddings_1 = outputs_1.last_hidden_state
embeddings_2 = outputs_2.last_hidden_state
# 检查 token 及其索引
tokens_1 = tokenizer.convert_ids_to_tokens(inputs_1["input_ids"][0])
tokens_2 = tokenizer.convert_ids_to_tokens(inputs_2["input_ids"][0])
# 找到单词 'bank' 的索引
bank_idx_1 = tokens_1.index("bank")
bank_idx_2 = tokens_2.index("bank")
# 获取单词 'bank' 的向量表示
bank_emb_1 = embeddings_1[0, bank_idx_1]
bank_emb_2 = embeddings_2[0, bank_idx_2]
# 计算余弦相似度
cosine_sim = torch.nn.functional.cosine_similarity(bank_emb_1, bank_emb_2, dim=0)
print("Tokens 1:", tokens_1)
print("Tokens 2:", tokens_2)
print(f"两次不同上下文中 'bank' 的词嵌入余弦相似度: {cosine_sim.item():.4f}")
6. BERT 模型配置
Google 发布了两种主要的 BERT 配置:
| 超参数 | BERT-Base | BERT-Large |
|---|---|---|
| 层数 ($L$) | 12 | 24 |
| 隐层维度 ($H$) | 768 | 1024 |
| 注意力头数 ($A$) | 12 | 16 |
| 总参数量 | 1.1 亿 (110M) | 3.4 亿 (340M) |
总结
BERT 证明了在海量无标记文本上训练的深度双向表示可以捕捉复杂的句法和语义结构。它为自然语言处理中的迁移学习树立了新的范式,确立了“预训练+微调”的工作流,这在自回归 Decoder-only 模型(如 GPT)兴起之前一直主导着 AI 领域。