Comprendre BERT: Représentations d'Encodeur Bidirectionnelles à partir de Transformers
En 2018, les chercheurs de Google ont publié un article fondateur intitulé “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding” (Devlin et al.). Cette recherche a fondamentalement transformé le domaine du traitement du langage naturel (NLP). Avant BERT, les modèles traitaient le texte de manière séquentielle, de gauche à droite ou de droite à gauche. BERT a introduit une méthode pour entraîner des représentations de langage qui examinent simultanément le contexte dans les deux directions.
Aujourd’hui, BERT et ses descendants (comme RoBERTa, DistilBERT et ALBERT) restent fondamentaux pour les moteurs de recherche, l’analyse de sentiment, les systèmes de questions-réponses et l’extraction d’informations. Cet article démystifie l’architecture de BERT, son fonctionnement et la manière dont il est entraîné.
1. Qu’est-ce que BERT?
BERT signifie Bidirectional Encoder Representations from Transformers (Représentations d’Encodeur Bidirectionnelles à partir de Transformers). Décomposons ce nom :
- Bidirectionnel (Bidirectional) : Contrairement aux modèles de langage traditionnels qui lisent le texte de gauche à droite (comme GPT) ou de droite à gauche, BERT lit l’intégralité de la séquence de mots en une seule fois. Cela lui permet d’apprendre le contexte d’un mot en se basant sur l’ensemble de son environnement (à gauche comme à droite).
- Représentations d’Encodeur (Encoder Representations) : BERT utilise la partie Encodeur de l’architecture Transformer originale. Il prend une séquence d’entrée et produit une représentation vectorielle dense (embedding) pour chaque token.
- Transformers : Le moteur sous-jacent est le réseau d’attention du Transformer, qui permet de modéliser les dépendances à longue portée et d’effectuer des calculs en parallèle.
La puissance de la bidirectionnalité
Dans les modèles unidirectionnels, un token ne peut prêter attention qu’aux tokens précédents. Par exemple, dans la phrase :
"Il a décidé de déposer son argent à la banque."
Si un modèle unidirectionnel traite le mot "banque", il ne regarde que les mots qui le précèdent. Mais pour comprendre pleinement le contexte, il est crucial d’examiner le contexte gauche et droit. Bien que les LSTM bidirectionnels aient tenté d’y parvenir en entraînant des modèles distincts de gauche à droite et de droite à gauche et en concaténant les sorties, BERT entraîne un modèle unique profondément bidirectionnel de manière conjointe sur toutes les couches.
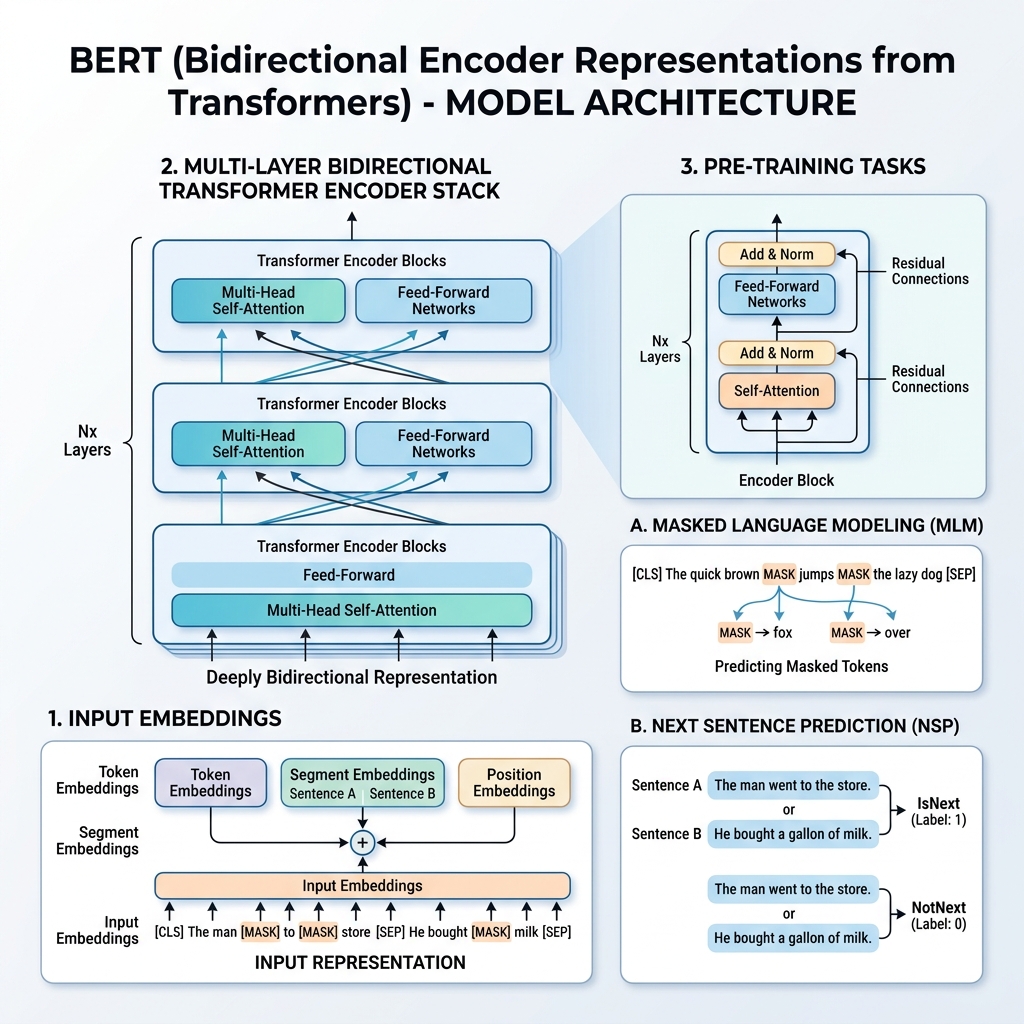
2. Représentation d’entrée de BERT
Pour permettre l’entraînement sur de multiples tâches en aval, la représentation d’entrée de BERT peut représenter à la fois une phrase unique et une paire de phrases (par exemple, <Question, Réponse>) dans une seule séquence de tokens.
Pour tout token donné, sa représentation d’entrée est construite en additionnant trois embeddings :
- Token Embeddings : Le texte est tokenisé à l’aide du vocabulaire WordPiece (environ 30 000 tokens). Des tokens spéciaux sont ajoutés :
[CLS]: Inséré au début de chaque séquence. Son état caché final est utilisé pour les tâches de classification.[SEP]: Utilisé pour séparer les phrases ou à la fin d’une séquence.
- Segment Embeddings : Un embedding appris indiquant si un token appartient à la phrase A ou à la phrase B.
- Position Embeddings : Vecteurs de position appris ajoutés pour donner au modèle conscience de la position du token dans la séquence (jusqu’à 512 tokens).
$$\text{Représentation d’Entrée} = \text{Token Embeddings} + \text{Segment Embeddings} + \text{Position Embeddings}$$
3. Le processus de pré-entraînement
BERT est pré-entraîné sur un corpus massif (Wikipedia et BooksCorpus) en utilisant simultanément deux tâches non supervisées : le Masked Language Model (MLM) (Modèle de Langage Masqué) et la Next Sentence Prediction (NSP) (Prédiction de la Phrase Suivante).
Tâche 1: Masked Language Model (MLM)
Dans la modélisation de langage standard, la prédiction du mot suivant restreint les modèles aux architectures de gauche à droite afin d’empêcher le mot cible de “voir” sa propre valeur. Pour entraîner une représentation bidirectionnelle profonde, BERT masque aléatoirement un pourcentage des tokens d’entrée et les prédit.
Plus précisément :
- 15 % des tokens d’entrée sont choisis au hasard.
- Parmi les tokens choisis :
- 80 % sont remplacés par le token
[MASK]. - 10 % sont remplacés par un mot aléatoire.
- 10 % sont conservés sans modification.
- 80 % sont remplacés par le token
Cette méthode empêche le modèle de se concentrer uniquement sur le token [MASK] pendant le réglage fin (puisque [MASK] n’apparaît jamais lors du réglage fin) et le force à construire des vecteurs de représentation pour chaque mot en contexte.
Tâche 2: Next Sentence Prediction (NSP)
De nombreuses tâches en aval (comme les systèmes de questions-réponses et l’inférence textuelle) dépendent de la compréhension de la relation entre deux phrases. Pour entraîner le modèle sur les relations entre phrases, BERT est pré-entraîné sur une tâche de classification binaire :
Lors de la sélection des phrases $A$ et $B$ pour le pré-entraînement :
- Dans 50 % des cas, $B$ est la phrase suivante réelle qui suit $A$ (étiquetée comme
IsNext). - Dans 50 % des cas, $B$ est une phrase aléatoire du corpus (étiquetée comme
NotNext).
Le vecteur caché final du token [CLS] est transmis à une couche de classification pour prédire l’étiquette.
4. Réglage fin (Fine-Tuning) de BERT
L’une des plus grandes forces de BERT est sa flexibilité. Le pré-entraînement est coûteux, mais le réglage fin est incroyablement peu coûteux et rapide. En remplaçant la couche de sortie finale, BERT peut être appliqué à de nombreuses tâches en aval différentes :
- Classification de phrase unique : (par exemple, analyse de sentiment). Utilisez la sortie du token
[CLS]. - Classification de paire de phrases : (par exemple, inférence textuelle). Utilisez la sortie du token
[CLS]. - Questions-Réponses : (par exemple, SQuAD). Prédisez les tokens de début et de fin de la réponse dans le document.
- Étiquetage de phrase unique : (par exemple, reconnaissance d’entités nommées). Utilisez la représentation de sortie de chaque token individuel.
5. Implémentation Python/Hugging Face
Voici un exemple Python simple démontrant comment charger un modèle BERT pré-entraîné et extraire des embeddings de mots contextuels à l’aide de Hugging Face Transformers et PyTorch :
import torch
from transformers import BertTokenizer, BertModel
# 1. Initialiser le tokenizer et le modèle
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertModel.from_pretrained('bert-base-uncased')
# 2. Définir le texte contenant le mot "bank" dans deux contextes
text_1 = "He deposited money in the bank."
text_2 = "The river bank was muddy."
# 3. Tokeniser les entrées
inputs_1 = tokenizer(text_1, return_tensors="pt")
inputs_2 = tokenizer(text_2, return_tensors="pt")
# 4. Passage direct à travers BERT
with torch.no_grad():
outputs_1 = model(**inputs_1)
outputs_2 = model(**inputs_2)
# 5. Extraire les embeddings de tokens
# forme de last_hidden_state : [batch_size, sequence_length, hidden_size]
embeddings_1 = outputs_1.last_hidden_state
embeddings_2 = outputs_2.last_hidden_state
# Inspectons les tokens et leurs indices
tokens_1 = tokenizer.convert_ids_to_tokens(inputs_1["input_ids"][0])
tokens_2 = tokenizer.convert_ids_to_tokens(inputs_2["input_ids"][0])
# Trouver l'index du mot 'bank'
bank_idx_1 = tokens_1.index("bank")
bank_idx_2 = tokens_2.index("bank")
# Obtenir les vecteurs d'embedding pour le mot 'bank'
bank_emb_1 = embeddings_1[0, bank_idx_1]
bank_emb_2 = embeddings_2[0, bank_idx_2]
# Calculer la similarité cosinus
cosine_sim = torch.nn.functional.cosine_similarity(bank_emb_1, bank_emb_2, dim=0)
print("Tokens 1:", tokens_1)
print("Tokens 2:", tokens_2)
print(f"Similarité cosinus entre les deux embeddings contextuels de 'bank': {cosine_sim.item():.4f}")
6. Configurations du modèle BERT
Google a publié deux configurations principales de BERT :
| Hyperparamètre | BERT-Base | BERT-Large |
|---|---|---|
| Nombre de couches ($L$) | 12 | 24 |
| Taille cachée ($H$) | 768 | 1024 |
| Têtes d’attention ($A$) | 12 | 16 |
| Paramètres totaux | 110 Millions | 340 Millions |
Conclusion
BERT a prouvé que des représentations bidirectionnelles profondes entraînées sur de grands volumes de texte non étiqueté peuvent capturer des structures syntaxiques et sémantiques complexes. Il a établi un nouveau paradigme pour l’apprentissage par transfert en NLP, définissant le flux de travail d’entraînement préalable puis de réglage fin qui a dominé l’IA jusqu’à l’avènement des modèles autorégressifs basés uniquement sur un décodeur (comme GPT).