Compreendendo o BERT: Representações de Codificador Bidirecional de Transformers
Em 2018, os pesquisadores do Google publicaram um artigo marcante intitulado “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding” (Devlin et al.). Esta pesquisa mudou fundamentalmente o campo do Processamento de Linguagem Natural (NLP). Antes do BERT, os modelos processavam o texto sequencialmente da esquerda para a direita ou da direita para a esquerda. O BERT introduziu um método para treinar representações de linguagem que olham para o contexto de ambas as direções simultaneamente.
Hoje, o BERT e seus descendentes (como RoBERTa, DistilBERT e ALBERT) continuam fundamentais para mecanismos de busca, análise de sentimentos, sistemas de resposta a perguntas e extração de informações. Este artigo desmitifica a arquitetura BERT, como funciona e como é treinado.
1. O que é BERT?
BERT significa Bidirectional Encoder Representations from Transformers (Representações de Codificador Bidirecional de Transformers). Vamos desmembrar esse nome:
- Bidirecional (Bidirectional): Ao contrário dos modelos de linguagem tradicionais que leem o texto da esquerda para a direita (como o GPT) ou da direita para a esquerda, o BERT lê a sequência inteira de palavras de uma só vez. Isso permite que ele aprenda o contexto de uma palavra com base em todos os seus arredores (tanto à esquerda quanto à direita).
- Representações de Codificador (Encoder Representations): O BERT usa a parte do Encoder (Codificador) da arquitetura original do Transformer. Ele pega uma sequência de entrada e gera uma representação vetorial densa (embedding) para cada token.
- Transformers: O mecanismo subjacente é a rede de atenção do Transformer, que permite a modelagem de dependências de longo alcance e computação paralela.
O Poder da Bidirecionalidade
Em modelos unidirecionais, um token só pode prestar atenção aos tokens anteriores. Por exemplo, na frase:
"Ele decidiu depositar seu dinheiro no banco."
Se um modelo unidirecional processa "banco", ele olha apenas para as palavras anteriores. Mas para entender completamente o contexto, olhar para o contexto esquerdo e direito é crucial. Embora as LSTMs bidirecionais tenham tentado isso treinando modelos separados da esquerda para a direita e da direita para a esquerda e concatenando as saídas, o BERT treina um único modelo profundamente bidirecional de forma conjunta em todas as camadas.
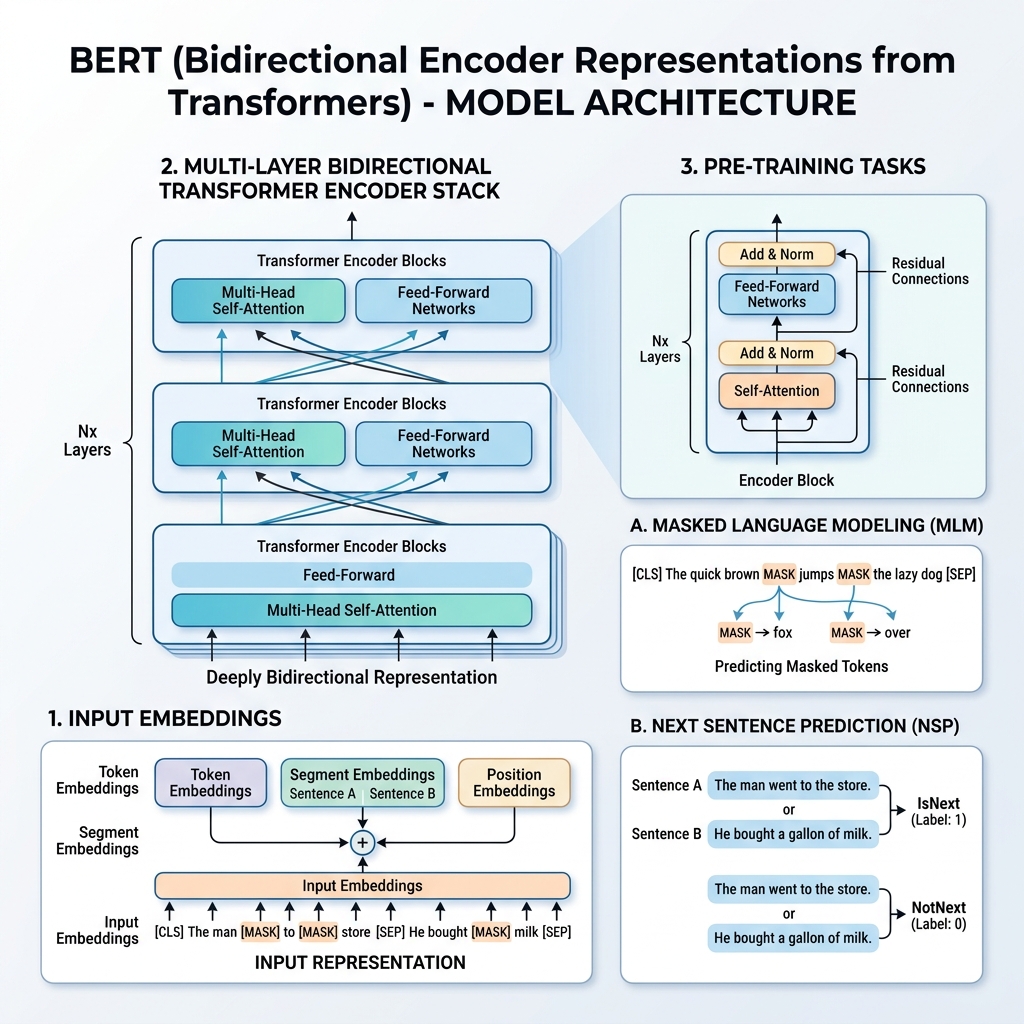
2. Representação de Entrada do BERT
Para permitir o treinamento em múltiplas tarefas subsequentes, a representação de entrada do BERT pode representar tanto uma única frase quanto um par de frases (por exemplo, <Pergunta, Resposta>) em uma única sequência de tokens.
Para qualquer token fornecido, sua representação de entrada é construída somando três embeddings:
- Token Embeddings: O texto é tokenizado usando o vocabulário WordPiece (cerca de 30.000 tokens). Tokens especiais são adicionados:
[CLS]: Inserido no início de cada sequência. Seu estado oculto final é usado para tarefas de classificação.[SEP]: Usado para separar frases ou no final de uma sequência.
- Segment Embeddings: Um embedding aprendido que indica se um token pertence à Frase A ou à Frase B.
- Position Embeddings: Vetores posicionais aprendidos adicionados para dar ao modelo a consciência da posição do token na sequência (até 512 tokens).
$$\text{Representação de Entrada} = \text{Token Embeddings} + \text{Segment Embeddings} + \text{Position Embeddings}$$
3. O Processo de Pré-treinamento
O BERT é pré-treinado em um enorme corpus (Wikipedia e BooksCorpus) usando duas tarefas não supervisionadas simultaneamente: Masked Language Model (MLM) (Modelo de Linguagem Mascarado) e Next Sentence Prediction (NSP) (Previsão da Próxima Frase).
Tarefa 1: Masked Language Model (MLM)
Na modelagem de linguagem padrão, prever a próxima palavra restringe os modelos a arquiteturas da esquerda para a direita para evitar que a palavra-alvo se “veja” a si mesma. Para treinar uma representação bidirecional profunda, o BERT mascara aleatoriamente uma porcentagem dos tokens de entrada e os prevê.
Especificamente:
- 15% dos tokens de entrada são escolhidos aleatoriamente.
- Desses tokens escolhidos:
- 80% são substituídos pelo token
[MASK]. - 10% são substituídos por uma palavra aleatória.
- 10% são mantidos inalterados.
- 80% são substituídos pelo token
Esta receita evita que o modelo se concentre apenas no token [MASK] durante o ajuste fino (já que [MASK] nunca aparece durante o ajuste fino) e o força a construir vetores de representação para cada palavra no contexto.
Tarefa 2: Next Sentence Prediction (NSP)
Muitas tarefas subsequentes (como Resposta a Perguntas e Inferência de Linguagem Natural) dependem da compreensão da relação entre duas frases. Para treinar o modelo nas relações de frases, o BERT é pré-treinado em uma tarefa de classificação binária:
Ao escolher as frases $A$ e $B$ para o pré-treinamento:
- 50% do tempo, $B$ é a frase seguinte real que segue $A$ (rotulada como
IsNext). - 50% do tempo, $B$ é uma frase aleatória do corpus (rotulada como
NotNext).
O vetor oculto final do token [CLS] é passado para uma camada de classificação para prever o rótulo.
4. Ajuste Fino (Fine-Tuning) do BERT
Uma das maiores forças do BERT é sua flexibilidade. O pré-treinamento é caro, mas o ajuste fino é incrivelmente barato e rápido. Ao trocar a camada de saída final, o BERT pode ser aplicado a muitas tarefas subsequentes diferentes:
- Classificação de Frase Única: (por exemplo, análise de sentimentos). Use a saída do token
[CLS]. - Classificação de Par de Frases: (por exemplo, inferência de linguagem natural). Use a saída do token
[CLS]. - Resposta a Perguntas: (por exemplo, SQuAD). Preveja os tokens de início e fim da resposta no documento.
- Marcação de Frase Única: (por exemplo, Reconhecimento de Entidade Nomeada). Use a representação de saída de cada token individual.
5. Implementação em Python/Hugging Face
Abaixo está um exemplo simples em Python demonstrando como carregar um modelo BERT pré-treinado e extrair embeddings de palavras contextuais usando Hugging Face Transformers e PyTorch:
import torch
from transformers import BertTokenizer, BertModel
# 1. Inicializar tokenizador e modelo
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertModel.from_pretrained('bert-base-uncased')
# 2. Definir texto contendo a palavra "bank" em dois contextos
text_1 = "He deposited money in the bank."
text_2 = "The river bank was muddy."
# 3. Tokenizar entradas
inputs_1 = tokenizer(text_1, return_tensors="pt")
inputs_2 = tokenizer(text_2, return_tensors="pt")
# 4. Passagem direta pelo BERT
with torch.no_grad():
outputs_1 = model(**inputs_1)
outputs_2 = model(**inputs_2)
# 5. Extrair embeddings de tokens
# shape de last_hidden_state: [batch_size, sequence_length, hidden_size]
embeddings_1 = outputs_1.last_hidden_state
embeddings_2 = outputs_2.last_hidden_state
# Vamos inspecionar os tokens e seus índices
tokens_1 = tokenizer.convert_ids_to_tokens(inputs_1["input_ids"][0])
tokens_2 = tokenizer.convert_ids_to_tokens(inputs_2["input_ids"][0])
# Encontrar o índice da palavra 'bank'
bank_idx_1 = tokens_1.index("bank")
bank_idx_2 = tokens_2.index("bank")
# Obter vetores de embedding para a palavra 'bank'
bank_emb_1 = embeddings_1[0, bank_idx_1]
bank_emb_2 = embeddings_2[0, bank_idx_2]
# Calcular similaridade de cosseno
cosine_sim = torch.nn.functional.cosine_similarity(bank_emb_1, bank_emb_2, dim=0)
print("Tokens 1:", tokens_1)
print("Tokens 2:", tokens_2)
print(f"Similaridade de cosseno entre ambos os embeddings contextuais de 'bank': {cosine_sim.item():.4f}")
6. Configurações do Modelo BERT
O Google lançou duas configurações principais do BERT:
| Hiperparametro | BERT-Base | BERT-Large |
|---|---|---|
| Número de Camadas ($L$) | 12 | 24 |
| Tamanho Oculto ($H$) | 768 | 1024 |
| Cabeças de Atenção ($A$) | 12 | 16 |
| Total de Parâmetros | 110 Milhões | 340 Milhões |
Conclusão
O BERT provou que representações bidirecionais profundas treinadas em textos massivos não rotulados podem capturar estruturas sintáticas e semânticas complexas. Ele definiu um novo paradigma para o aprendizado por transferência em NLP, estabelecendo o fluxo de trabalho de pré-treino e depois ajuste fino que dominou a IA até o surgimento de modelos autoregressivos apenas de decodificador (como o GPT).