הבנת BERT: ייצוגי אנקודר דו-כיווניים מטרנספורמרים
בשנת 2018, חוקרי גוגל פרסמו מאמר מכונן בשם “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding” (Devlin et al.). מחקר זה שינה מן היסוד את תחום עיבוד השפה הטבעית (NLP). לפני BERT, מודלים עיבדו טקסט באופן סדרתי משמאל לימין או מימין לשמאל. BERT הציג שיטה לאימון ייצוגי שפה המסתכלים על ההקשר משני הכיוונים בו-זמנית.
כיום, BERT וצאצאיו (כמו RoBERTa, DistilBERT ו-ALBERT) נותרו בסיסיים עבור מנועי חיפוש, ניתוח סנטימנט, מערכות מענה לשאלות וחילוץ מידע. מאמר זה חושף את ארכיטקטורת BERT, כיצד היא עובדת וכיצד היא מאומנת.
1. מה זה BERT?
BERT פירושו Bidirectional Encoder Representations from Transformers. בואו נפרק את השם הזה:
- דו-כיווני (Bidirectional): בניגוד למודלי שפה מסורתיים שקוראים טקסט משמאל לימין (כמו GPT) או מימין לשמאל, BERT קורא את כל רצף המילים בבת אחת. זה מאפשר לו ללמוד את ההקשר של מילה על סמך כל סביבתה (הן משמאל והן מימין).
- ייצוגי אנקודר (Encoder Representations): BERT משתמש בחלק ה-Encoder של ארכיטקטורת ה-Transformer המקורית. הוא מקבל רצף קלט ומפיק ייצוג וקטורי צפוף (embedding) עבור כל טוקן.
- טרנספורמרים (Transformers): המנוע הבסיסי הוא רשת הקשב (Attention) של ה-Transformer, המאפשרת מידול של תלות ארוכת טווח וחישוב מקבילי.
הכוח של דו-כיווניות
במודלים חד-כיווניים, טוקן יכול להתייחס רק לטוקנים קודמים. לדוגמה, במשפט:
"הוא החליט להפקיד את כספו בבנק."
אם מודל חד-כיווני מעבד את המילה “בנק”, הוא מסתכל רק על המילים שלפניה. אך כדי להבין את ההקשר במלואו, הסתכלות על ההקשר השמאלי והימני כאחד היא קריטית. בעוד ש-LSTMs דו-כיווניים ניסו זאת על ידי אימון מודלים נפרדים משמאל לימין ומימין לשמאל ושרשור הפלטים, BERT מאמן מודל דו-כיווני עמוק יחיד במשותף בכל השכבות.
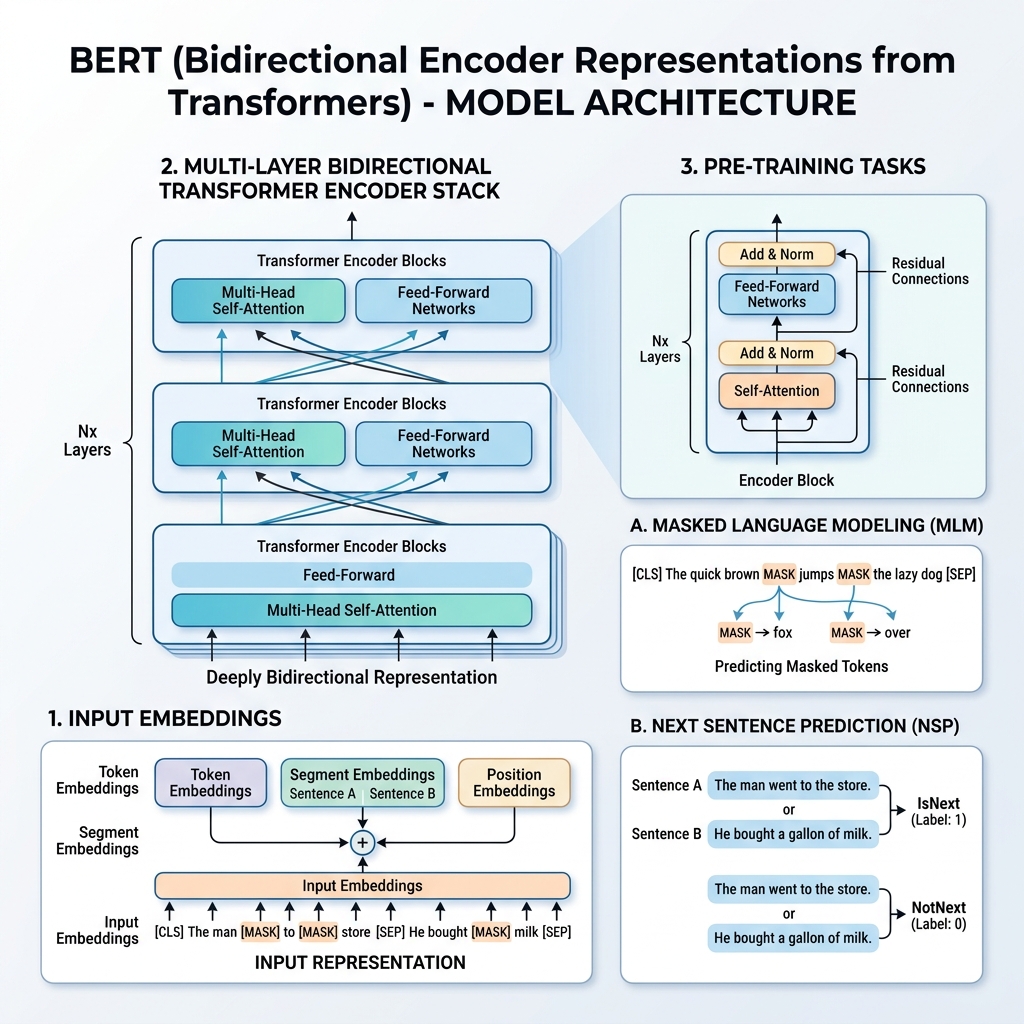
2. ייצוג הקלט של BERT
כדי לאפשר אימון על משימות המשך מרובות, ייצוג הקלט של BERT יכול לייצג הן משפט בודד והן זוג משפטים (למשל, <שאלה, תשובה>) ברצף טוקנים יחיד.
עבור כל טוקן נתון, ייצוג הקלט שלו נבנה על ידי חיבור של שלושה embeddings:
- Token Embeddings: הטקסט מחולק לטוקנים באמצעות אוצר המילים של WordPiece (כ-30,000 טוקנים). מתווספים טוקנים מיוחדים:
[CLS]: מוכנס בתחילת כל רצף. המצב הנסתר הסופי שלו משמש למשימות סיווג.[SEP]: משמש להפרדת משפטים או בסוף רצף.
- Segment Embeddings: embedding נלמד המציין האם טוקן שייך למשפט א’ או למשפט ב'.
- Position Embeddings: וקטורים מיקומיים נלמדים שמתווספים כדי לתת למודל מודעות למיקום הטוקן ברצף (עד 512 טוקנים).
$$\text{Input Representation} = \text{Token Embeddings} + \text{Segment Embeddings} + \text{Position Embeddings}$$
3. תהליך האימון המקדים (Pre-training)
BERT מאומן מראש על קורפוס עצום (ויקיפדיה ו-BooksCorpus) באמצעות שתי משימות לא מונחות בו-זמנית: Masked Language Model (MLM) ו-Next Sentence Prediction (NSP).
משימה 1: Masked Language Model (MLM)
במודל שפה סטנדרטי, חיזוי המילה הבאה מגביל את המודלים לארכיטקטורות משמאל לימין כדי למנוע ממילת היעד “לראות” את עצמה. כדי לאמן ייצוג דו-כיווני עמוק, BERT מסווה באופן אקראי אחוז מסוים מטוקני הקלט ומנבא אותם.
בפרט:
- 15% מטוקני הקלט נבחרים באקראי.
- מתוך אותם טוקנים שנבחרו:
- 80% מוחלפים בטוקן
[MASK]. - 10% מוחלפים במילה אקראית.
- 10% נשמרים ללא שינוי.
- 80% מוחלפים בטוקן
מתכון זה מונע מהמודל להתמקד רק בטוקן [MASK] במהלך הכוונון העדין (מכיוון ש-[MASK] אינו מופיע במהלך הכוונון העדין) ומאלץ אותו לבנות וקטורי ייצוג עבור כל מילה בהקשר שלה.
משימה 2: Next Sentence Prediction (NSP)
משימות המשך רבות (כמו מענה לשאלות והסקה בשפה טבעית) תלויות בהבנת הקשר בין שני משפטים. כדי לאמן את המודל על קשרי משפטים, BERT מאומן מראש על משימת סיווג בינארית:
בעת בחירת משפטים $A$ ו-$B$ לאימון מקדים:
- ב-50% מהזמן, $B$ הוא המשפט הבא בפועל שעוקב אחרי $A$ (מסומן כ-
IsNext). - ב-50% מהזמן, $B$ הוא משפט אקראי מהקורפוס (מסומן כ-
NotNext).
הווקטור הנסתר הסופי של הטוקן [CLS] מועבר לשכבת סיווג כדי לחזות את התווית.
4. כוונון עדין (Fine-Tuning) של BERT
אחד החוזקות הגדולות ביותר של BERT הוא הגמישות שלו. אימון מקדים הוא יקר, אך כוונון עדין הוא זול ומהיר להפליא. על ידי החלפת שכבת הפלט הסופית, ניתן להחיל את BERT על משימות המשך שונות רבות:
- סיווג משפט בודד: (למשל, ניתוח סנטימנט). שימוש בפלט של טוקן
[CLS]. - סיווג זוג משפטים: (למשל, הסקה בשפה טבעית). שימוש בפלט של טוקן
[CLS]. - מענה לשאלות: (למשל, SQuAD). ניבוי טוקני ההתחלה והסיום של התשובה במסמך.
- תיוג משפט בודד: (למשל, זיהוי ישויות מנוהלות - NER). שימוש בייצוג הפלט של כל טוקן בנפרד.
5. מימוש ב-Python/Hugging Face
להלן דוגמה פשוטה ב-Python המדגימה כיצד לטעון מודל BERT מאומן מראש ולחלץ embeddings הקשריים של מילים באמצעות Hugging Face Transformers ו-PyTorch:
import torch
from transformers import BertTokenizer, BertModel
# 1. אתחול טוקנייזר ומודל
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertModel.from_pretrained('bert-base-uncased')
# 2. הגדרת טקסט המכיל את המילה "bank" בשני הקשרים
text_1 = "He deposited money in the bank."
text_2 = "The river bank was muddy."
# 3. טוקניזציה של הקלטים
inputs_1 = tokenizer(text_1, return_tensors="pt")
inputs_2 = tokenizer(text_2, return_tensors="pt")
# 4. מעבר קדימה דרך BERT
with torch.no_grad():
outputs_1 = model(**inputs_1)
outputs_2 = model(**inputs_2)
# 5. חילוץ embeddings של טוקנים
# last_hidden_state shape: [batch_size, sequence_length, hidden_size]
embeddings_1 = outputs_1.last_hidden_state
embeddings_2 = outputs_2.last_hidden_state
# נבדוק את הטוקנים והאינדקסים שלהם
tokens_1 = tokenizer.convert_ids_to_tokens(inputs_1["input_ids"][0])
tokens_2 = tokenizer.convert_ids_to_tokens(inputs_2["input_ids"][0])
# מציאת האינדקס של המילה 'bank'
bank_idx_1 = tokens_1.index("bank")
bank_idx_2 = tokens_2.index("bank")
# קבלת וקטורי ה-embedding עבור המילה 'bank'
bank_emb_1 = embeddings_1[0, bank_idx_1]
bank_emb_2 = embeddings_2[0, bank_idx_2]
# חישוב דמיון קוסינוס
cosine_sim = torch.nn.functional.cosine_similarity(bank_emb_1, bank_emb_2, dim=0)
print("Tokens 1:", tokens_1)
print("Tokens 2:", tokens_2)
print(f"Cosine similarity between both contextual embeddings of 'bank': {cosine_sim.item():.4f}")
6. תצורות מודל BERT
גוגל שחררה שתי תצורות עיקריות של BERT:
| היפר-פרמטר | BERT-Base | BERT-Large |
|---|---|---|
| מספר שכבות ($L$) | 12 | 24 |
| גודל נסתר ($H$) | 768 | 1024 |
| ראשי קשב ($A$) | 12 | 16 |
| סה"כ פרמטרים | 110 מיליון | 340 מיליון |
סיכום
BERT הוכיח כי ייצוגים דו-כיווניים עמוקים המאומנים על טקסט עצום ללא תוויות יכולים ללכוד מבנים תחביריים וסמנטיים מורכבים. הוא קבע פרדיגמה חדשה ללמידת העברה (Transfer Learning) ב-NLP, וביסס את זרימת העבודה של אימון מראש ולאחר מכן כוונון עדין ששלטה בבינה מלאכותית עד לעלייתם של מודלים מבוססי דקודר בלבד (כמו GPT).