Понимание BERT: Двунаправленные представления кодировщика на основе Transformers
В 2018 году исследователи из Google опубликовали революционную статью под названием «BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding» (Devlin et al.). Это исследование фундаментально изменило область обработки естественного языка (NLP). До BERT модели обрабатывали текст последовательно: слева направо или справа налево. BERT представил метод обучения языковых представлений, которые анализируют контекст с обоих направлений одновременно.
Сегодня BERT и его модификации (такие как RoBERTa, DistilBERT и ALBERT) остаются основополагающими для поисковых систем, анализа тональности, систем ответов на вопросы и извлечения информации. В этой статье мы подробно разберем архитектуру BERT, принципы его работы и обучения.
1. Что такое BERT?
BERT расшифровывается как Bidirectional Encoder Representations from Transformers (Двунаправленные представления кодировщика на основе Transformers). Давайте разберем это название:
- Двунаправленный (Bidirectional): В отличие от традиционных языковых моделей, которые читают текст слева направо (как GPT) или справа налево, BERT читает всю последовательность слов одновременно. Это позволяет ему изучать контекст слова на основе всего его окружения (как слева, так и справа).
- Представления кодировщика (Encoder Representations): BERT использует часть Encoder (кодировщик) оригинальной архитектуры Transformer. Он принимает входную последовательность и выдает плотное векторное представление (эмбеддинг) для каждого токена.
- Трансформеры (Transformers): Базовым механизмом является сеть внимания Transformer (Self-Attention), которая позволяет моделировать долгосрочные зависимости и выполнять параллельные вычисления.
Сила двунаправленности
В однонаправленных моделях токен может обращать внимание только на предыдущие токены. Например, в предложении:
«Он решил положить свои деньги в банк».
Если однонаправленная модель обрабатывает слово "банк", она смотрит только на предшествующие слова. Но для полного понимания контекста крайне важно смотреть как на левый, так и на правый контекст. В то время как двунаправленные LSTM пытались решить эту задачу путем обучения отдельных моделей слева направо и справа налево и конкатенации результатов, BERT совместно обучает единую глубоко двунаправленную модель на всех слоях.
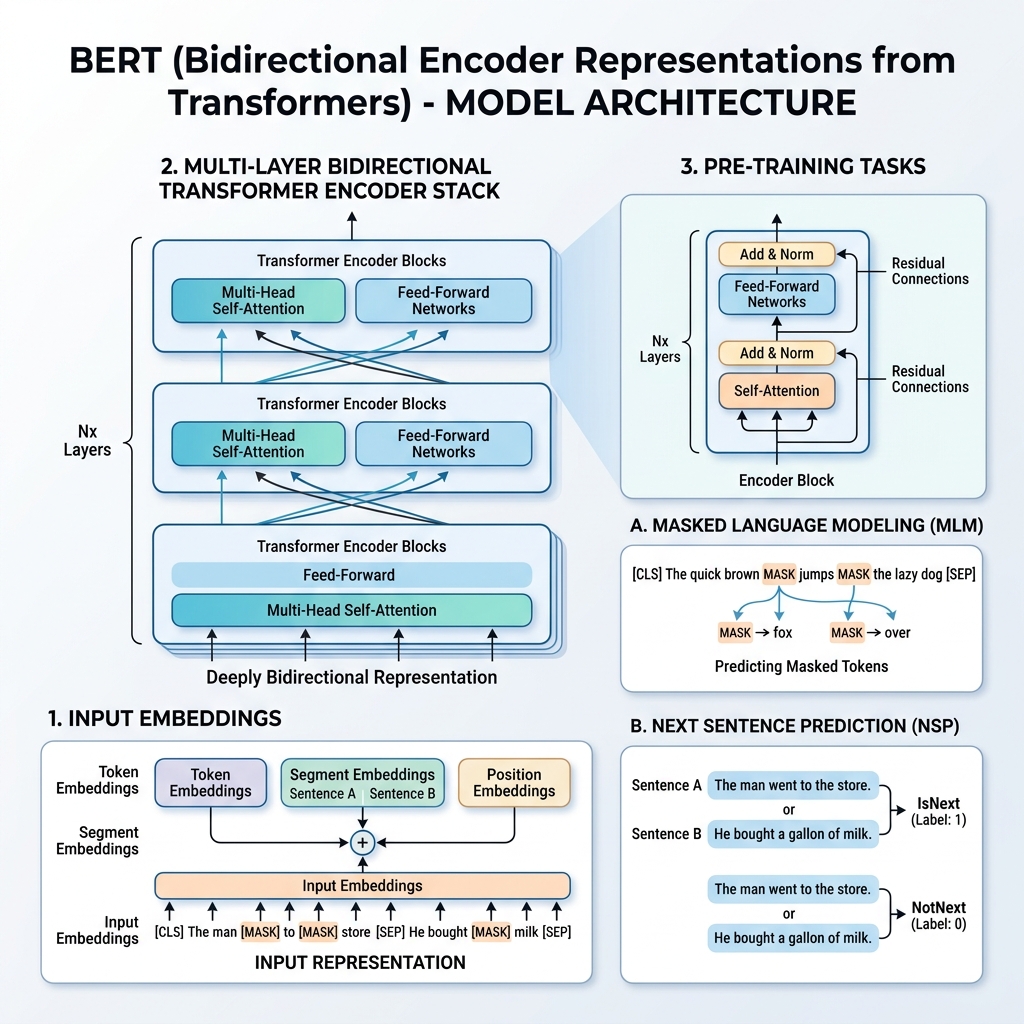
2. Представление входных данных в BERT
Чтобы обеспечить обучение на различных последующих задачах, входное представление BERT может представлять как одно предложение, так и пару предложений (например, <Вопрос, Ответ>) в одной последовательности токенов.
Для любого заданного токена его входное представление строится путем суммирования трех эмбеддингов:
- Эмбеддинги токенов (Token Embeddings): Текст токенизируется с использованием словаря WordPiece (около 30 000 токенов). Добавляются специальные токены:
[CLS]: Вставляется в начале каждой последовательности. Его конечное скрытое состояние используется для задач классификации.[SEP]: Используется для разделения предложений или в конце последовательности.
- Эмбеддинги сегментов (Segment Embeddings): Обучаемый эмбеддинг, указывающий, принадлежит ли токен предложению А или предложению Б.
- Эмбеддинги позиций (Position Embeddings): Обучаемые позиционные векторы, добавляемые для того, чтобы модель знала положение токена в последовательности (до 512 токенов).
$$\text{Входное представление} = \text{Эмбеддинги токенов} + \text{Эмбеддинги сегментов} + \text{Эмбеддинги позиций}$$
3. Процесс предобучения (Pre-training)
BERT предобучается на огромном корпусе текстов (Wikipedia и BooksCorpus) с использованием двух задач обучения без учителя одновременно: Masked Language Model (MLM) (Маскированная языковая модель) и Next Sentence Prediction (NSP) (Предсказание следующего предложения).
Задача 1: Masked Language Model (MLM)
В стандартном языковом моделировании предсказание следующего слова ограничивает модели однонаправленными архитектурами слева направо, чтобы целевое слово не «видело» себя. Для обучения глубокого двунаправленного представления BERT случайным образом маскирует определенный процент входных токенов и предсказывает их.
А именно:
- Случайным образом выбирается 15% входных токенов.
- Из выбранных токенов:
- 80% заменяются токеном
[MASK]. - 10% заменяются случайным словом.
- 10% остаются без изменений.
- 80% заменяются токеном
Эта схема предотвращает концентрацию модели исключительно на токене [MASK] во время тонкой настройки (поскольку [MASK] никогда не появляется при тонкой настройке) и заставляет ее строить векторы представлений для каждого слова в контексте.
Задача 2: Next Sentence Prediction (NSP)
Многие прикладные задачи (такие как ответы на вопросы и логический вывод) зависят от понимания взаимосвязи между двумя предложениями. Чтобы обучить модель понимать эти связи, BERT предобучается на задаче бинарной классификации:
При выборе предложений $A$ и $B$ для предобучения:
- В 50% случаев $B$ является реальным следующим предложением за $A$ (метка
IsNext). - В 50% случаев $B$ является случайным предложением из корпуса (метка
NotNext).
Финальный скрытый вектор токена [CLS] передается классификационному слою для предсказания метки.
4. Тонкая настройка (Fine-Tuning) BERT
Одной из главных сильных сторон BERT является его гибкость. Предобучение стоит дорого, но тонкая настройка выполняется невероятно быстро и дешево. Заменяя финальный выходной слой, BERT можно применять ко многим прикладным задачам:
- Классификация одного предложения: (например, анализ тональности). Используется выход токена
[CLS]. - Классификация пар предложений: (например, логический вывод). Используется выход токена
[CLS]. - Ответы на вопросы: (например, SQuAD). Предсказание начального и конечного токенов ответа в документе.
- Разметка одного предложения: (например, распознавание именованных сущностей - NER). Используется выходное представление каждого отдельного токена.
5. Реализация на Python / Hugging Face
Ниже приведен простой пример на Python, демонстрирующий, как загрузить предобученную модель BERT и извлечь контекстные эмбеддинги слов с помощью Hugging Face Transformers и PyTorch:
import torch
from transformers import BertTokenizer, BertModel
# 1. Инициализация токенизатора и модели
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertModel.from_pretrained('bert-base-uncased')
# 2. Определение текста, содержащего слово "bank" в двух контекстах
text_1 = "He deposited money in the bank."
text_2 = "The river bank was muddy."
# 3. Токенизация входных данных
inputs_1 = tokenizer(text_1, return_tensors="pt")
inputs_2 = tokenizer(text_2, return_tensors="pt")
# 4. Прямой проход через BERT
with torch.no_grad():
outputs_1 = model(**inputs_1)
outputs_2 = model(**inputs_2)
# 5. Извлечение эмбеддингов токенов
# размерность last_hidden_state: [batch_size, sequence_length, hidden_size]
embeddings_1 = outputs_1.last_hidden_state
embeddings_2 = outputs_2.last_hidden_state
# Проверим токены и их индексы
tokens_1 = tokenizer.convert_ids_to_tokens(inputs_1["input_ids"][0])
tokens_2 = tokenizer.convert_ids_to_tokens(inputs_2["input_ids"][0])
# Находим индекс слова 'bank'
bank_idx_1 = tokens_1.index("bank")
bank_idx_2 = tokens_2.index("bank")
# Получаем векторы эмбеддингов для слова 'bank'
bank_emb_1 = embeddings_1[0, bank_idx_1]
bank_emb_2 = embeddings_2[0, bank_idx_2]
# Вычисляем косинусное сходство
cosine_sim = torch.nn.functional.cosine_similarity(bank_emb_1, bank_emb_2, dim=0)
print("Tokens 1:", tokens_1)
print("Tokens 2:", tokens_2)
print(f"Косинусное сходство между контекстными эмбеддингами слова 'bank': {cosine_sim.item():.4f}")
6. Конфигурации модели BERT
Google выпустила две основные конфигурации BERT:
| Гиперпараметр | BERT-Base | BERT-Large |
|---|---|---|
| Количество слоев ($L$) | 12 | 24 |
| Размер скрытого состояния ($H$) | 768 | 1024 |
| Головки внимания ($A$) | 12 | 16 |
| Всего параметров | 110 миллионов | 340 миллионов |
Заключение
BERT доказал, что глубокие двунаправленные представления, обученные на больших неразмеченных текстах, могут улавливать сложные синтаксические и семантические структуры. Он установил новую парадигму для трансферного обучения в NLP, определив рабочий процесс «предобучение — тонкая настройка», который доминировал в ИИ до появления авторегрессионных моделей, состоящих только из декодера (таких как GPT).