فهم نموذج BERT: تمثيلات المشفر ثنائية الاتجاه من المحولات
في عام 2018، نشر باحثو Google ورقة بحثية بارزة بعنوان “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding” (Devlin et al.). لقد غير هذا البحث بشكل جذري مجال معالجة اللغة الطبيعية (NLP). قبل BERT، كانت النماذج تعالج النصوص بشكل متسلسل من اليسار إلى اليمين أو من اليمين إلى اليسار. قدم BERT طريقة لتدريب تمثيلات اللغة التي تنظر إلى السياق من كلا الاتجاهين في وقت واحد.
اليوم، يظل BERT ومشتقاته (مثل RoBERTa و DistilBERT و ALBERT) أساسية لمحركات البحث، وتحليل المشاعر، وأنظمة الإجابة على الأسئلة، واستخراج المعلومات. توضح هذه المقالة بنية BERT، وكيف يعمل، وكيف يتم تدريبه.
1. ما هو BERT؟
يرمز BERT إلى Bidirectional Encoder Representations from Transformers (تمثيلات المشفر ثنائية الاتجاه من المحولات). لنقم بتفكيك هذا الاسم:
- ثنائي الاتجاه (Bidirectional): على عكس نماذج اللغة التقليدية التي تقرأ النص من اليسار إلى اليمين (مثل GPT) أو من اليمين إلى اليسار، يقرأ BERT سلسلة الكلمات بأكملها دفعة واحدة. يتيح له ذلك تعلم سياق الكلمة بناءً على محيطها بالكامل (اليمين واليسار معًا).
- تمثيلات المشفر (Encoder Representations): يستخدم BERT جزء المشفر (Encoder) من بنية المحول (Transformer) الأصلية. يأخذ تسلسل الإدخال ويعطي تمثيلاً متجهًا كثيفًا (embedding) لكل توكن.
- المحولات (Transformers): المحرك الأساسي هو شبكة الانتباه (Attention) للمحول، والتي تمكن من نمذجة الاعتمادات طويلة المدى والحساب المتوازي.
قوة ثنائية الاتجاه
في النماذج أحادية الاتجاه، يمكن للتوكن الانتباه فقط إلى التوكنات السابقة. على سبيل المثال، في الجملة:
"قرر إيداع أمواله في البنك."
إذا قام نموذج أحادي الاتجاه بمعالجة كلمة "البنك"، فإنه ينظر فقط إلى الكلمات التي تسبقها. ولكن لفهم السياق تمامًا، فإن النظر إلى السياق الأيمن والأيسر معًا يعد أمرًا بالغ الأهمية. في حين حاولت نماذج LSTM ثنائية الاتجاه تحقيق ذلك من خلال تدريب نماذج منفصلة من اليسار إلى اليمين ومن اليمين إلى اليسار ودمج المخرجات، فإن BERT يقوم بتدريب نموذج واحد ثنائي الاتجاه بشكل عميق ومستمر عبر جميع الطبقات.
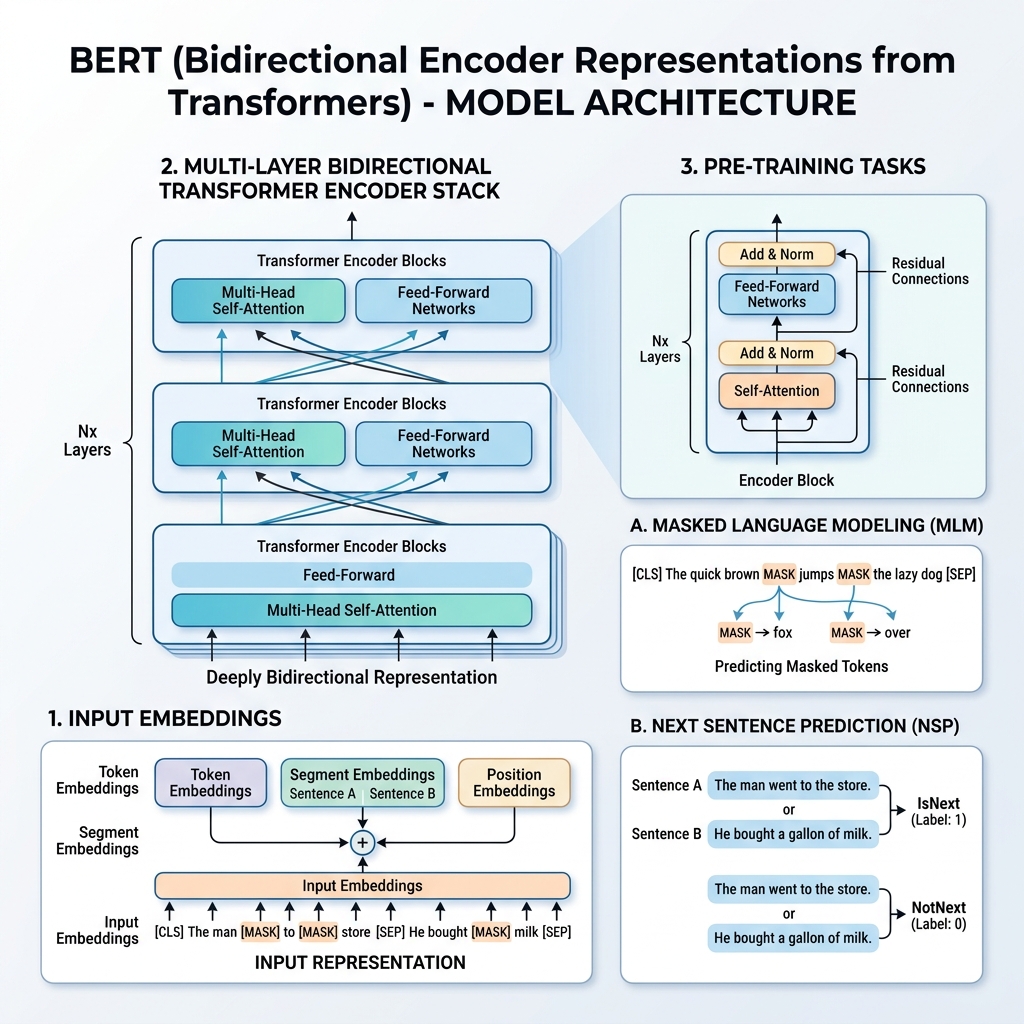
2. تمثيل المدخلات في BERT
لتمكين التدريب على مهام متعددة، يمكن لتمثيل المدخلات في BERT أن يمثل كلاً من جملة واحدة وزوج من الجمل (على سبيل المثال، <السؤال، الإجابة>) في تسلسل توكن واحد.
بالنسبة لأي توكن معين، يتم بناء تمثيل المدخلات الخاص به عن طريق جمع ثلاثة تضمينات (embeddings):
- تضمينات التوكن (Token Embeddings): يتم تقسيم النص إلى توكنات باستخدام قاموس WordPiece (حوالي 30,000 توكن). يتم إضافة توكنات خاصة:
[CLS]: يتم إدراجه في بداية كل تسلسل. يتم استخدام حالته المخفية النهائية لمهام التصنيف.[SEP]: يستخدم للفصل بين الجمل أو في نهاية التسلسل.
- تضمينات الجزء (Segment Embeddings): تضمين متعلم يشير إلى ما إذا كان التوكن ينتمي إلى الجملة A أو الجملة B.
- تضمينات الموضع (Position Embeddings): متجهات موضعية متعلمة يتم إضافتها لإعطاء النموذج وعيًا بموقع التوكن في التسلسل (حتى 512 توكن).
$$\text{Input Representation} = \text{Token Embeddings} + \text{Segment Embeddings} + \text{Position Embeddings}$$
3. عملية التدريب المسبق (Pre-training)
يتم تدريب BERT مسبقًا على مجموعة ضخمة من النصوص (Wikipedia و BooksCorpus) باستخدام مهمتين غير خاضعتين للإشراف في نفس الوقت: نموذج اللغة المقنع (MLM) و التنبؤ بالجملة التالية (NSP).
المهمة 1: نموذج اللغة المقنع (MLM)
في نمذجة اللغة القياسية، فإن التنبؤ بالكلمة التالية يقيد النماذج ببنيات من اليسار إلى اليمين لمنع الكلمة المستهدفة من “رؤية” نفسها. لتدريب تمثيل ثنائي الاتجاه عميق، يقوم BERT بإخفاء نسبة مئوية من توكنات الإدخال بشكل عشوائي والتنبؤ بها.
على وجه التحديد:
- يتم اختيار 15% من توكنات الإدخال بشكل عشوائي.
- من بين تلك التوكنات المختارة:
- 80% يتم استبدالها بتوكن القناع
[MASK]. - 10% يتم استبدالها بكلمة عشوائية.
- 10% يتم الإبقاء عليها دون تغيير.
- 80% يتم استبدالها بتوكن القناع
تمنع هذه الوصفة النموذج من التركيز فقط على توكن [MASK] أثناء الضبط الدقيق (نظرًا لأن توكن القناع لا يظهر أبدًا أثناء الضبط الدقيق) وتجبره على بناء متجهات تمثيل لكل كلمة في السياق.
المهمة 2: التنبؤ بالجملة التالية (NSP)
تعتمد العديد من المهام اللاحقة (مثل الإجابة على الأسئلة والاستدلال اللغوي) على فهم العلاقة بين جملتين. لتدريب النموذج على علاقات الجمل، يتم تدريب BERT مسبقًا على مهمة تصنيف ثنائية:
عند اختيار الجملتين $A$ و $B$ للتدريب المسبق:
- في 50% من الحالات، تكون الجملة $B$ هي الجملة التالية الفعلية التي تلي الجملة $A$ (وتسمى
IsNext). - في 50% من الحالات، تكون الجملة $B$ جملة عشوائية من النصوص (وتسمى
NotNext).
يتم تمرير المتجه المخفي النهائي لتوكن [CLS] إلى طبقة تصنيف للتنبؤ بالتسمية.
4. الضبط الدقيق (Fine-Tuning) لـ BERT
تعد المرونة أحد أكبر نقاط قوة BERT. التدريب المسبق مكلف، لكن الضبط الدقيق رخيص وسريع للغاية. من خلال استبدال طبقة المخرجات النهائية، يمكن تطبيق BERT على العديد من المهام اللاحقة المختلفة:
- تصنيف جملة واحدة: (مثل تحليل المشاعر). استخدم مخرجات توكن
[CLS]. - تصنيف زوج من الجمل: (مثل الاستدلال اللغوي). استخدم مخرجات توكن
[CLS]. - الإجابة على الأسئلة: (مثل SQuAD). توقع توكنات بداية ونهاية الإجابة في المستند.
- تسمية جملة واحدة: (مثل التعرف على الكيانات المسماة). استخدم تمثيل المخرجات لكل توكن على حدة.
5. التنفيذ باستخدام Python / Hugging Face
فيما يلي مثال بسيط بلغة Python يوضح كيفية تحميل نموذج BERT مدرب مسبقًا واستخراج تضمينات الكلمات السياقية باستخدام Hugging Face Transformers و PyTorch:
import torch
from transformers import BertTokenizer, BertModel
# 1. تهيئة المحلل اللغوي والنموذج
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertModel.from_pretrained('bert-base-uncased')
# 2. تحديد النص الذي يحتوي على كلمة "bank" في سياقين مختلفين
text_1 = "He deposited money in the bank."
text_2 = "The river bank was muddy."
# 3. تحليل المدخلات
inputs_1 = tokenizer(text_1, return_tensors="pt")
inputs_2 = tokenizer(text_2, return_tensors="pt")
# 4. التمرير الأمامي عبر BERT
with torch.no_grad():
outputs_1 = model(**inputs_1)
outputs_2 = model(**inputs_2)
# 5. استخراج تضمينات التوكن
# أبعاد last_hidden_state هي [batch_size, sequence_length, hidden_size]
embeddings_1 = outputs_1.last_hidden_state
embeddings_2 = outputs_2.last_hidden_state
# دعنا نفحص التوكنات ومؤشراتها
tokens_1 = tokenizer.convert_ids_to_tokens(inputs_1["input_ids"][0])
tokens_2 = tokenizer.convert_ids_to_tokens(inputs_2["input_ids"][0])
# البحث عن مؤشر كلمة 'bank'
bank_idx_1 = tokens_1.index("bank")
bank_idx_2 = tokens_2.index("bank")
# الحصول على متجهات التضمين لكلمة 'bank'
bank_emb_1 = embeddings_1[0, bank_idx_1]
bank_emb_2 = embeddings_2[0, bank_idx_2]
# حساب تشابه جيب التمام
cosine_sim = torch.nn.functional.cosine_similarity(bank_emb_1, bank_emb_2, dim=0)
print("Tokens 1:", tokens_1)
print("Tokens 2:", tokens_2)
print(f"Cosine similarity between both contextual embeddings of 'bank': {cosine_sim.item():.4f}")
6. تكوينات نموذج BERT
أصدرت Google تكوينين رئيسيين لـ BERT:
| المعلمات الفائقة | BERT-Base | BERT-Large |
|---|---|---|
| عدد الطبقات ($L$) | 12 | 24 |
| الحجم المخفي ($H$) | 768 | 1024 |
| رؤوس الانتباه ($A$) | 12 | 16 |
| إجمالي المعلمات | 110 مليون | 340 مليون |
خاتمة
أثبت BERT أن التمثيلات ثنائية الاتجاه العميقة المدربة على نصوص ضخمة غير مصنفة يمكنها التقاط الهياكل النحوية والدلالية المعقدة. لقد وضع نموذجًا جديدًا للتعلم الانتقالي في معالجة اللغة الطبيعية، مما أدى إلى ترسيخ سير عمل التدريب المسبق ثم الضبط الدقيق الذي هيمن على الذكاء الاصطناعي حتى ظهور النماذج القائمة على فك التشفير فقط (مثل GPT).