BERT'i Anlamak: Transformer'lardan Çift Yönlü Kodlayıcı Temsilleri
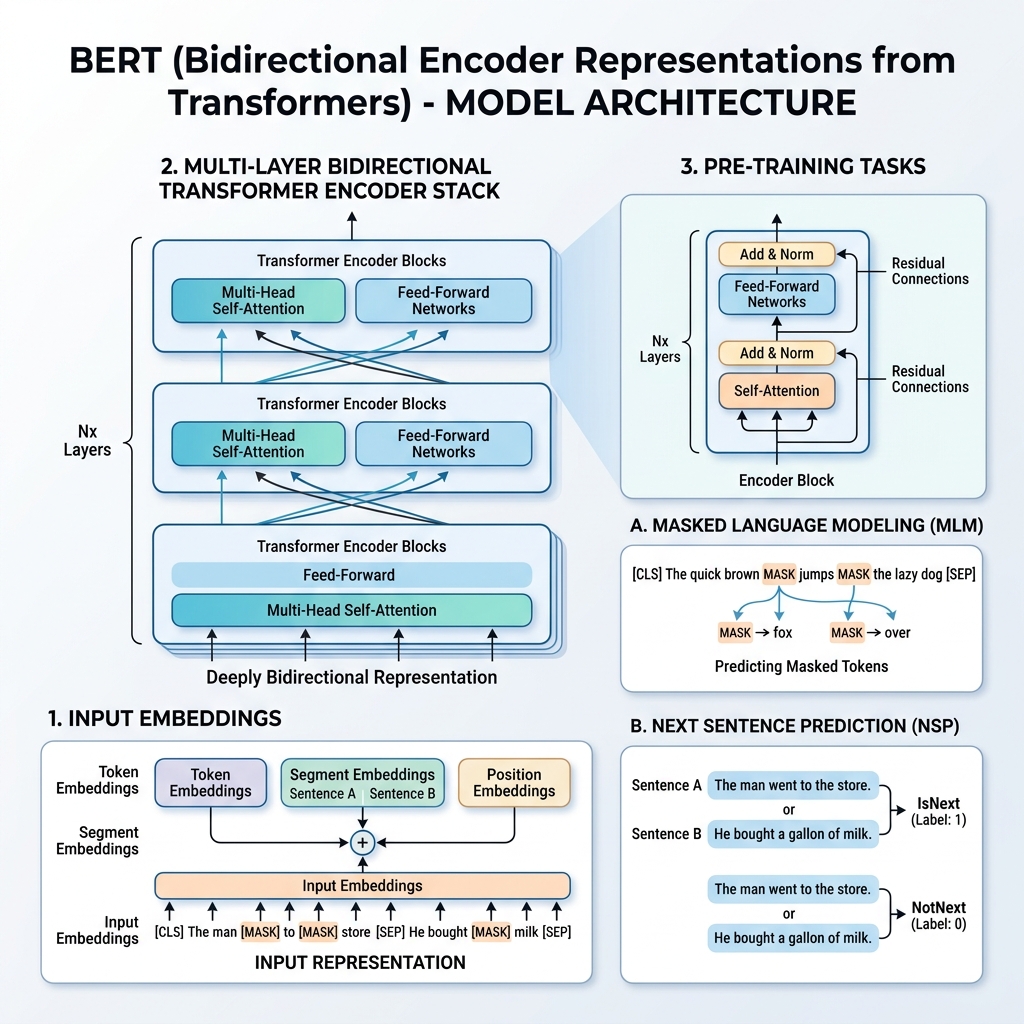
2018 yılında Google araştırmacıları, “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding” (Devlin ve ark.) başlıklı dönüm noktası niteliğinde bir makale yayınladılar. Bu araştırma, Doğal Dil İşleme (NLP) alanını temelden değiştirdi. BERT’ten önce modeller, metni soldan sağa veya sağdan sola sıralı olarak işliyordu. BERT, her iki yöndeki bağlamı aynı anda inceleyen dil temsillerini eğitmek için bir yöntem sundu.
Bugün BERT ve ardılları (RoBERTa, DistilBERT ve ALBERT gibi), arama motorları, duygu analizi, soru-cevap sistemleri ve bilgi çıkarımı için temel oluşturmaya devam ediyor. Bu makale BERT mimarisini, nasıl çalıştığını ve nasıl eğitildiğini açıklamaktadır.
1. BERT Nedir?
BERT, Bidirectional Encoder Representations from Transformers (Transformer’lardan Çift Yönlü Kodlayıcı Temsilleri) anlamına gelir. Bu ismi parçalarına ayıralım:
- Çift Yönlü (Bidirectional): Metni soldan sağa (GPT gibi) veya sağdan sola okuyan geleneksel dil modellerinin aksine, BERT tüm kelime dizisini aynı anda okur. Bu, bir kelimenin bağlamını tüm çevresine (hem soluna hem sağına) göre öğrenmesini sağlar.
- Kodlayıcı Temsilleri (Encoder Representations): BERT, orijinal Transformer mimarisinin Encoder (Kodlayıcı) bölümünü kullanır. Bir giriş dizisi alır ve her token için yoğun bir vektör temsili (embedding) üretir.
- Transformers: Temel motor, uzun menzilli bağımlılıkların modellenmesini ve paralel hesaplamayı sağlayan Transformer dikkat (attention) ağıdır.
Çift Yönlülüğün Gücü
Tek yönlü modellerde bir token yalnızca önceki token’lara dikkat edebilir. Örneğin şu cümlede:
"Parasini bankaya yatirmaya karar verdi."
Tek yönlü bir model "banka" kelimesini işlerken yalnızca kendisinden önceki kelimelere bakar. Ancak bağlamı tam olarak anlamak için hem sol hem de sağ bağlama bakmak çok önemlidir. Çift yönlü LSTM’ler bunu ayrı soldan sağa ve sağdan sola modeller eğitip çıktıları birleştirerek denemiş olsa da, BERT tüm katmanlarda ortaklaşa çalışan tek bir derin çift yönlü modeli eğitir.
2. BERT’in Giriş Temsili
Farklı alt görevlerde eğitime olanak tanımak için BERT’in giriş temsili, tek bir token dizisinde hem tek bir cümleyi hem de bir cümle çiftini (örneğin <Soru, Cevap>) temsil edebilir.
Herhangi bir token için giriş temsili, üç gömmenin (embeddings) toplanmasıyla oluşturulur:
- Token Embeddings: Metin, WordPiece sözlüğü (yaklaşık 30.000 token) kullanılarak token’lara ayrılır. Özel token’lar eklenir:
[CLS]: Her dizinin başına eklenir. Nihai gizli durumu, sınıflandırma görevleri için kullanılır.[SEP]: Cümleleri ayırmak için veya dizinin sonunda kullanılır.
- Segment Embeddings: Bir token’ın Cümle A’ya mı yoksa Cümle B’ye mi ait olduğunu gösteren öğrenilmiş bir gömme.
- Position Embeddings: Token’ın dizideki konumu hakkında modele farkındalık kazandırmak için eklenen öğrenilmiş konumsal vektörler (512 token’a kadar).
$$\text{Giriş Temsili} = \text{Token Embeddings} + \text{Segment Embeddings} + \text{Position Embeddings}$$
3. Ön Eğitim Süreci (Pre-training)
BERT, iki denetimsiz görevi aynı anda kullanarak devasa bir veri kümesi (Wikipedia ve BooksCorpus) üzerinde önceden eğitilir: Maskelenmiş Dil Modeli (MLM) ve Sonraki Cümle Tahmini (NSP).
Görev 1: Maskelenmiş Dil Modeli (MLM)
Standart dil modellemede, bir sonraki kelimeyi tahmin etmek, hedef kelimenin kendisini “görmesini” engellemek için modelleri soldan sağa mimarilerle sınırlar. Derin bir çift yönlü temsil eğitmek için BERT, giriş token’larının belirli bir yüzdesini rastgele maskeler ve bunları tahmin eder.
Özellikle:
- Giriş token’larının %15’i rastgele seçilir.
- Seçilen bu token’ların:
- %80’i
[MASK]token’ı ile değiştirilir. - %10’u rastgele bir kelime ile değiştirilir.
- %10’u değiştirilmeden bırakılır.
- %80’i
Bu yöntem, modelin ince ayar (fine-tuning) sırasında yalnızca [MASK] token’ına odaklanmasını engeller (çünkü ince ayar sırasında [MASK] asla görünmez) ve onu bağlamdaki her kelime için temsil vektörleri oluşturmaya zorlar.
Görev 2: Sonraki Cümle Tahmini (NSP)
Birçok alt görev (Soru Cevaplama ve Doğal Dil Çıkarımı gibi), iki cümle arasındaki ilişkiyi anlamaya dayanır. Modeli cümle ilişkileri konusunda eğitmek için BERT, ikili bir sınıflandırma görevi üzerinde önceden eğitilir:
Ön eğitim için $A$ ve $B$ cümleleri seçilirken:
- Zamanın %50’sinde, $B$ cümlesi gerçekten $A$‘dan sonra gelen bir sonraki cümledir (
IsNextolarak etiketlenir). - Zamanın %50’sinde, $B$ cümlesi veri kümesinden rastgele seçilmiş bir cümledir (
NotNextolarak etiketlenir).
Etiketi tahmin etmek için [CLS] token’ının nihai gizli vektörü bir sınıflandırma katmanına aktarılır.
4. BERT İnce Ayarı (Fine-Tuning)
BERT’in en büyük güçlerinden biri esnekliğidir. Ön eğitim pahalıdır, ancak ince ayar inanılmaz derecede ucuz ve hızlıdır. Nihai çıktı katmanını değiştirerek, BERT birçok farklı alt göreve uygulanabilir:
- Tek Cümle Sınıflandırması: (örneğin duygu analizi).
[CLS]token çıktısını kullanın. - Cümle Çifti Sınıflandırması: (örneğin doğal dil çıkarımı).
[CLS]token çıktısını kullanın. - Soru Cevaplama: (örneğin SQuAD). Belgedeki cevap başlangıç ve bitiş token’larını tahmin edin.
- Tek Cümle Etiketleme: (örneğin Adlandırılmış Varlık Tanıma - NER). Her bir token’ın çıktı temsilini kullanın.
5. Python/Hugging Face Uygulaması
Aşağıda, önceden eğitilmiş bir BERT modelinin nasıl yükleneceğini ve Hugging Face Transformers ile PyTorch kullanılarak bağlamsal kelime gömmelerinin nasıl çıkarılacağını gösteren basit bir Python örneği verilmiştir:
import torch
from transformers import BertTokenizer, BertModel
# 1. Tokenizer ve modeli başlatın
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertModel.from_pretrained('bert-base-uncased')
# 2. "bank" kelimesini iki farklı bağlamda içeren metni tanımlayın
text_1 = "He deposited money in the bank."
text_2 = "The river bank was muddy."
# 3. Girişleri token'lara ayırın
inputs_1 = tokenizer(text_1, return_tensors="pt")
inputs_2 = tokenizer(text_2, return_tensors="pt")
# 4. BERT üzerinden ileri geçiş yapın
with torch.no_grad():
outputs_1 = model(**inputs_1)
outputs_2 = model(**inputs_2)
# 5. Token gömmelerini çıkarın
# last_hidden_state boyutu: [batch_size, sequence_length, hidden_size]
embeddings_1 = outputs_1.last_hidden_state
embeddings_2 = outputs_2.last_hidden_state
# Token'ları ve indekslerini inceleyelim
tokens_1 = tokenizer.convert_ids_to_tokens(inputs_1["input_ids"][0])
tokens_2 = tokenizer.convert_ids_to_tokens(inputs_2["input_ids"][0])
# 'bank' kelimesinin indeksini bulun
bank_idx_1 = tokens_1.index("bank")
bank_idx_2 = tokens_2.index("bank")
# 'bank' kelimesi için gömme vektörlerini alın
bank_emb_1 = embeddings_1[0, bank_idx_1]
bank_emb_2 = embeddings_2[0, bank_idx_2]
# Kosinüs benzerliğini hesaplayın
cosine_sim = torch.nn.functional.cosine_similarity(bank_emb_1, bank_emb_2, dim=0)
print("Tokens 1:", tokens_1)
print("Tokens 2:", tokens_2)
print(f"Her iki bağlamsal 'bank' gömmesi arasındaki kosinüs benzerliği: {cosine_sim.item():.4f}")
6. BERT Model Yapılandırmaları
Google, BERT’in iki ana yapılandırmasını yayınladı:
| Hiperparametre | BERT-Base | BERT-Large |
|---|---|---|
| Katman Sayısı ($L$) | 12 | 24 |
| Gizli Durum Boyutu ($H$) | 768 | 1024 |
| Dikkat Başlıkları ($A$) | 12 | 16 |
| Toplam Parametre | 110 Milyon | 340 Milyon |
Sonuç
BERT, etiketlenmemiş büyük metinler üzerinde eğitilen derin çift yönlü temsillerin karmaşık sözdizimsel ve anlamsal yapıları yakalayabildiğini kanıtladı. Doğal dil işlemede transfer öğrenimi için yeni bir paradigma belirledi ve yapay zekada autoregressive modellerin (GPT gibi) yükselişine kadar hakim olan ön eğitim ve ardından ince ayar iş akışını oluşturdu.