アラビア語の感情分析:実践的なNLP前処理とモデルのウォークスルー

グローバル化したデジタルコミュニケーションの時代において、テキストの背後にある感情的なトーンを特定するタスクである「感情分析」は、企業、政府、研究者にとって不可欠なものとなっています。英語などの言語では感情分析は非常に成熟していますが、これをアラビア語に適用するには、言語的および技術的な独自の課題が存在します。
4億人以上の話者を抱えるアラビア語は、世界で最も広く話されている言語の一つです。しかし、その豊かな形態構造、ダイグロッシア(標準語と口語の共存)、そして複雑な文字システムには、専門的な前処理とモデリング戦略が必要です。
このガイドでは、アラビア語の感情分析の包括的なウォークスルーを提供し、課題、前処理パイプライン、古典的な機械学習の実装(TF-IDF + ロジスティック回帰)、およびHugging FaceのTransformersを使用した現代的なディープラーニングアプローチについて詳しく説明します。
1. アラビア語NLPの言語的課題
コードを書く前に、開発者はなぜアラビア語を標準的な西洋のNLPパイプラインで処理できないのかを理解する必要があります。
- ダイグロッシア(二重言語状態): アラビア語は、書き言葉やニュース、公式文書で使用される**現代標準アラビア語(MSA)と、SNSや日常会話で使用される口語方言(ダリジャ/アンミーヤ)**に分かれています。方言(例:エジプト、レバント、湾岸方言)は、語彙、文法、感情表現において大きく異なります。
- 豊かな形態論: アラビア語は語根ベースの言語であり、パターンを適用することにより、3文字または4文字の語根から単語が派生します。単一の単語に、代名詞、前置詞、時制を表す接頭辞、接尾辞、接中辞が含まれることがあります(例:وسيكتبونها - 「そして彼らはそれを書くでしょう」)。
- 表記の揺れ: アラビア語の文字は位置によって形が変わることが多く、ユーザーは特定の文字を互換的に使用することがよくあります(例:
أ、إ、آ、اなどのアリフの形状や、ىに対するيなどのヤーの形状)。 - シャクル(記号): 短母音は、文字の上または下に付く補助記号(ファトハ、ダンマ、カスラなど)として書かれます。これらは意味を明確にしますが、デジタルテキストでは省略されることが多く、曖昧さの原因となったり、不整合に追加されてデータの希薄化を招いたりします。
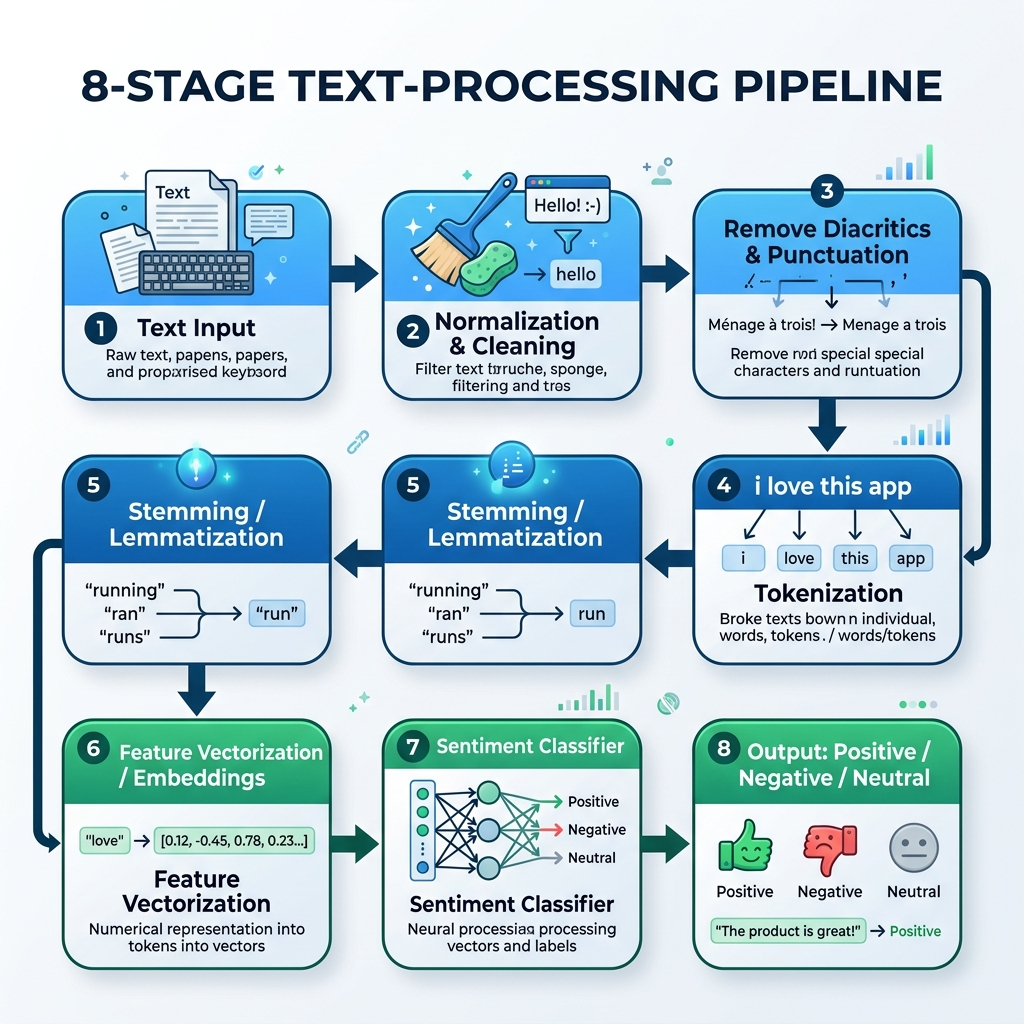
2. アラビア語NLPパイプライン
アラビア語テキストを処理するには、正規化、記号の除去、トークン化、ステミング(語幹抽出)、モデル推論を処理する専用のパイプラインを構築する必要があります。
graph TD
A[生のアラビア語テキスト] --> B[正規化とクリーニング]
B --> C[記号と句読点の削除]
C --> D[トークン化]
D --> E[ステミング / レマタイゼーション]
E --> F[特徴量のベクトル化 / 埋め込み]
F --> G[感情分類器]
G --> H[出力:ポジティブ / ネガティブ / ニュートラル]
3. ウォークスルー:古典的な前処理と機械学習(Python)
Python、NLTK、およびscikit-learnを使用して完全なパイプラインを実装してみましょう。カスタムの正規化ルールを記述し、NLTKのISRIStemmer(アラビア語専用に設計された情報検索用ステマー)を使用します。
ステップ1:依存関係のインストール
まず、必要なライブラリがインストールされていることを確認します。
pip install nltk scikit-learn
ステップ2:前処理コードの記述
以下は、アラビア語テキストをクリーニング、正規化、およびステミングするためのPythonコードです。
import re
import nltk
from nltk.stem.isri import ISRIStemmer
# まだダウンロードしていない場合はストップワードをダウンロード
nltk.download('stopwords', quiet=True)
from nltk.corpus import stopwords
# アラビア語ステマーの初期化
stemmer = ISRIStemmer()
arabic_stopwords = set(stopwords.words('arabic'))
def normalize_arabic(text):
# 1. シャクル(母音記号)の削除
text = re.sub(r'[ً-ْ]', '', text)
# 2. アリフの形状を標準のアリフに正規化
text = re.sub(r'[أإآ]', 'ا', text)
# 3. ヤーとアリフ・マクスーラを正規化
text = re.sub(r'ى', 'ي', text)
# 4. ター・マルブータをハーに正規化
text = re.sub(r'ة', 'ه', text)
# 5. アラビア語以外の文字と句読点を削除
text = re.sub(r'[^ء-ي\s]', ' ', text)
# 6. 連続する空白を1つにまとめる
text = re.sub(r'\s+', ' ', text).strip()
return text
def preprocess_arabic_text(text):
# テキストの正規化
normalized = normalize_arabic(text)
# トークン化してストップワードを除去し、ステミングを実行
words = normalized.split()
processed_words = [stemmer.stem(word) for word in words if word not in arabic_stopwords]
return " ".join(processed_words)
# 使用例
raw_text = "الخدمةُ كانت ممتازةً وسريعةً جداً! أنصح الجميع بالتعامل معهم."
print("オリジナル:", raw_text)
print("処理後:", preprocess_arabic_text(raw_text))
# 出力: ممتاز سرع نصح جمع عمل مع
ステップ3:シンプルな分類器の訓練
次に、TF-IDFを使用して処理されたテキストをベクトル化し、ロジスティック回帰モデルを訓練します。
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import Pipeline
# サンプル訓練データ
train_sentences = [
"المنتج رائع جدا وأنصح بشرائه",
"التوصيل كان بطيئا والخدمة سيئة للغاية",
"أعجبني التطبيق وسهل الاستخدام",
"تجربة سيئة جدا ولا أنصح به أبدا",
"خدمة العملاء كانت متعاونة وممتازة"
]
# ラベル:1 = ポジティブ、0 = ネガティブ
train_labels = [1, 0, 1, 0, 1]
# 訓練データの前処理
preprocessed_train = [preprocess_arabic_text(s) for s in train_sentences]
# パイプラインの作成:TF-IDFベクトル化 + ロジスティック回帰分類器
model_pipeline = Pipeline([
('tfidf', TfidfVectorizer()),
('clf', LogisticRegression())
])
# モデルの訓練
model_pipeline.fit(preprocessed_train, train_labels)
# 新しいテキストでテスト
test_text = "التطبيق سيئ للغاية ولا يعمل بشكل صحيح"
preprocessed_test = preprocess_arabic_text(test_text)
prediction = model_pipeline.predict([preprocessed_test])[0]
print(f"テストテキスト: '{test_text}'")
print(f"前処理後: '{preprocessed_test}'")
print(f"予測された感情: {'ポジティブ' if prediction == 1 else 'ネガティブ'}")
4. ウォークスルー:最新のTransformerベースの分類(Hugging Face)
ステミングやTF-IDFは基本的な分類には有効ですが、文脈や皮肉、複雑な方言の揺れを捉えることはできません。最先端の精度を得るには、AraBERTやCamelBERTなどの事前学習済みTransformerを使用します。
以下は、Hugging Faceのtransformersライブラリを使用して、わずか数行のコードでアラビア語テキストの感情分析を実行する方法です。
ステップ1:依存関係のインストール
pip install transformers torch sentencepiece
ステップ2:モデルパイプラインの読み込み
Hugging Face Hubで公開されている、高度に最適化されたCAMeL-Lab/bert-base-arabic-sentiment-msaモデルを使用します。
from transformers import pipeline
# 特化したアラビア語モデルで感情分析パイプラインを初期化
arabic_sentiment_analyzer = pipeline(
"sentiment-analysis",
model="CAMeL-Lab/bert-base-arabic-sentiment-msa"
)
# テスト文(標準語と方言)
sentences = [
"أنا سعيد جداً باستخدام هذا المنتج الرائع",
"الفيلم كان مملاً والقصة غير مترابطة على الإطلاق"
]
results = arabic_sentiment_analyzer(sentences)
for sentence, result in zip(sentences, results):
label = result['label']
confidence = result['score'] * 100
print(f"テキスト: {sentence}")
print(f"感情: {label} (信頼度 {confidence:.2f}%)
")
5. モデル比較:伝統的な機械学習 vs Transformers
| 特徴 | 伝統的機械学習 (TF-IDF + SVM/LR) | Transformers (AraBERT/CamelBERT) |
|---|---|---|
| 文脈の理解 | 低(単語を独立した特徴量として扱う) | 高(単語の順序と文脈を理解する) |
| 方言への対応 | 不十分(カスタムの方言辞書が必要) | 優秀(複雑な方言を自然に処理できる) |
| 計算リソース要件 | 極めて低(CPU上で数ミリ秒で実行可能) | 高(高速な推論にはGPUが必要) |
| 必要な訓練データ | 高(汎化には大規模なラベル付きデータが必要) | 低(事前学習済みのため、微調整で十分機能する) |
| 未知語 (OOV) への対応 | 新しい単語を見落とすリスクが高い | 最小限のリスク(サブワードトークン化を使用) |
6. まとめ
アラビア語の感情分析は急速に進化している分野です。正規化やステミングなどのカスタム前処理を施した従来の機械学習手法は、単純なタスクに対して高速かつコスト効率が良い一方、現代のTransformerは精度と方言処理において新しい基準を打ち立てました。
適切な言語クレンジングルールと適切なモデルアーキテクチャを組み合わせることで、アラビア語圏の感情の声を解き明かす強力なシステムを構築することができます。