عربی سینٹیمنٹ تجزیہ: این ایل پی پری پروسیسنگ اور ماڈل گائیڈ

ڈیجیٹل مواصلات کے اس دور میں، سینٹیمنٹ تجزیہ (کسی تحریر کے پیچھے چھپے ہوئے جذباتی لہجے کی شناخت کرنا) کاروباروں، حکومتوں اور محققین کے لیے انتہائی اہم ہو چکا ہے۔ اور اگرچہ انگریزی جیسی زبانوں کے لیے سینٹیمنٹ تجزیہ بہت زیادہ ترقی کر چکا ہے، لیکن عربی زبان پر اس کا اطلاق لسانی اور تکنیکی چیلنجوں کا ایک انوکھا مجموعہ پیش کرتا ہے۔
دنیا بھر میں 40 کروڑ سے زیادہ بولنے والوں کے ساتھ، عربی دنیا کی سب سے زیادہ بولی جانے والی زبانوں میں سے ایک ہے۔ تاہم، اس کی بھرپور صرفی ساخت (Morphology)، ذولسانیت (ادبی اور بول چال کی زبان کا بیک وقت وجود)، اور پیچیدہ تحریری نظام کے لیے مخصوص پری پروسیسنگ اور ماڈلنگ کی حکمت عملیوں کی ضرورت ہوتی ہے۔
یہ گائیڈ عربی سینٹیمنٹ تجزیہ کا ایک جامع خاکہ پیش کرتی ہے، جس میں چیلنجز، پری پروسیسنگ پائپ لائن، مشین لرننگ کے روایتی طریقے (TF-IDF + لاجسٹک ریگریشن) اور ہگنگ فیس ٹرانسفارمرز کا استعمال کرتے ہوئے جدید ڈیپ لرننگ کے طریقے کی تفصیلات شامل ہیں۔
1. عربی این ایل پی کے لسانی چیلنجز
کوڈ لکھنے سے پہلے، ایک ڈویلپر کو یہ سمجھنا چاہیے کہ عربی کو معیاری مغربی این ایل پی پائپ لائنز کے ساتھ کیوں پروسیس نہیں کیا جا سکتا:
- ذولسانیت (Diglossia): عربی زبان جدید معیاری عربی (MSA) (جو رسمی تحریر، خبروں اور سرکاری دستاویزات میں استعمال ہوتی ہے) اور عام بول چال کے لہجوں (Darja/Ammiya) (جو سوشل میڈیا اور روزمرہ کی گفتگو میں استعمال ہوتے ہیں) کے درمیان تقسیم ہے۔ مختلف لہجے (جیسے مصری، شامی، خلیجی) الفاظ، گرامر اور جذبات کے اظہار میں نمایاں طور پر مختلف ہوتے ہیں۔
- امیر صرفی ساخت (Rich Morphology): عربی ایک جڑ پر مبنی زبان ہے جہاں الفاظ تین یا چار حرفی مادے سے پیٹرن کا اطلاق کر کے اخذ کیے جاتے ہیں۔ ایک ہی لفظ میں سابقے (prefixes)، لاحقے (suffixes) اور درمیانی حروف شامل ہو سکتے ہیں جو ضمیروں، حروف جار اور زمانوں کی نمائندگی کرتے ہیں (مثال کے طور پر: وسيكتبونها - “اور وہ اسے لکھیں گے”)۔
- املا کی تبدیلیاں: عربی حروف اکثر لفظ میں اپنی پوزیشن کے لحاظ سے اپنی شکل بدلتے ہیں، اور صارفین اکثر کچھ حروف کو ایک دوسرے کی جگہ استعمال کرتے ہیں (مثال کے طور پر، الف کی مختلف شکلیں جیسے
أ،إ،آ،ایا یاء کی شکلیں جیسےيبمقابلہى)۔ - اعراب (حرکات): عربی میں چھوٹی آوازوں کو اعراب (زیر، زبر، پیش) کے طور پر حروف کے اوپر یا نیچے لکھا جاتا ہے۔ اگرچہ یہ معنی کو واضح کرتے ہیں، لیکن ڈیجیٹل تحریروں میں انہیں اکثر چھوڑ دیا جاتا ہے، جس سے ابہام پیدا ہوتا ہے۔
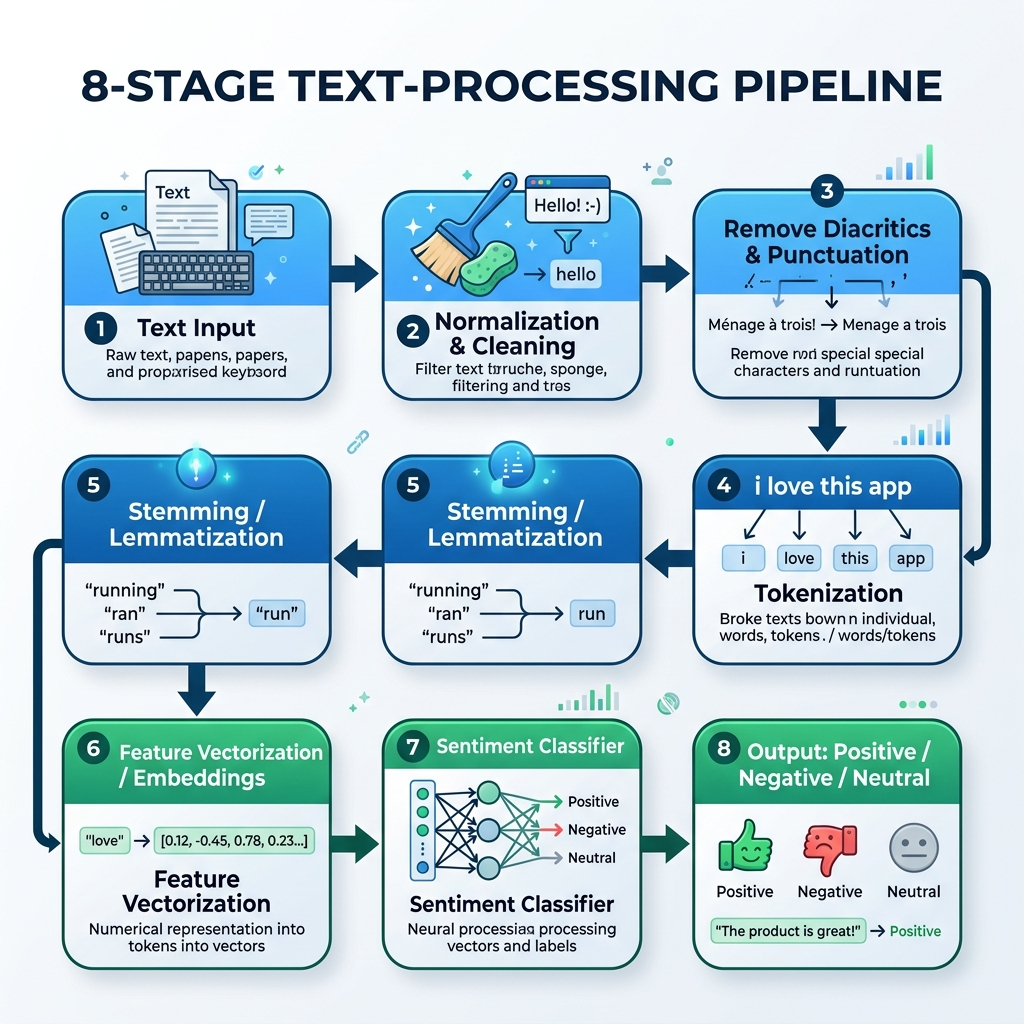
2. عربی این ایل پی پائپ لائن
عربی تحریر کو پروسیس کرنے کے لیے، ہمیں ایک مخصوص پائپ لائن بنانی ہوگی جو نارملائزیشن، اعراب کے خاتمے، ٹوکنائزیشن، سٹیمنگ (جڑ نکالنے) اور ماڈل کی پیشن گوئی کو سنبھالے:
graph TD
A[خام عربی تحریر] --> B[نارملائزیشن اور صفائی]
B --> C[اعراب اور اوقاف کا خاتمہ]
C --> D[ٹوکنائزیشن]
D --> E[سٹیمنگ / لیماٹائزیشن]
E --> F[خصوصیات کی ویکٹرائزیشن / ایمبیڈنگز]
F --> G[سینٹیمنٹ کلاسیفائر]
G --> H[آؤٹ پٹ: مثبت / منفی / نیوٹرل]
3. عملی گائیڈ: روایتی پری پروسیسنگ اور مشین لرننگ (پائیتھن)
آئیے پائیتھن، NLTK، اور scikit-learn کا استعمال کرتے ہوئے ایک مکمل پائپ لائن بنائیں۔ ہم کسٹم نارملائزیشن کے اصول لکھیں گے اور NLTK کا ISRIStemmer استعمال کریں گے (جو عربی کے لیے ڈیزائن کیا گیا سٹیمر ہے)۔
مرحلہ 1: لائبریریاں انسٹال کریں
سب سے پہلے، یقینی بنائیں کہ آپ کے پاس مطلوبہ لائبریریاں انسٹال ہیں:
pip install nltk scikit-learn
مرحلہ 2: پری پروسیسنگ کوڈ لکھیں
عربی ٹیکسٹ کو صاف، نارملائز اور سٹیم کرنے کا پائیتھن کوڈ درج ذیل ہے:
import re
import nltk
from nltk.stem.isri import ISRIStemmer
# اگر پہلے سے ڈاؤن لوڈ نہیں کیا تو سٹاپ ورڈز ڈاؤن لوڈ کریں
nltk.download('stopwords', quiet=True)
from nltk.corpus import stopwords
# عربی سٹیمر کو شروع کریں
stemmer = ISRIStemmer()
arabic_stopwords = set(stopwords.words('arabic'))
def normalize_arabic(text):
# 1. اعراب (تشکیل) کو ختم کریں
text = re.sub(r'[ً-ْ]', '', text)
# 2. الف کی تمام شکلوں کو سادہ الف میں تبدیل کریں
text = re.sub(r'[أإآ]', 'ا', text)
# 3. یاء اور الف مقصورہ کو یکساں کریں
text = re.sub(r'ى', 'ي', text)
# 4. تاء مربوطہ کو ہاء میں تبدیل کریں
text = re.sub(r'ة', 'ه', text)
# 5. غیر عربی حروف اور اوقاف کو ختم کریں
text = re.sub(r'[^ء-ي\s]', ' ', text)
# 6. اضافی خالی جگہوں کو ختم کریں
text = re.sub(r'\s+', ' ', text).strip()
return text
def preprocess_arabic_text(text):
# ٹیکسٹ نارملائز کریں
normalized = normalize_arabic(text)
# ٹوکن بنائیں، سٹاپ ورڈز ختم کریں اور سٹیمنگ کریں
words = normalized.split()
processed_words = [stemmer.stem(word) for word in words if word not in arabic_stopwords]
return " ".join(processed_words)
# استعمال کی مثال
raw_text = "الخدمةُ كانت ممتازةً وسريعةً جداً! أنصح الجميع بالتعامل معهم."
print("اصل تحریر:", raw_text)
print("پروسیس شدہ تحریر:", preprocess_arabic_text(raw_text))
# آؤٹ پٹ: ممتاز سرع نصح جمع عمل مع
مرحلہ 3: ایک سادہ کلاسیفائر کو ٹرین کریں
اب، ہم اپنے پروسیس شدہ ٹیکسٹ کو TF-IDF کے ذریعے ویکٹرائز کریں گے اور لاجسٹک ریگریشن ماڈل کو ٹرین کریں گے:
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import Pipeline
# ٹریننگ ڈیٹا کی مثال
train_sentences = [
"المنتج رائع جدا وأنصح بشرائه",
"التوصيل كان بطيئا والخدمة سيئة للغاية",
"أعجبني التطبيق وسهل الاستخدام",
"تجربة سيئة جدا ولا أنصح به أبدا",
"خدمة العملاء كانت متعاونة وممتازة"
]
# لیبلز: 1 = مثبت، 0 = منفی
train_labels = [1, 0, 1, 0, 1]
# ٹریننگ ڈیٹا کو پری پروسیس کریں
preprocessed_train = [preprocess_arabic_text(s) for s in train_sentences]
# پائپ لائن بنائیں: TF-IDF ویکٹرائزر + لاجسٹک ریگریشن کلاسیفائر
model_pipeline = Pipeline([
('tfidf', TfidfVectorizer()),
('clf', LogisticRegression())
])
# ماڈل کو ٹرین کریں
model_pipeline.fit(preprocessed_train, train_labels)
# نئے ٹیکسٹ کے ساتھ ٹیسٹ کریں
test_text = "التطبيق سيئ للغاية ولا يعمل بشكل صحيح"
preprocessed_test = preprocess_arabic_text(test_text)
prediction = model_pipeline.predict([preprocessed_test])[0]
print(f"ٹیسٹ تحریر: '{test_text}'")
print(f"پری پروسیس شدہ: '{preprocessed_test}'")
print(f"پیش گوئی کردہ جذبہ: {'مثبت' if prediction == 1 else 'منفی'}")
4. عملی گائیڈ: جدید ٹرانسفارمر پر مبنی کلاسیفیکیشن (ہگنگ فیس)
اگرچہ سٹیمنگ اور TF-IDF بنیادی درجہ بندی کے لیے اچھے کام کرتے ہیں، لیکن وہ سیاق و سباق، طنز اور پیچیدہ لہجوں کو سمجھنے میں ناکام رہتے ہیں۔ بہترین نتائج کے لیے، ہم پہلے سے ٹرین شدہ ٹرانسفارمرز جیسے AraBERT یا CamelBERT کا استعمال کرتے ہیں۔
یہاں بتایا گیا ہے کہ آپ عربی ٹیکسٹ پر صرف چند لائنوں کے کوڈ میں سینٹیمنٹ تجزیہ کرنے کے لیے ہگنگ فیس کی transformers لائبریری کو کیسے استعمال کر سکتے ہیں:
مرحلہ 1: لائبریریاں انسٹال کریں
pip install transformers torch sentencepiece
مرحلہ 2: ماڈل پائپ لائن لوڈ کریں
ہم ہگنگ فیس ہب پر موجود انتہائی بہتر ماڈل CAMeL-Lab/bert-base-arabic-sentiment-msa استعمال کریں گے:
from transformers import pipeline
# مخصوص عربی ماڈل کے ساتھ سینٹیمنٹ تجزیہ کی پائپ لائن شروع کریں
arabic_sentiment_analyzer = pipeline(
"sentiment-analysis",
model="CAMeL-Lab/bert-base-arabic-sentiment-msa"
)
# ٹیسٹ جملے (ادبی اور بول چال)
sentences = [
"أنا سعيد جداً باستخدام هذا المنتج الرائع",
"الفيلم كان مملاً والقصة غير مترابطة على الإطلاق"
]
results = arabic_sentiment_analyzer(sentences)
for sentence, result in zip(sentences, results):
label = result['label']
confidence = result['score'] * 100
print(f"جملہ: {sentence}")
print(f"جذبہ: {label} ({confidence:.2f}% یقین کے ساتھ)
")
5. ماڈلز کا موازنہ: روایتی کلاسیفیکیشن بمقابلہ ٹرانسفارمرز
| خصوصیت | روایتی کلاسیفیکیشن (TF-IDF + SVM/LR) | ٹرانسفارمرز (AraBERT/CamelBERT) |
|---|---|---|
| سیاق و سباق کی سمجھ | کم (الفاظ کو آزاد خصوصیات کے طور پر لیتا ہے) | زیادہ (لفظوں کی ترتیب اور سیاق و سباق کو سمجھتا ہے) |
| لہجوں کو سنبھالنا | کمزور (مخصوص لغات کی ضرورت ہوتی ہے) | بہترین (پیچیدہ لہجوں کو قدرتی طور پر سنبھالتا ہے) |
| کمپیوٹنگ کی ضروریات | انتہائی کم (کسی بھی CPU پر ملی سیکنڈ میں چلتا ہے) | زیادہ (تیز کام کے لیے GPU کی ضرورت ہوتی ہے) |
| ٹریننگ ڈیٹا کی ضرورت | زیادہ (عام کرنے کے لیے بڑے ڈیٹا سیٹس درکار ہیں) | کم (پہلے سے ٹرینڈ، فائن ٹیوننگ کے ساتھ اچھا کام کرتا ہے) |
| نامعلوم الفاظ (OOV) | نئے الفاظ کے چھوٹ جانے کا زیادہ خطرہ | نہ ہونے کے برابر خطرہ (ذیلی الفاظ کی ٹوکنائزیشن استعمال کرتا ہے) |
6. نتیجہ
عربی سینٹیمنٹ تجزیہ ایک تیزی سے ترقی کرتا ہوا شعبہ ہے۔ اگرچہ کسٹم پری پروسیسنگ (جیسے نارملائزیشن اور سٹیمنگ) کے ساتھ روایتی مشین لرننگ تکنیکیں آسان کاموں کے لیے تیز اور کم لاگت ہیں، لیکن جدید ٹرانسفارمرز نے درستگی اور لہجوں کو سنبھالنے کے لیے ایک نیا معیار قائم کیا ہے۔
صحیح لسانی اصولوں کو مناسب ماڈل آرکیٹیکچر کے ساتھ ملا کر، آپ ایسے طاقتور سسٹم بنا سکتے ہیں جو عرب دنیا کے جذباتی لہجے کو سمجھ سکتے ہیں۔
غزنکس بلاگ پر اے آئی اور این ایل پی کے بارے میں مزید معلومات حاصل کریں →