ניתוח סנטימנט בערבית: מדריך מעשי לעיבוד מקדים ומידול NLP

בעידן התקשורת הדיגיטלית הגלובלית, ניתוח סנטימנט (התפקיד של זיהוי הטון הרגשי מאחורי טקסט) הפך לקריטי עבור עסקים, ממשלות וחוקרים. בעוד שניתוח סנטימנט הוא תחום בוגר מאוד עבור שפות כמו אנגלית, יישומו על השפה הערבית מציג סט ייחודי של אתגרים בלשניים וטכנולוגיים.
עם למעלה מ-400 מיליון דוברים, ערבית היא אחת השפות המדוברות ביותר בעולם. עם זאת, המבנה המורפולוגי העשיר שלה, הדיגלוסיה (דו-לשוניות - קיום מקביל של שפה ספרותית ומדוברת) ומערכת הכתיבה המורכבת דורשים אסטרטגיות עיבוד מקדים ומידול מיוחדות.
מדריך זה מספק סקירה מקיפה של ניתוח סנטימנט בערבית, תוך פירוט האתגרים, צינור העיבוד המקדים (Preprocessing Pipeline), יישום קלאסי של למידת מכונה (TF-IDF + רגרסיה לוגיסטית), וגישה מודרנית של למידה עמוקה באמצעות Transformers של Hugging Face.
1. האתגרים הבלשניים ב-NLP של השפה הערבית
לפני כתיבת קוד, מפתח חייב להבין מדוע לא ניתן לטפל בערבית באמצעות צינורות NLP מערביים סטנדרטיים:
- דיגלוסיה (Diglossia): השפה הערבית מחולקת בין ערבית ספרותית מודרנית (MSA) (המשמשת לכתיבה רשמית, חדשות ומסמכים רשמיים) לבין דיאלקטים מדוברים (Darja/Ammiya) (המשמשים ברשתות חברתיות ובשיח היומיומי). הדיאלקטים (למשל מצרי, לבנטיני, מפרצי) שונים באופן משמעותי באוצר המילים, בדקדוק ובביטויי הסנטימנט.
- מורפולוגיה עשירה: ערבית היא שפה תבניתית שבה מילים נגזרות משורש של שלוש או ארבע אותיות על ידי החלת משקלים ותבניות. מילה בודדת יכולה להכיל תחיליות, סיומיות ומוספיות ביניים המייצגות כינויי גוף, מילות יחס וזמנים (למשל, وسيكتبونها - “והם יכתבו אותה”).
- וריאציות אורתוגרפיות: אותיות ערביות משנות לעיתים קרובות את צורתן בהתאם למיקומן במילה, ומשתמשים כותבים לעיתים קרובות אותיות שונות באופן מתחלף (למשל, צורות אלף כגון
أ,إ,آ,اאו צורות יאא כגוןيלעומתى). - סיமני ניקود (Tashkeel): תנועות קצרות נכתבות כסיமני ניקוד מעל או מתחת לאותיות (למשל פתחה, דמה, כסרה). למרות שהן מבהירות את המשמעות, לעיתים קרובות הן מושמטות בטקסט דיגיטלי, מה שיוצר עמימות, או מתווספות באופן לא עקבי.
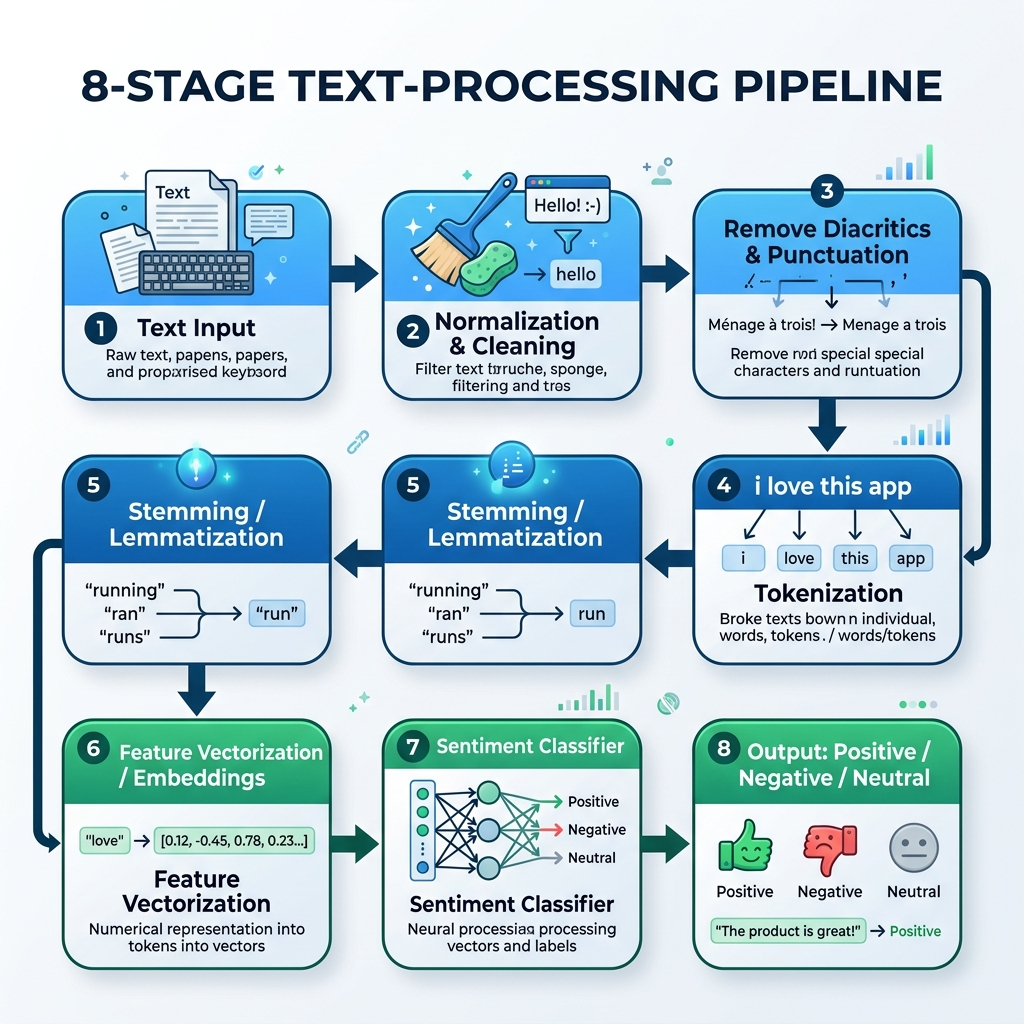
2. צינור ה-NLP בערבית
כדי לעבד טקסט בערבית, עלינו לבנות צינור ייעודי המטפל בנורמליזציה, הסרת ניקוד, חלוקה למילים (Tokenization), גזירה (Stemming) וחיזוי המודל:
graph TD
A[טקסט ערבי גולמי] --> B[נורמליזציה וניקוי]
B --> C[הסרת ניקוד ופיסוק]
C --> D[חלוקה למילים]
D --> E[גזירה / למטיזציה]
E --> F[וקטוריזציה / ייצוגי מילים]
F --> G[מסווג סנטימנט]
G --> H[פלט: חיובי / שלילי / ניטרלי]
3. מדריך שלב אחר שלב: עיבוד מקדים קלאסי ולמידת מכונה (Python)
נממש צינור עיבוד מלא באמצעות Python, NLTK ו-scikit-learn. נכתוב כללי נורמליזציה מותאמים אישית ונשתמש ב-ISRIStemmer של NLTK (גוזר המיועד במיוחד לערבית).
שלב 1: התקנת ספריות
ראשית, ודאו שהספריות הנדרשות מותקנות:
pip install nltk scikit-learn
שלב 2: כתיבת קוד העיבוד המקדים
להלن קוד ה-Python לניקוי, נורמליזציה וגזירה של טקסט בערבית:
import re
import nltk
from nltk.stem.isri import ISRIStemmer
# הורדת מילות עצירה אם טרם בוצע
nltk.download('stopwords', quiet=True)
from nltk.corpus import stopwords
# אתחול הגוזר הערבי
stemmer = ISRIStemmer()
arabic_stopwords = set(stopwords.words('arabic'))
def normalize_arabic(text):
# 1. הסרת ניקוד (Tashkeel)
text = re.sub(r'[ً-ْ]', '', text)
# 2. נורמליזציה של צורות האלף לאלף פשוטה
text = re.sub(r'[أإآ]', 'ا', text)
# 3. נורמליזציה של יאא ואלף מקסורה
text = re.sub(r'ى', 'ي', text)
# 4. נורמליזציה של תא מרבוטה להאא
text = re.sub(r'ة', 'ه', text)
# 5. הסרת תווים שאינם בערבית וסימני פיסוק
text = re.sub(r'[^ء-ي\s]', ' ', text)
# 6. צמצום רווחים כפולים
text = re.sub(r'\s+', ' ', text).strip()
return text
def preprocess_arabic_text(text):
# נורמליזציה של הטקסט
normalized = normalize_arabic(text)
# חלוקה למילים, הסרת מילות עצירה וביצוע גזירה
words = normalized.split()
processed_words = [stemmer.stem(word) for word in words if word not in arabic_stopwords]
return " ".join(processed_words)
# דוגמה לשימוש
raw_text = "الخدمةُ كانت ممتازةً وسريعةً جداً! أنصح الجميع بالتعامل معهم."
print("מקור:", raw_text)
print("לאחר עיבוד:", preprocess_arabic_text(raw_text))
# פלט: ممتاز سرع نصح جمع عمل مع
שלב 3: אימון מסווג פשוט
כעת, נייצג את הטקסט המעובד כוקטורים באמצעות TF-IDF ונאמן מודל רגרסיה לוגיסטית:
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import Pipeline
# נתוני אימון לדוגמה
train_sentences = [
"المنتج رائع جدا وأنصح بشرائه",
"التوصيل كان بطيئا والخدمة سيئة للغاية",
"أعجبني التطبيق وسهل الاستخدام",
"تجربة سيئة جدا ولا أنصح به أبدا",
"خدمة العملاء كانت متعاونة وممتازة"
]
# תגיות: 1 = חיובי, 0 = שלילי
train_labels = [1, 0, 1, 0, 1]
# עיבוד מקדים של נתוני האימון
preprocessed_train = [preprocess_arabic_text(s) for s in train_sentences]
# יצירת צינור עבודה: וקטוריזציית TF-IDF + מסווג רגרסיה לוגיסטית
model_pipeline = Pipeline([
('tfidf', TfidfVectorizer()),
('clf', LogisticRegression())
])
# אימון המודל
model_pipeline.fit(preprocessed_train, train_labels)
# בדיקה עם טקסט חדש
test_text = "التطبيق سيئ للغاية ولا يعمل بشكل صحيح"
preprocessed_test = preprocess_arabic_text(test_text)
prediction = model_pipeline.predict([preprocessed_test])[0]
print(f"טקסט לבדיקה: '{test_text}'")
print(f"לאחר עיבוד מקדים: '{preprocessed_test}'")
print(f"סנטימנט שנחזה: {'חיובי' if prediction == 1 else 'שלילי'}")
4. מדריך שלב אחר שלב: סיווג מודרני מבוסס Transformers (Hugging Face)
בעוד שגזירה ו-TF-IDF עובדים היטב עבור סיווג בסיסי, הם נכשלים בהבנת הקשר (Context), סרקזם ושינויי דיאלקטים מורכבים. לתוצאות המתקדמות ביותר בתעשייה, אנו משתמשים במודלי Transformers מאומנים מראש כמו AraBERT או CamelBERT.
להלן כיצד להשתמש בספריית transformers של Hugging Face לניתוח סנטימנט של טקסט בערבית במספר שורות קוד בלבד:
שלב 1: התקנת ספריות
pip install transformers torch sentencepiece
שלב 2: טעינת צינור המודל
נשתמש במודל האופטימלי CAMeL-Lab/bert-base-arabic-sentiment-msa המאוחסן ב-Hugging Face Hub:
from transformers import pipeline
# אתחול צינור ניתוח הסנטימנט עם מודל ערבית ייעודי
arabic_sentiment_analyzer = pipeline(
"sentiment-analysis",
model="CAMeL-Lab/bert-base-arabic-sentiment-msa"
)
# משפטים לבדיקה (ספרותית ומדוברת)
sentences = [
"أنا سعيد جداً باستخدام هذا المنتج الرائع",
"الفيلم كان مملاً والقصة غير مترابطة על الإطلاق"
]
results = arabic_sentiment_analyzer(sentences)
for sentence, result in zip(sentences, results):
label = result['label']
confidence = result['score'] * 100
print(f"טקסט: {sentence}")
print(f"סנטימנט: {label} (ביטחון של {confidence:.2f}%)
")
5. השוואת מודלים: למידת מכונה מסורתית לעומת Transformers
| תכונה | למידת מכונה מסורתית (TF-IDF + SVM/LR) | Transformers (AraBERT/CamelBERT) |
|---|---|---|
| הבנת הקשר | נמוכה (מתייחסת למילים כמאפיינים עצמאיים) | גבוהה (מבינה את סדר המילים וההקשר) |
| טיפול בדיאלקטים | דל (דורש מילוני דיאלקטים מותאמים אישית) | מצוין (מטפל בדיאלקטים מורכבים בצורה טבעית) |
| דרישות חישוב | נמוכות במיוחד (רץ על כל מעבד בתוך מילישניות) | גבוהות (דורש GPU לחיזוי מהיר) |
| נתוני אימון נדרשים | גבוהים (דורש סטים גדולים מתויגים להכללה) | נמוכים (מאומן מראש, עובד מצוין עם Fine-tuning) |
| מילים מחוץ למילון (OOV) | סיכון גבוה לפספוס מילים חדשות | סיכון מינימלי (משתמש בחלוקה לתת-מילים) |
6. סיכום
ניתוח סנטימנט בערבית הוא תחום המתפתח במהירות. בעוד שטכניקות למידת מכונה מסורתיות עם עיבוד מקדים מותאם אישית (כמו נורמליזציה וגזירה) הן מהירות וחסכוניות למשימות פשוטות, מודלי ה-Transformers המודרניים הציבו רף חדש לדיוק וטיפול בדיאלקטים.
על ידי שילוב של כללי ניקוי לשוניים נכונים עם ארכיטקטורות המודל המתאימות, תוכלו לבנות מערכות חזקות המסוגלות לפתוח את הקול הרגשי של העולם הערבי.
חקרו תובנות נוספות על בינה מלאכותית ו-NLP בבלוג של Ghaznix →