تحلیل احساسات زبان عربی: راهنمای عملی پیشپردازش NLP و مدلسازی

در عصر ارتباطات دیجیتال جهانی، تحلیل احساسات - وظیفه شناسایی لحن عاطفی در پس یک متن - برای کسبوکارها، دولتها و پژوهشگران بسیار حیاتی شده است. در حالی که تحلیل احساسات برای زبانهایی مانند انگلیسی بسیار بالغ است، اعمال آن روی زبان عربی مجموعهای منحصربهفرد از چالشهای زبانی و فنی را به همراه دارد.
عربی با داشتن بیش از ۴۰۰ میلیون سخنور، یکی از پرگویشترین زبانهای جهان است. با این حال، ساختار صرفی غنی، دوگانه گویشی (همزیستی اشکال استاندارد و محاورهای) و سیستم نوشتاری پیچیده آن نیازمند استراتژیهای پیشپردازش و مدلسازی تخصصی است.
این راهنما یک مرور جامع از تحلیل احساسات زبان عربی ارائه میدهد و چالشها، خط لوله پیشپردازش، یک پیادهسازی کلاسیک یادگیری ماشین (TF-IDF + رگرسیون لجستیک) و یک رویکرد مدرن یادگیری عمیق با استفاده از ترانسفورمرهای هاکینگ فیس را با جزئیات تشریح میکند.
۱. چالشهای زبانی NLP عربی
قبل از نوشتن کد، یک توسعهدهنده باید درک کند که چرا نمیتوان با خط لولههای استاندارد NLP غربی با عربی رفتار کرد:
- دوگانگی گویشی (Diglossia): زبان عربی بین عربی استاندارد مدرن (MSA) (مورد استفاده در نوشتار رسمی، اخبار و اسناد دولتی) و گویشهای محاورهای (Darja/Ammiya) (مورد استفاده در شبکههای اجتماعی و گفتار روزمره) تقسیم شده است. گویشها (مانند مصری، شامی، خلیجی) در واژگان، دستور زبان و بیان احساسات تفاوت چشمگیری دارند.
- صرف غنی (Rich Morphology): عربی یک زبان ریشهمحور است که در آن کلمات با اعمال الگوها از یک ریشه سه یا چهار حرفی مشتق میشوند. یک کلمه واحد میتواند شامل پیشوندها، پسوندها و میانوندهایی باشد که نشاندهنده ضمایر، حروف اضافه و زمانها هستند (مانند وسيكتبونها - “و آنها آن را خواهند نوشت”).
- تغییرات املایی: حروف عربی اغلب بر اساس موقعیت خود در کلمه تغییر شکل میدهند و کاربران اغلب از حروف مختلف به جای یکدیگر استفاده میکنند (به عنوان مثال، اشکال الف مانند
أ،إ،آ،ایا اشکال یاء ماننديدر مقایسه باى). - علائم حرکت (تشکیل): حروف مصوت کوتاه به صورت علائم حرکت در بالا یا پایین حروف نوشته میشوند (مانند فتحه، ضمه، کسره). हालांकि آنها معنی را شفاف میکنند، اما اغلب در متون دیجیتال حذف میشوند و باعث ابهام میگردند یا به صورت ناسازگار اضافه میشوند.
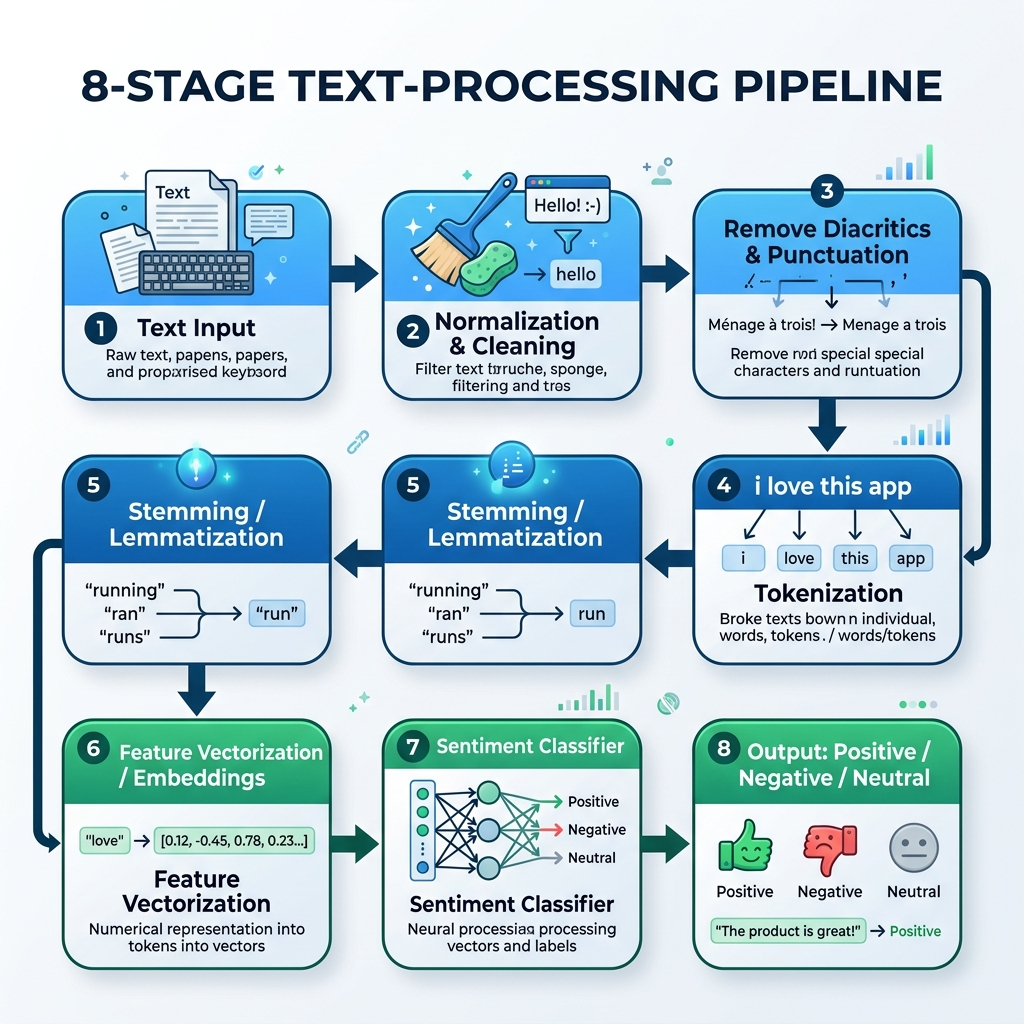
۲. خط لوله NLP عربی
برای پردازش متن عربی، باید یک خط لوله تخصصی بسازیم که نرمالسازی، حذف علائم تشکیل، توکنسازی، ریشهیابی (Stemming) و استنتاج مدل را مدیریت کند:
graph TD
A[متن عربی خام] --> B[نرمالسازی و پاکسازی]
B --> C[حذف علائم تشکیل و نشانهگذاری]
C --> D[توکنسازی]
D --> E[ریشهیابی / لِماتیزاسیون]
E --> F[بردارسازی ویژگیها / تعبیهسازی]
F --> G[طبقهبند احساسات]
G --> H[خروجی: مثبت / منفی / خنثی]
۳. راهنمای گامبهگام: پیشپردازش کلاسیک و یادگیری ماشین (پایتون)
بیایید یک خط لوله کامل را با استفاده از پایتون، NLTK و scikit-learn پیادهسازی کنیم. ما قوانین نرمالسازی سفارشی مینویسیم و از ISRIStemmer در NLTK (یک ریشهیاب بازیابی اطلاعات که مخصوص زبان عربی طراحی شده است) استفاده میکنیم.
مرحله ۱: نصب وابستگیها
ابتدا مطمئن شوید که کتابخانههای مورد نیاز را نصب کردهاید:
pip install nltk scikit-learn
مرحله ۲: نوشتن کد پیشپردازش
در اینجا کد پایتون برای پاکسازی، نرمالسازی و ریشهیابی متن عربی آورده شده است:
import re
import nltk
from nltk.stem.isri import ISRIStemmer
# اگر قبلاً دانلود نکردهاید، کلمات توقف را دانلود کنید
nltk.download('stopwords', quiet=True)
from nltk.corpus import stopwords
# مقداردهی اولیه ریشهیاب عربی
stemmer = ISRIStemmer()
arabic_stopwords = set(stopwords.words('arabic'))
def normalize_arabic(text):
# ۱. حذف علائم حرکت (تشکیل)
text = re.sub(r'[ً-ْ]', '', text)
# ۲. نرمالسازی اشکال الف به الف ساده
text = re.sub(r'[أإآ]', 'ا', text)
# ۳. نرمالسازی یاء و الف مقصوره
text = re.sub(r'ى', 'ي', text)
# ۴. نرمالسازی تاء مربوطه به هاء
text = re.sub(r'ة', 'ه', text)
# ۵. حذف کاراکترهای غیر عربی و علائم نشانهگذاری
text = re.sub(r'[^ء-ي\s]', ' ', text)
# ۶. حذف فاصلههای اضافی
text = re.sub(r'\s+', ' ', text).strip()
return text
def preprocess_arabic_text(text):
# نرمالسازی متن
normalized = normalize_arabic(text)
# توکنسازی، حذف کلمات توقف و ریشهیابی
words = normalized.split()
processed_words = [stemmer.stem(word) for word in words if word not in arabic_stopwords]
return " ".join(processed_words)
# مثال استفاده
raw_text = "الخدمةُ كانت ممتازةً وسريعةً جداً! أنصح الجميع بالتعامل معهم."
print("اصلی:", raw_text)
print("پردازش شده:", preprocess_arabic_text(raw_text))
# خروجی: ممتاز سرع نصح جمع عمل مع
مرحله ۳: آموزش یک طبقهبند ساده
اکنون، بیایید متن پردازش شده خود را با استفاده از TF-IDF برداری کنیم و یک مدل رگرسیون لجستیک را آموزش دهیم:
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import Pipeline
# نمونه دادههای آموزشی
train_sentences = [
"المنتج رائع جدا وأنصح بشرائه",
"التوصيل كان بطيئا والخدمة سيئة للغاية",
"أعجبني التطبيق وسهل الاستخدام",
"تجربة سيئة جدا ولا أنصح به أبدا",
"خدمة العملاء كانت متعاونة وممتازة"
]
# برچسبها: ۱ = مثبت، ۰ = منفی
train_labels = [1, 0, 1, 0, 1]
# پیشپردازش دادههای آموزشی
preprocessed_train = [preprocess_arabic_text(s) for s in train_sentences]
# ایجاد خط لوله: بردارساز TF-IDF + طبقهبند رگرسیون لجستیک
model_pipeline = Pipeline([
('tfidf', TfidfVectorizer()),
('clf', LogisticRegression())
])
# آموزش مدل
model_pipeline.fit(preprocessed_train, train_labels)
# تست با متن جدید
test_text = "التطبيق سيئ للغاية ولا يعمل بشكل صحيح"
preprocessed_test = preprocess_arabic_text(test_text)
prediction = model_pipeline.predict([preprocessed_test])[0]
print(f"متن تست: '{test_text}'")
print(f"پیشپردازش شده: '{preprocessed_test}'")
print(f"احساس پیشبینی شده: {'مثبت' if prediction == 1 else 'منفی'}")
۴. راهنمای گامبهگام: طبقهبندی مدرن مبتنی بر ترانسفورمر (هاکینگ فیس)
اگرچه ریشهیابی و TF-IDF برای طبقهبندی پایه خوب کار میکنند، اما در درک زمینه، کنایه و تغییرات پیچیده گویشی ناتوان هستند. برای نتایج پیشرفته، ما از ترانسفورمرهای پیشآموزشدیده مانند AraBERT یا CamelBERT استفاده میکنیم.
در اینجا نحوه استفاده از کتابخانه transformers هاکینگ فیس برای اجرای تحلیل احساسات روی متن عربی تنها در چند خط کد آورده شده است:
مرحله ۱: نصب وابستگیها
pip install transformers torch sentencepiece
مرحله ۲: بارگذاری خط لوله مدل
ما از مدل بسیار بهینهشده CAMeL-Lab/bert-base-arabic-sentiment-msa که در هاب هاکینگ فیس میزبانی میشود استفاده خواهیم کرد:
from transformers import pipeline
# مقداردهی اولیه خط لوله تحلیل احساسات با یک مدل عربی تخصصی
arabic_sentiment_analyzer = pipeline(
"sentiment-analysis",
model="CAMeL-Lab/bert-base-arabic-sentiment-msa"
)
# جملات تست (MSA و گویشی)
sentences = [
"أنا سعيد جداً باستخدام هذا المنتج الرائع",
"الفيلم كان مملاً والقصة غير مترابطة على الإطلاق"
]
results = arabic_sentiment_analyzer(sentences)
for sentence, result in zip(sentences, results):
label = result['label']
confidence = result['score'] * 100
print(f"متن: {sentence}")
print(f"احساسات: {label} (با اطمینان {confidence:.2f} درصد)
")
۵. مقایسه مدلها: یادگیری ماشین سنتی در مقابل ترانسفورمرها
| ویژگی | یادگیری ماشین سنتی (TF-IDF + SVM/LR) | ترانسفورمرها (AraBERT/CamelBERT) |
|---|---|---|
| درک زمینه | پایین (با کلمات به عنوان ویژگیهای مستقل رفتار میکند) | بالا (ترتیب کلمات و زمینه را درک میکند) |
| مدیریت گویشها | ضعیف (نیاز به فرهنگهای لغت گویش سفارشی دارد) | عالی (گویشهای پیچیده را به طور طبیعی مدیریت میکند) |
| نیازهای محاسباتی | بسیار پایین (روی هر CPU در چند میلیثانیه اجرا میشود) | بالا (نیاز به GPU برای استنتاج سریع دارد) |
| دادههای آموزشی مورد نیاز | بالا (برای تعمیم نیاز به مجموعههای بزرگ برچسبگذاری شده دارد) | پایین (پیشآموزشدیده، با تنظیم دقیق به خوبی کار میکند) |
| خارج از دایره واژگان (OOV) | خطر بالای از دست دادن کلمات جدید | حداقل خطر (از توکنسازی زیرکلمهای استفاده میکند) |
۶. نتیجهگیری
تحلیل احساسات زبان عربی زمینهای است که به سرعت در حال پیشرفت است. در حالی که تکنیکهای یادگیری ماشین سنتی با پیشپردازش سفارشی (مانند نرمالسازی و ریشهیابی) برای کارهای ساده سریع و مقرونبهصرفه هستند، ترانسفورمرهای مدرن معیار جدیدی را برای دقت و مدیریت گویشها تعیین کردهاند.
با ترکیب قوانین پاکسازی زبانی مناسب با معماریهای مدل مناسب، میتوانید سیستمهای قدرتمندی بسازید که قادر به درک صدای عاطفی جهان عرب هستند.
بینشهای بیشتری را در زمینه هوش مصنوعی و پردازش زبان طبیعی در وبلاگ غزنکس بخوانید →