Analyse des sentiments en arabe : guide pratique de prétraitement NLP et de modélisation

À l’ère de la communication numérique mondialisée, l’analyse des sentiments (l’identification de la tonalité émotionnelle derrière un texte) est devenue cruciale pour les entreprises, les gouvernements et les chercheurs. Bien que l’analyse des sentiments soit très mature pour des langues comme le français, son application à l’arabe présente un ensemble unique de défis linguistiques et techniques.
Avec plus de 400 millions de locuteurs, l’arabe est l’une des langues les plus parlées au monde. Cependant, sa riche structure morphologique, la diglossie (coexistence de formes standard et familières) et son système d’écriture complexe nécessitent des stratégies de prétraitement et de modélisation spécialisées.
Ce guide propose un parcours complet de l’analyse des sentiments en arabe, détaillant les défis, le pipeline de prétraitement, une implémentation classique de Machine Learning (TF-IDF + Régression Logistique) et une approche moderne de Deep Learning à l’aide des Transformers de Hugging Face.
1. Les défis linguistiques du NLP en arabe
Avant d’écrire du code, un développeur doit comprendre pourquoi l’arabe ne peut pas être traité avec les pipelines NLP occidentaux standard :
- Diglossie : L’arabe est divisé entre l’arabe standard moderne (MSA) (utilisé dans l’écriture formelle, les actualités et les documents officiels) et les dialectes familiers (Darja/Ammiya) (utilisés sur les réseaux sociaux et dans le langage quotidien). Les dialectes (par exemple, égyptien, levantin, du Golfe) diffèrent considérablement en termes de vocabulaire, de grammaire et d’expressions de sentiment.
- Morphologie riche : L’arabe est une langue à racine où les mots sont dérivés d’une racine de trois ou quatre lettres en appliquant des schémas. Un seul mot peut contenir des préfixes, des suffixes et des infixes représentant des pronoms, prepositions et temps (par exemple, وسيكتبونها - « et ils l’écriront »).
- Variations orthographiques : Les lettres arabes changent souvent de forme en fonction de leur position, et les utilisateurs utilisent fréquemment des lettres de manière interchangeable (par exemple, des formes d’Alif comme
أ,إ,آ,اou des formes de Yaa commeيpar rapport àى). - Diacritiques (Tashkeel) : Les voyelles courtes sont écrites sous forme de diacritiques au-dessus ou au-dessous des lettres (par exemple, Fatha, Damma, Kasra). Bien qu’ils clarifient le sens, ils sont souvent omis dans le texte numérique, ce qui provoque une ambiguïté, ou ajoutés de manière incohérente, ce qui entraîne une rareté des données.
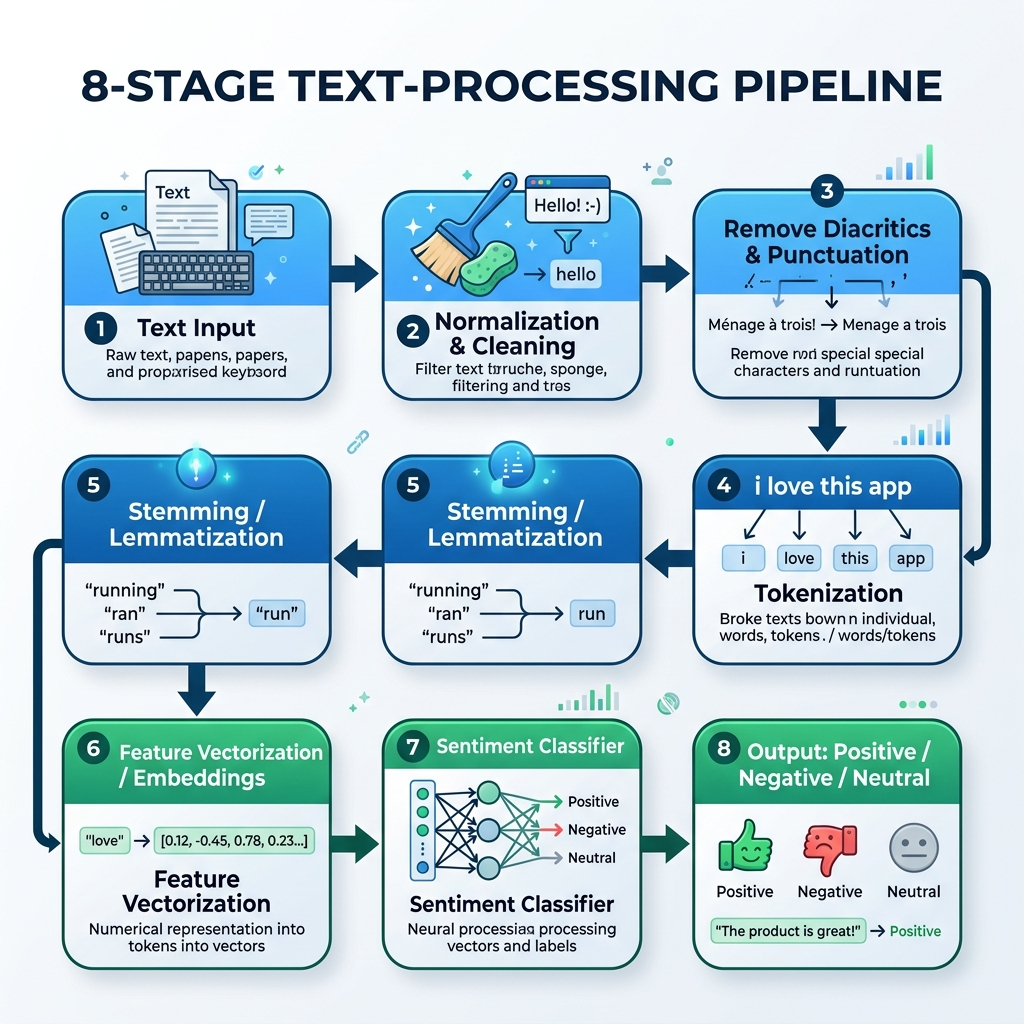
2. Le pipeline NLP pour l’arabe
Pour traiter le texte arabe, nous devons construire un pipeline spécialisé qui gère la normalisation, la suppression des diacritiques, la tokenisation, le stemming (racinisation) et l’inférence du modèle :
graph TD
A[Texte Arabe Brut] --> B[Normalisation et Nettoyage]
B --> C[Supprimer Diacritiques et Ponctuation]
C --> D[Tokenisation]
D --> E[Stemming / Lemmatisation]
E --> F[Vectorisation des Caracteristiques / Embeddings]
F --> G[Classificateur de Sentiment]
G --> H[Sortie : Positif / Negatif / Neutre]
3. Walkthrough: Prétraitement classique et Machine Learning (Python)
Implémentons un pipeline complet en utilisant Python, NLTK et scikit-learn. Nous écrirons des règles de normalisation personnalisées et utiliserons l’ISRIStemmer de NLTK (un raciniseur de recherche d’information spécifiquement conçu pour l’arabe).
Étape 1 : Installer les dépendances
Tout d’abord, assurez-vous que les bibliothèques requises sont installées :
pip install nltk scikit-learn
Étape 2 : Écrire le code de prétraitement
Voici le code Python pour nettoyer, normaliser et raciniser le texte arabe :
import re
import nltk
from nltk.stem.isri import ISRIStemmer
# Telechargez les mots vides si ce n'est pas deja fait
nltk.download('stopwords', quiet=True)
from nltk.corpus import stopwords
# Initialiser le Stemmer Arabe
stemmer = ISRIStemmer()
arabic_stopwords = set(stopwords.words('arabic'))
def normalize_arabic(text):
# 1. Supprimer les diacritiques (Tashkeel)
text = re.sub(r'[ً-ْ]', '', text)
# 2. Normaliser les formes d'Alif en un Alif simple
text = re.sub(r'[أإآ]', 'ا', text)
# 3. Normaliser Yaa et Alif Maqsoora
text = re.sub(r'ى', 'ي', text)
# 4. Normaliser Ta Marbuta en Haa
text = re.sub(r'ة', 'ه', text)
# 5. Supprimer les caracteres non arabes et la ponctuation
text = re.sub(r'[^ء-ي\s]', ' ', text)
# 6. Eliminer les espaces multiples
text = re.sub(r'\s+', ' ', text).strip()
return text
def preprocess_arabic_text(text):
# Normaliser le texte
normalized = normalize_arabic(text)
# Tokeniser, supprimer les mots vides et raciniser
words = normalized.split()
processed_words = [stemmer.stem(word) for word in words if word not in arabic_stopwords]
return " ".join(processed_words)
# Exemple d'utilisation
raw_text = "الخدمةُ كانت ممتازةً وسريعةً جداً! أنصح الجميع بالتعامل معهم."
print("Original :", raw_text)
print("Prétraité :", preprocess_arabic_text(raw_text))
# Output: ممتاز سرع نصح جمع عمل مع
Étape 3 : Entraîner un classificateur simple
Maintenant, vectorisons notre texte traité en utilisant TF-IDF et entraînons un modèle de Régression Logistique :
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import Pipeline
# Donnees d'entrainement d'exemple
train_sentences = [
"المنتج رائع جدا وأنصح بشرائه",
"التوصيل كان بطيئا والخدمة سيئة للغاية",
"أعجبني التطبيق وسهل الاستخدام",
"تجربة سيئة جدا ولا أنصح به أبدا",
"خدمة العملاء كانت متعاونة وممتازة"
]
# Etiquette : 1 = Positif, 0 = Negatif
train_labels = [1, 0, 1, 0, 1]
# Pretraiter les donnees d'entrainement
preprocessed_train = [preprocess_arabic_text(s) for s in train_sentences]
# Creer le pipeline : vectoriseur TF-IDF + classificateur Regression Logistique
model_pipeline = Pipeline([
('tfidf', TfidfVectorizer()),
('clf', LogisticRegression())
])
# Entrainer le modele
model_pipeline.fit(preprocessed_train, train_labels)
# Tester avec un nouveau texte
test_text = "التطبيق سيئ للغاية ولا يعمل بشكل صحيح"
preprocessed_test = preprocess_arabic_text(test_text)
prediction = model_pipeline.predict([preprocessed_test])[0]
print(f"Texte de test : '{test_text}'")
print(f"Prétraité : '{preprocessed_test}'")
print(f"Sentiment prédit : {'Positif' if prediction == 1 else 'Négatif'}")
4. Walkthrough : Classification moderne basée sur les Transformers (Hugging Face)
Bien que la racinisation (stemming) et TF-IDF fonctionnent bien pour une classification de base, ils ne parviennent pas à capturer le contexte, le sarcasme et les variations dialectales complexes. Pour des résultats de pointe, nous utilisons des Transformers pré-entraînés comme AraBERT ou CamelBERT.
Voici comment utiliser la bibliothèque transformers de Hugging Face pour exécuter une analyse des sentiments sur du texte arabe en quelques lignes de code seulement :
Étape 1 : Installer les dépendances
pip install transformers torch sentencepiece
Étape 2 : Charger le pipeline du modèle
Nous utiliserons le modèle hautement optimisé CAMeL-Lab/bert-base-arabic-sentiment-msa hébergé sur le hub Hugging Face :
from transformers import pipeline
# Initialiser le pipeline d'analyse des sentiments avec un modele arabe specialise
arabic_sentiment_analyzer = pipeline(
"sentiment-analysis",
model="CAMeL-Lab/bert-base-arabic-sentiment-msa"
)
# Phrases de test (MSA et dialectal)
sentences = [
"أنا سعيد جداً باستخدام هذا المنتج الرائع",
"الفيلم كان مملاً والقصة غير مترابطة على الإطلاق"
]
results = arabic_sentiment_analyzer(sentences)
for sentence, result in zip(sentences, results):
label = result['label']
confidence = result['score'] * 100
print(f"Texte : {sentence}")
print(f"Sentiment : {label} ({confidence:.2f}% de confiance)
")
5. Comparaison des modèles : Machine Learning traditionnel vs Transformers
| Caractéristique | ML traditionnel (TF-IDF + SVM/LR) | Transformers (AraBERT/CamelBERT) |
|---|---|---|
| Compréhension contextuelle | Faible (traite les mots comme des caractéristiques indépendantes) | Élevée (comprend l’ordre des mots et le contexte) |
| Gestion des dialectes | Médiocre (nécessite des dictionnaires de dialectes personnalisés) | Excellente (gère les dialectes complexes naturellement) |
| Ressources de calcul requises | Extrêmement faibles (s’exécute sur n’importe quel CPU en quelques millisecondes) | Élevées (nécessite un GPU pour une inférence rapide) |
| Données d’entraînement requises | Élevées (nécessite de grands ensembles étiquetés pour généraliser) | Faibles (pré-entraîné, fonctionne bien avec un réglage fin) |
| Hors Vocabulaire (OOV) | Risque élevé de rater de nouveaux mots | Risque minimal (utilise la tokenisation de sous-mots) |
6. Conclusion
L’analyse des sentiments en arabe est un domaine en évolution rapide. Bien que les techniques de machine learning traditionnelles avec un prétraitement personnalisé (comme la normalisation et la racinisation) soient rapides et rentables pour des tâches simples, les Transformers modernes ont établi une nouvelle référence en matière de précision et de gestion des dialectes.
En combinant des règles de nettoyage linguistique appropriées avec les bonnes architectures de modèle, vous pouvez créer des systèmes puissants capables de libérer la voix émotionnelle du monde arabe.
Explorez plus d’analyses sur l’IA et le NLP sur le blog Ghaznix →