Анализ тональности арабского языка: практическое руководство по предобработке NLP и моделированию

В эпоху глобализированных цифровых коммуникаций анализ тональности (задача определения эмоционального тона текста) стал иметь решающее значение для бизнеса, правительств и исследователей. В то время как анализ тональности для таких языков, как английский, развит очень хорошо, его применение к арабскому языку сопряжено с уникальным набором лингвистических и технических проблем.
Арабский язык с более чем 400 миллионами носителей является одним из самых распространенных языков в мире. Однако его богатая морфологическая структура, диглоссия (сосуществование стандартных и разговорных форм) и сложная система письма требуют специализированных стратегий предобработки и моделирования.
Это руководство содержит исчерпывающее описание процесса анализа тональности арабского языка, подробно описывая проблемы, конвейер предобработки, классическую реализацию машинного обучения (TF-IDF + логистическая регрессия) и современный подход к глубокому обучению с использованием трансформеров Hugging Face.
1. Лингвистические проблемы NLP для арабского языка
Прежде чем писать код, разработчик должен понять, почему арабский язык нельзя обрабатывать с помощью стандартных западных конвейеров NLP:
- Диглоссия: Арабский язык разделен на современный стандартный арабский язык (MSA) (используемый в официальной переписке, новостях и официальных документах) и разговорные диалекты (дарья/аммия) (используемые в социальных сетях и повседневной речи). Диалекты (например, египетский, левантийский, диалекты Персидского залива) значительно различаются по словарному запасу, грамматике и выражению эмоций.
- Богатая морфология: Арабский язык — это корневой язык, в котором слова образуются от трех- или четырехбуквенной основы путем применения определенных моделей (форм). Одно слово может содержать приставки, суффиксы и инфиксы, представляющие местоимения, предлоги и времена (например, وسيكتبونها — «и они это напишут»).
- Орфографические вариации: Арабские буквы часто меняют свою форму в зависимости от их положения в слове, и пользователи часто используют некоторые буквы взаимозаменяемо (например, формы алифа
أ,إ,آ,اили формы йаيпо сравнению сى). - Диакритические знаки (ташкиль): Краткие гласные пишутся в виде диакритических знаков над или под буквами (например, фатха, дамма, кясра). Хотя они уточняют смысл, в цифровых текстах их часто опускают, что вызывает двусмысленность, или добавляют непоследовательно.
2. Конвейер NLP для арабского языка
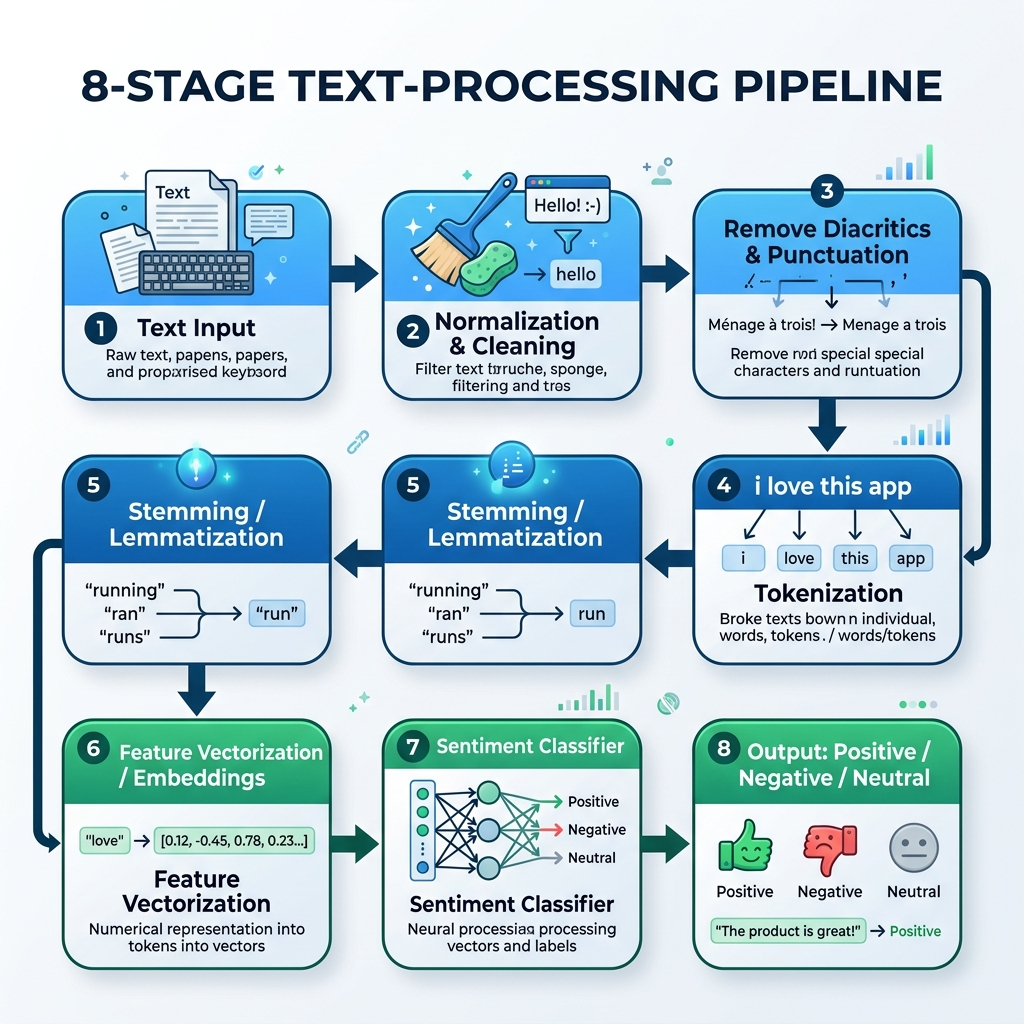
Для обработки арабского текста мы должны создать специализированный конвейер, который выполняет нормализацию, удаление диакритических знаков, токенизацию, стемминг и логический вывод модели:
graph TD
A[Сырой арабский текст] --> B[Нормализация и очистка]
B --> C[Удаление диакритики и пунктуации]
C --> D[Токенизация]
D --> E[Стемминг / Лемматизация]
E --> F[Векторизация признаков / Эмбеддинги]
F --> G[Классификатор тональности]
G --> H[Результат: Положительный / Отрицательный / Нейтральный]
3. Практическое руководство: классическая предобработка и машинное обучение (Python)
Давайте реализуем полный конвейер с использованием Python, NLTK и scikit-learn. Мы напишем собственные правила нормализации и будем использовать ISRIStemmer библиотеки NLTK (стеммер для информационного поиска, разработанный специально для арабского языка).
Шаг 1: Установка зависимостей
Сначала убедитесь, что у вас установлены необходимые библиотеки:
pip install nltk scikit-learn
Шаг 2: Написание кода предобработки
Вот код на Python для очистки, нормализации и стемминга арабского текста:
import re
import nltk
from nltk.stem.isri import ISRIStemmer
# Загрузите стоп-слова, если вы еще этого не сделали
nltk.download('stopwords', quiet=True)
from nltk.corpus import stopwords
# Инициализируем арабский стеммер
stemmer = ISRIStemmer()
arabic_stopwords = set(stopwords.words('arabic'))
def normalize_arabic(text):
# 1. Удаляем диакритические знаки (ташкиль)
text = re.sub(r'[ً-ْ]', '', text)
# 2. Нормализуем формы алифа в обычный алиф
text = re.sub(r'[أإآ]', 'ا', text)
# 3. Нормализуем йа и алиф максуру
text = re.sub(r'ى', 'ي', text)
# 4. Нормализуем та марбуту в ха
text = re.sub(r'ة', 'ه', text)
# 5. Удаляем неарабские символы и пунктуацию
text = re.sub(r'[^ء-ي\s]', ' ', text)
# 6. Убираем лишние пробелы
text = re.sub(r'\s+', ' ', text).strip()
return text
def preprocess_arabic_text(text):
# Нормализуем текст
normalized = normalize_arabic(text)
# Токенизируем, удаляем стоп-слова и выполняем стемминг
words = normalized.split()
processed_words = [stemmer.stem(word) for word in words if word not in arabic_stopwords]
return " ".join(processed_words)
# Пример использования
raw_text = "الخدمةُ كانت ممتازةً وسريعةً جداً! أنصح الجميع بالتعامل معهم."
print("Оригинал:", raw_text)
print("Обработанный:", preprocess_arabic_text(raw_text))
# Вывод: ممتاز سرع نصح جمع عمل مع
Шаг 3: Обучение простого классификатора
Теперь давайте векторизуем обработанный текст с помощью TF-IDF и обучим модель логистической регрессии:
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import Pipeline
# Пример обучающих данных
train_sentences = [
"المنتج رائع جدا وأنصح بشرائه",
"التوصيل كان بطиئا والخدمة سيئة للغاية",
"أعجبني التطبيق وسهل الاستخدام",
"تجربة سيئة جدا ولا أنصح به أبدا",
"خدمة العملاء كانت متعاونة وممتازة"
]
# Метки: 1 = Положительный, 0 = Отрицательный
train_labels = [1, 0, 1, 0, 1]
# Предобработка обучающих данных
preprocessed_train = [preprocess_arabic_text(s) for s in train_sentences]
# Создаем конвейер: векторизатор TF-IDF + классификатор логистической регрессии
model_pipeline = Pipeline([
('tfidf', TfidfVectorizer()),
('clf', LogisticRegression())
])
# Обучаем модель
model_pipeline.fit(preprocessed_train, train_labels)
# Тестируем на новом тексте
test_text = "التطبيق سيئ للغاية ولا يعمل بشكل صحيح"
preprocessed_test = preprocess_arabic_text(test_text)
prediction = model_pipeline.predict([preprocessed_test])[0]
print(f"Тестовый текст: '{test_text}'")
print(f"Предобработанный: '{preprocessed_test}'")
print(f"Прогнозируемая тональность: {'Положительная' if prediction == 1 else 'Отрицательная'}")
4. Практическое руководство: классификация на основе современных трансформеров (Hugging Face)
Хотя стемминг и TF-IDF хорошо работают для базовой классификации, они не способны уловить контекст, сарказм и сложные диалектные особенности. Для получения результатов на уровне последних достижений науки и техники мы используем предобученные трансформеры, такие как AraBERT или CamelBERT.
Вот как использовать библиотеку transformers от Hugging Face для анализа тональности арабского текста всего в нескольких строках кода:
Шаг 1: Установка зависимостей
pip install transformers torch sentencepiece
Шаг 2: Загрузка конвейера модели
Мы будем использовать высокооптимизированную модель CAMeL-Lab/bert-base-arabic-sentiment-msa, размещенную на Hugging Face Hub:
from transformers import pipeline
# Инициализируем конвейер анализа тональности со специализированной арабской моделью
arabic_sentiment_analyzer = pipeline(
"sentiment-analysis",
model="CAMeL-Lab/bert-base-arabic-sentiment-msa"
)
# Тестовые предложения (MSA и разговорный диалект)
sentences = [
"أنا سعيد جداً باستخدام هذا المنتج الرائع",
"الفيلم كان مملاً والقصة غير مترابطة على الإطلاق"
]
results = arabic_sentiment_analyzer(sentences)
for sentence, result in zip(sentences, results):
label = result['label']
confidence = result['score'] * 100
print(f"Текст: {sentence}")
print(f"Тональность: {label} (достоверность {confidence:.2f}%)
")
5. Сравнение моделей: классическое машинное обучение и трансформеры
| Признак | Классическое машинное обучение (TF-IDF + SVM/LR) | Трансформеры (AraBERT/CamelBERT) |
|---|---|---|
| Понимание контекста | Низкое (рассматривает слова как независимые признаки) | Высокое (понимает порядок слов и контекст) |
| Работа с диалектами | Плохая (требуются словари диалектов пользователя) | Отличная (естественным образом обрабатывает сложные диалекты) |
| Вычислительные требования | Крайне низкие (работает на любом CPU за миллисекунды) | Высокие (требуется GPU для быстрого вывода) |
| Требуемые обучающие данные | Высокие (нужны большие размеченные наборы для обобщения) | Низкие (предобученные модели хорошо адаптируются) |
| Слова за пределами словаря (OOV) | Высокий риск пропустить новые слова | Минимальный риск (используется токенизация подслов) |
6. Заключение
Анализ тональности арабского текста — это быстро развивающаяся область. В то время как традиционные методы машинного обучения с пользовательской предобработкой (нормализацией и стеммингом) работают быстро и экономичны для простых задач, современные трансформеры установили новый стандарт точности и работы с диалектами.
Сочетая правильные лингвистические правила очистки с правильными архитектурами моделей, вы можете создавать мощные системы, способные раскрыть эмоциональный голос арабского мира.