تحليل المشاعر باللغة العربية: دليل عملي لمعالجة النصوص وبناء النماذج

في عصر الاتصالات الرقمية المعولمة، أصبح تحليل المشاعر - وهو مهمة تحديد النبرة العاطفية وراء النص - أمرًا بالغ الأهمية للشركات والحكومات والباحثين. في حين أن تحليل المشاعر ناضج للغاية بالنسبة للغات مثل الإنجليزية، فإن تطبيقه على اللغة العربية يمثل مجموعة فريدة من التحديات اللغوية والتقنية.
تعد اللغة العربية واحدة من أكثر اللغات انتشارًا في العالم حيث يتحدث بها أكثر من 400 مليون شخص. ومع ذلك، فإن بنيتها الصرفية الغنية، وازدواجية اللغة (التعايش بين الفصحى والعامية)، ونظام كتابتها المعقد يتطلب استراتيجيات معالجة مسبقة وبناء نماذج متخصصة.
يقدم هذا الدليل شرحًا شاملاً لتحليل المشاعر باللغة العربية، ويوضح التحديات، وخطوات المعالجة المسبقة، والتطبيق العملي لتعلم الآلة الكلاسيكي (TF-IDF + الانحدار اللوجستي)، ونهج التعلم العميق الحديث باستخدام محولات Hugging Face.
1. التحديات اللغوية لمعالجة اللغة العربية (NLP)
قبل كتابة الكود، يجب على المطور فهم سبب عدم إمكانية التعامل مع اللغة العربية باستخدام خطوط معالجة النصوص الغربية القياسية:
- ازدواجية اللغة (Diglossia): تنقسم اللغة العربية بين اللغة العربية الفصحى الحديثة (MSA) (المستخدمة في الكتابة الرسمية والأخبار والوثائق الرسمية) واللهجات العامية (Darja/Ammiya) (المستخدمة في وسائل التواصل الاجتماعي والحديث اليومي). تختلف اللهجات (مثل المصرية، الشامية، الخليجية) بشكل كبير في المفردات والقواعد والتعبيرات العاطفية.
- الصرف الغني (Rich Morphology): اللغة العربية لغة اشتقاقية حيث تشتق الكلمات من جذر ثلاثي أو رباعي من خلال تطبيق أوزان معينة. يمكن أن تحتوي الكلمة الواحدة على سوابق ولواحق ودواخل تمثل الضمائر وحروف الجر والأزمنة (مثل: وسيكتبونها).
- الاختلافات الإملائية: غالبًا ما تتغير أشكال الحروف العربية بناءً على موقعها في الكلمة، وغالبًا ما يستخدم المستخدمون بعض الحروف بشكل متبادل (مثل أشكال الألف:
أ،إ،آ،اأو الياء والياء المقصورة:يمقابلى). - التشكيل (Diacritics): تُكتب الحركات القصيرة كعلامات تشكيل فوق الحروف أو تحتها (مثل الفتحة، الضمة، الكسرة). على الرغم من أنها توضح المعنى، إلا أنه غالبًا ما يتم حذفها في النصوص الرقمية مما يسبب غموضًا، أو تُضاف بشكل غير متسق مما يؤدي إلى تشتت البيانات.
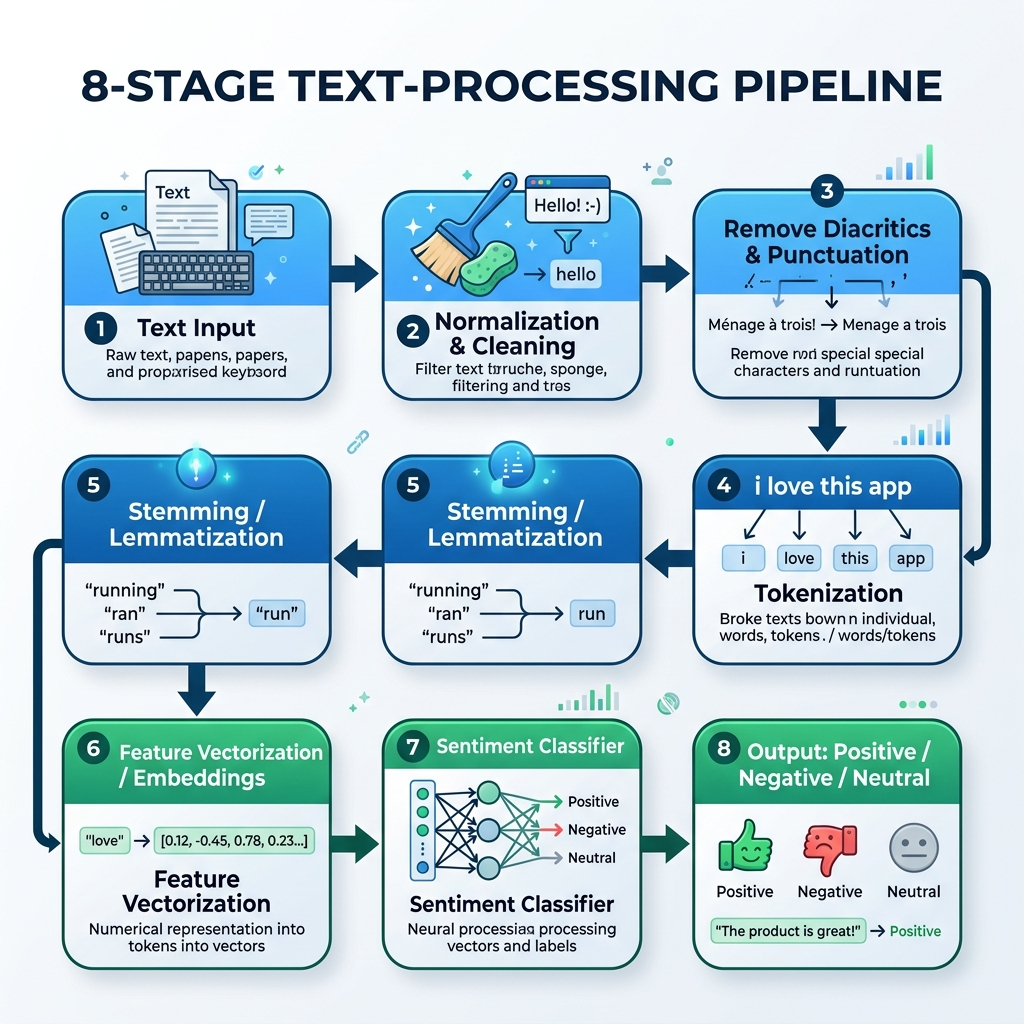
2. خط معالجة النصوص العربية (NLP Pipeline)
لمعالجة النصوص العربية، يجب علينا بناء مسار متخصص يتعامل مع المعالجة الإملائية، وإزالة التشكيل، وتقطيع الكلمات (Tokenization)، والجذع (Stemming)، واستنتاج النموذج:
graph TD
A[النص العربي الخام] --> B[المعالجة الإملائية والتنظيف]
B --> C[إزالة التشكيل وعلامات الترقيم]
C --> D[تقطيع الكلمات]
D --> E[الجذع / التدبيج]
E --> F[تمثيل الكلمات / التوجيه]
F --> G[مصنف المشاعر]
G --> H[النتيجة: إيجابي / سلبي / محايد]
3. شرح عملي: المعالجة المسبقة الكلاسيكية وتعلم الآلة (بايثون)
لنقوم بتنفيذ مسار كامل باستخدام بايثون ومكتبة NLTK ومكتبة scikit-learn. سنكتب قواعد معالجة مسبقة مخصصة ونستخدم ISRIStemmer من NLTK (وهو مجذر مصمم خصيصًا للغة العربية).
الخطوة 1: تثبيت المكتبات المطلوبة
أولاً، تأكد من تثبيت المكتبات اللازمة:
pip install nltk scikit-learn
الخطوة 2: كتابة كود المعالجة المسبقة
إليك كود بايثون لتنظيف وتوحيد وتجذير النص العربي:
import re
import nltk
from nltk.stem.isri import ISRIStemmer
# تحميل الكلمات المفتاحية المهملة إذا لم تكن محملة سابقا
nltk.download('stopwords', quiet=True)
from nltk.corpus import stopwords
# تهيئة المجذر العربي
stemmer = ISRIStemmer()
arabic_stopwords = set(stopwords.words('arabic'))
def normalize_arabic(text):
# 1. إزالة التشكيل
text = re.sub(r'[ً-ْ]', '', text)
# 2. توحيد أشكال الألف إلى ألف مجردة
text = re.sub(r'[أإآ]', 'ا', text)
# 3. توحيد الياء والياء المقصورة
text = re.sub(r'ى', 'ي', text)
# 4. توحيد التاء المربوطة إلى هاء
text = re.sub(r'ة', 'ه', text)
# 5. إزالة الرموز غير العربية وعلامات الترقيم
text = re.sub(r'[^ء-ي\s]', ' ', text)
# 6. إزالة المسافات الزائدة
text = re.sub(r'\s+', ' ', text).strip()
return text
def preprocess_arabic_text(text):
# معالجة النص
normalized = normalize_arabic(text)
# تقسيم النص وإزالة كلمات الوقف ثم التجذير
words = normalized.split()
processed_words = [stemmer.stem(word) for word in words if word not in arabic_stopwords]
return " ".join(processed_words)
# مثال على الاستخدام
raw_text = "الخدمةُ كانت ممتازةً وسريعةً جداً! أنصح الجميع بالتعامل معهم."
print("الأصلي:", raw_text)
print("المعالج:", preprocess_arabic_text(raw_text))
# المخرج: ممتاز سرع نصح جمع عمل مع
الخطوة 3: تدريب مصنف بسيط
الآن، لنقوم بتمثيل النص المعالج باستخدام TF-IDF وتدريب نموذج الانحدار اللوجستي:
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import Pipeline
# بيانات التدريب التجريبية
train_sentences = [
"المنتج رائع جدا وأنصح بشرائه",
"التوصيل كان بطيئا والخدمة سيئة للغاية",
"أعجبني التطبيق وسهل الاستخدام",
"تجربة سيئة جدا ولا أنصح به أبدا",
"خدمة العملاء كانت متعاونة وممتازة"
]
# التصنيفات: 1 = إيجابي، 0 = سلبي
train_labels = [1, 0, 1, 0, 1]
# معالجة بيانات التدريب
preprocessed_train = [preprocess_arabic_text(s) for s in train_sentences]
# إنشاء مسار النموذج: متجه TF-IDF + مصنف الانحدار اللوجستي
model_pipeline = Pipeline([
('tfidf', TfidfVectorizer()),
('clf', LogisticRegression())
])
# تدريب النموذج
model_pipeline.fit(preprocessed_train, train_labels)
# اختبار النموذج بنص جديد
test_text = "التطبيق سيئ للغاية ولا يعمل بشكل صحيح"
preprocessed_test = preprocess_arabic_text(test_text)
prediction = model_pipeline.predict([preprocessed_test])[0]
print(f"نص الاختبار: '{test_text}'")
print(f"النص المعالج: '{preprocessed_test}'")
print(f"التصنيف المتوقع: {'إيجابي' if prediction == 1 else 'سلبي'}")
4. شرح عملي: التصنيف الحديث القائم على المحولات (Hugging Face)
على الرغم من أن التجذير و TF-IDF يعملان بشكل جيد للتصنيف الأساسي، إلا أنهما يفشلان في التقاط السياق والسخرية والاختلافات اللهجوية المعقدة. للحصول على أفضل النتائج، نستخدم نماذج المحولات المدربة مسبقًا مثل AraBERT أو CamelBERT.
إليك كيفية استخدام مكتبة transformers من Hugging Face لتشغيل تحليل المشاعر على النصوص العربية في أسطر برمجية قليلة فقط:
الخطوة 1: تثبيت المكتبات المطلوبة
pip install transformers torch sentencepiece
الخطوة 2: تحميل مسار النموذج
سنستخدم نموذجًا عالي الكفاءة ومحسنًا وهو CAMeL-Lab/bert-base-arabic-sentiment-msa المستضاف على منصة Hugging Face:
from transformers import pipeline
# تهيئة مسار تحليل المشاعر باستخدام نموذج عربي متخصص
arabic_sentiment_analyzer = pipeline(
"sentiment-analysis",
model="CAMeL-Lab/bert-base-arabic-sentiment-msa"
)
# جمل الاختبار (الفصحى والعامية)
sentences = [
"أنا سعيد جداً باستخدام هذا المنتج الرائع",
"الفيلم كان مملاً والقصة غير مترابطة على الإطلاق"
]
results = arabic_sentiment_analyzer(sentences)
for sentence, result in zip(sentences, results):
label = result['label']
confidence = result['score'] * 100
print(f"النص: {sentence}")
print(f"المشاعر: {label} (ثقة: {confidence:.2f}%)
")
5. مقارنة النماذج: تعلم الآلة التقليدي مقابل المحولات (Transformers)
| الميزة | تعلم الآلة التقليدي (TF-IDF + SVM/LR) | المحولات (AraBERT/CamelBERT) |
|---|---|---|
| فهم السياق | منخفض (يعامل الكلمات كميزات مستقلة) | مرتفع (يفهم ترتيب الكلمات وسياقها) |
| التعامل مع اللهجات | ضعيف (يتطلب قواميس لهجات مخصصة) | ممتاز (يتعامل مع اللهجات المعقدة بشكل طبيعي) |
| متطلبات الحوسبة | منخفضة للغاية (يعمل على أي معالج خلال أجزاء من الثانية) | عالية (يتطلب وحدة معالجة رسومية للاستدلال السريع) |
| بيانات التدريب المطلوبة | عالية (يتطلب مجموعات بيانات ضخمة معنونة للتعميم) | منخفضة (مدرب مسبقًا، ويعمل جيدًا مع الضبط الدقيق) |
| الكلمات خارج القاموس (OOV) | خطر كبير لتجاوز الكلمات الجديدة | خطر ضئيل (يستخدم التقطيع الفرعي للكلمات) |
6. خاتمة
يعد تحليل المشاعر باللغة العربية مجالاً يتطور بسرعة. في حين أن تقنيات تعلم الآلة التقليدية مع المعالجة المسبقة المخصصة (مثل التوحيد والتجذير) سريعة ومنخفضة التكلفة للمهام البسيطة، فإن نماذج المحولات الحديثة وضعت معيارًا جديدًا للدقة والتعامل مع اللهجات.
من خلال دمج قواعد التنظيف اللغوي السليمة مع بنيات النماذج الصحيحة، يمكنك بناء أنظمة قوية قادرة على استكشاف المشاعر الحقيقية في العالم العربي.
اكتشف المزيد من رؤى الذكاء الاصطناعي ومعالجة اللغة الطبيعية على مدونة Ghaznix →